
The original Slate article introduces this better than I can, because they’re actual journalists and I’m just a data botherer:
On Thursday morning, a federal court released a 2016 deposition given by Ghislaine Maxwell, the 58-year-old British woman charged by the federal government with enticing underage girls to have sex with Jeffrey Epstein. That deposition, which Maxwell has fought to withhold, was given as part of a defamation suit brought by Virginia Roberts Giuffre, who alleges that she was lured to become Epstein’s sex slave. That defamation suit was settled in 2017. Epstein died by suicide in 2019.
In the deposition, Maxwell was pressed to answer questions about the many famous men in Epstein’s orbit, among them Bill Clinton, Alan Dershowitz, and Prince Andrew. In the document that was released on Thursday, those names and others appear under black bars. According to the Miami Herald, which sued for this and other documents to be released, the deposition was released only after “days of wrangling over redactions.”
Slate: “We Cracked the Redactions in the Ghislaine Maxwell Deposition”
It’s some grim shit. I haven’t been following the story that closely, and I don’t particularly want to read all 400-odd pages of testimony.
But this bit caught my eye:
It turns out, though, that those redactions are possible to crack. That’s because the deposition—which you can read in full here—includes a complete alphabetized index of the redacted and unredacted words that appear in the document.
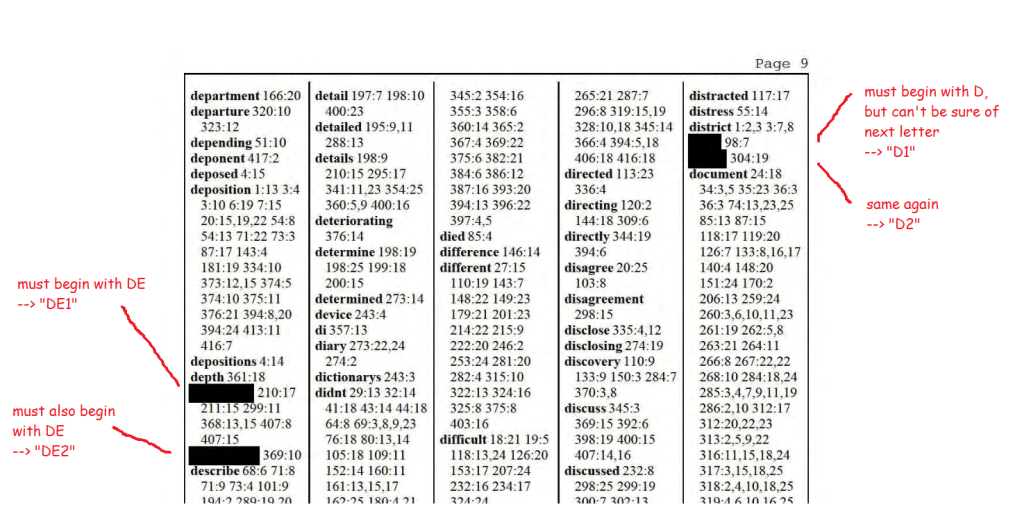
This is … not exactly redacted. It looks pretty redacted in the text itself:

Above: Page 231 of the depositions with black bars redacting some names.
But the index helpfully lists out all the redacted words. With the original word lengths intact. In alphabetical order. You don’t need any sophisticated statistical methods to see that many of the redacted black bars on page 231 concern a short word which begins with the letter A, and is followed by either the letter I or the letter L:

Above: The index of the deposition, helpfully listing out all the redacted words alphabetically anbd referencing them to individual lines on individual pages.
It also doesn’t take much effort to scroll through the rest of the index, and notice that another short word beginning with the letters GO occurs in exactly the same place:

Above: I wish all metadata was this good.
And once you’ve put those two things together, it’s not a huge leap to figure out that this is probably about Al Gore.
When I first read the Slate article on Friday 23rd October 2020, around 8am UK time, Slate had already listed out a few names they’d figured out by manually going through the index and piecing together coöccurring words. And that reminded me of market basket analysis, one of my favourite statistical processes. I love it because you can figure out where things occur together at scale, and I love it because conceptually it’s not even that hard, it’s just fractions.
Market basket analysis is normally used for retail data to look at what people buy together, like burgers and burger buns, and what people don’t tend to buy together, like veggie sausages and bacon. But since it’s basically just looking at what happens together, you can apply it to all sorts of use cases outside supermarkets.
In this case, our shopping basket is the individual page of the deposition, and our items are the redacted words. If two individual redacted words occur together on the same page(s) more than you’d expect by chance, then those two words are probably a first name and a surname. And if we can figure out the first letter(s) of the words from their positions in the index, we’ve got the initials of our redacted people.
For example, let’s take the two words which are probably Al Gore, A1 and GO1. If the redacted word A1 appears on 2% of pages, and if the redacted word GO1 appears on 3% of pages, then if there’s no relationship between the two words, you’d expect A1 and GO1 to appear together on 3% of 2% of pages, i.e. on 0.06% of pages. But if those two words appear together on 1% of pages, that’s ~16x more often than you’d expect by chance, suggesting that there’s a relationship between the words there.
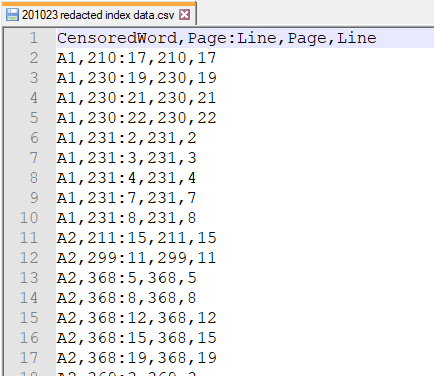
So, I opened up the Maxwell deposition pdf, which you can find here, and spent a happy Friday evening going through scanned pdf pages (which are the worst, even worse than the .xls UK COVID-19 test and trace debacle, please never store your data like this, thank you) and turning it into something usable. Like basically every data project I’ve ever worked on, about 90% of my time was spent getting the data into a form that I could actually use.

oh god why
Working through it…
How data should look.
And now we’re ready for some stats. I used Alteryx to look at possible one-to-one association rules between redacted words. Since I don’t know the actual order of the redacted words, there are two possible orders for any two words: Word1 Word2 and Word2 Word1. For example, the name that’s almost definitely Al Gore is represented by the two words “A1” and “GO1” in my data. If there’s a high lift between those two words, that tells me it’s likely to be a name, but I’m not sure if that name is “A1 GO1” or “GO1 A1”.
After running the market basket analysis and sorting by lift, I get these results. Luckily, Slate have already identified a load of names, so I’m reasonably confident that this approach works:
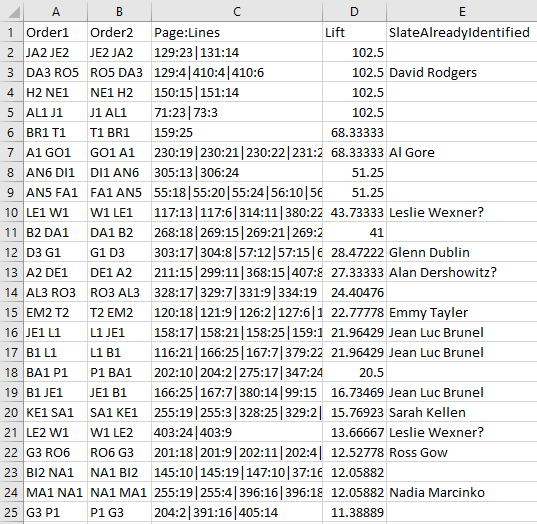
A list of initials and names, in Excel this time to make it more human-readable.
Like I said, I haven’t been following this story that closely, and I’m not close enough to be able to take a guess at the names. But I’m definitely intrigued by the top one – Slate haven’t cracked it as of the time of writing. The numbers suggest that there’s somebody called either Je___ Ja___ or Ja___ Je___ who’s being talked about here:

Je___ Ja___ or Ja___ Je___?
I don’t particularly want to speculate on who’s involved in this. It’s a nasty business and I’d prefer to stay out of it. But there are a few things that this document illustrates perfectly:
- It’s not really redacted if you’ve still got the indexing, come on, seriously
- Even fairly simple statistical procedures can be really useful
- Different fields should look at the statistical approaches used in other fields more often – it really frustrates me that I almost never see any applications of market basket analysis outside retail data
- Please never store any data in a pdf if you want people to be able to use that data

r
LikeLike