
I read two really useful guides to processing text data recently; an analysis of Trump’s tweets to work out whether it’s him or an intern sending them, and a sentiment analysis of Pride and Prejudice. Three years of a long distance relationship means that I have a nice big corpus of Whatsapp messages between my girlfriend and me, so I did the romantic thing and quantified some of our interactions in R. Also, this required quite a bit of text munging in Excel first, which turned out to be far quicker and easier than using regex in this case.
First of all, let’s look at when we text each other throughout the day. We’re in different time zones, but only by an hour, and since texts are inherently dependent – one text is overwhelmingly likely to lead to another pretty soon after – I haven’t adjusted the times.

Our texting activity represents our general activity pretty well; nothing much going on until about 7am, then a slow start to the day, a bit of a post-lunch dip, and then an evening peak when we’re more likely to be out and about doing things.
We can also have a look at how many messages we send each other, and how that’s changed over time:

We’ve sent each other a fairly similar number of texts per day throughout the long distance period, but it looks pretty bad on me that I have consistently sent fewer texts than her…
…or does it? When I plot the length of each text sent, I consistently write longer messages:

So, there’s two distinct texting styles here; I write longer messages less frequently, she writes shorter messages more frequently. The other thing I like about the text length graph is that you can see the times when we’ve been together and not texted each other that much; three weeks in November 2014 when I was running experiments in London, three weeks around Christmas 2015, and a load of long weekends throughout. It’s not that we don’t text each other at all then, it’s more that those texts tend to be stuff like “have we got milk?”, or simply “pub?”.
Plotting log likelihood ratios of how much each of us uses each word in comparison to the other also captures our texting styles:
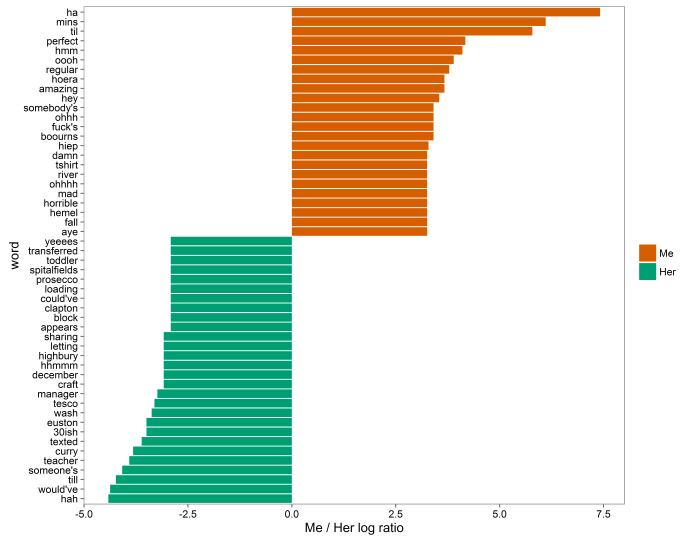
For example, we both use the word /ha/ to express laughter, but I spell it “ha” and she spells it “hah”. Likewise, “til” and “till” as abbreviations for “until”, and I seem to use “somebody” while she uses “someone”.
If we filter out equivalent words and proper names (like the pubs, supermarkets, and stations we go to most often), another difference in dialogue style appears:
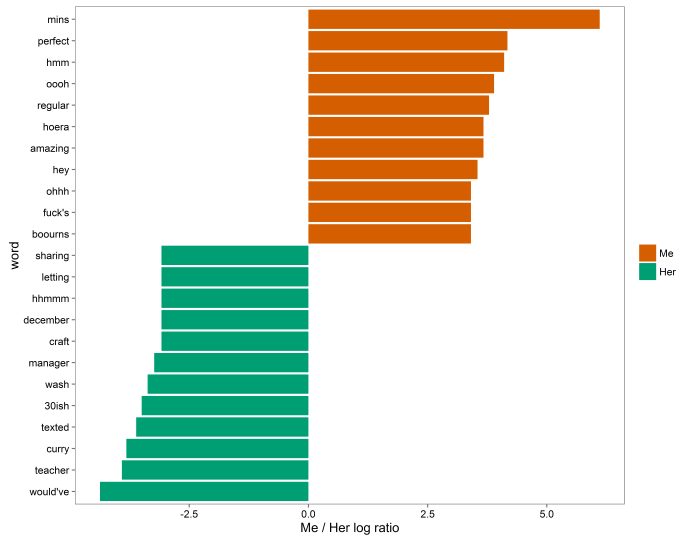
I am apparently a lot more conversational; I write out interjections (hmm, oooh, hey, ohhh) and reactions (fuck’s comes from for fuck’s sake, hoera comes from the Dutch phrase hiep hiep hoera, and boourns comes from, erm, The Simpsons). Apart from hhmmm, she doesn’t write interjections or contextual replies at all. Apart from the interjections and replies, my main thing is adjectives; she tends towards nouns and verbs.
The next step is sentiment analysis. If I plot log likelihood bars for each sentiment, I seem to be an atrociously negative person:
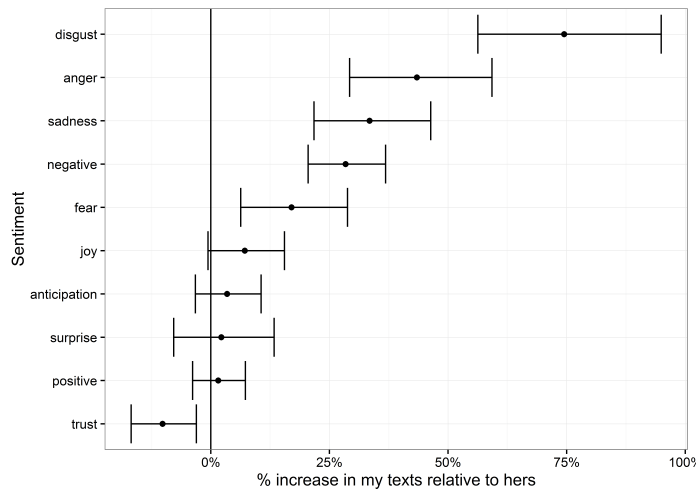
…but this, I think, is more a problem with the way sentiment analysis works in the syuzhet and tidytext packages using NRC sentiment data. Each word in the NRC corpus has a given value, 0 or 1, for a range of sentiments, and this sentiment analysis style simply adds it up for each word in a given set.
Because of that, it doesn’t really capture the actual sentiment behind the way we’re using these words. Let’s look at the main words driving the differences in each sentiment:
 For me, a lot of my disgust and anger is coming from the word damn. If I was texting damn! every time I stubbed my toe or something, perhaps that would be accurate; but in this case, a lot of the time I write damn is in sympathy, as in exchanges like:
For me, a lot of my disgust and anger is coming from the word damn. If I was texting damn! every time I stubbed my toe or something, perhaps that would be accurate; but in this case, a lot of the time I write damn is in sympathy, as in exchanges like:
“My computer crashed this afternoon and I lost all the work I’d done today”
“Damn, that’s horrible”
Meanwhile, the word coop is actually me talking about the coöp / co-op, where I get my groceries. I’m not talking about being trapped, either physically or mentally.
The same goes for my girlfriend being more positive. With words like engagement and ceremony, she’s not joyous or anticipatory about her own upcoming nuptials or anything; rather, several of her colleagues have got engaged and married recently, and most of her uses of the words engagement and ceremony are her complaining about how that’s the only topic of conversation at the office. As for assessment, council, and teacher, she works in education. These are generally neutral descriptions of what’s happened that day.
So, I was hoping to be able to plot some sentiment analyses to show our relationship over time, but either it doesn’t work for text messages, or we’re really fucking obtuse. I think it might be the former.
Instead, I’ll settle for showing how much we both swear over time:

Each dot represents the number of occurrences per month of a particular expletive. I’m clearly the more profane here, although I do waver a bit while she’s fairly consistent.
More importantly is how we talk about beer a similar amount:

Since couples who drink together stay together (or in the words of this study, “concordant drinking couples reported decreased negative marital quality over time”), I think this bodes pretty well for us.

Pingback: The Gaslight Analysis: when sentiment analysis doesn’t quite work. | Vizzee Rascal