[I originally wrote this as a guest blog for My Scholarly Goop, I’m now crossposting to my own blog]
I used to be jealous of my friend Dave when we were at school. He’s wanted to be a doctor ever since he can remember, and that gave purpose to everything he did. We’d be in a chemistry lesson, and he’d be listening intently, even though he knew the topic, and he knew that he knew the topic, because a mastery of chemistry would be the foundation of the rest of his career. He wouldn’t let losing focus on a dull Tuesday afternoon potentially jeopardise his university applications a few years down the line. I’d be sitting next to him, quietly filling out the sudoku I ripped out of the newspaper in the library.
I envied his sense of purpose and direction. Our lives looked a bit like this:

But in time, I grew a lot less jealous, and embraced my lack of direction. There’s something liberating about not being focused on any particular thing; it gives you room to explore all the spaces in between.
My academic career veered from Japanese to linguistics to cognitive neuroscience, with a smattering of international relations, public policy, and statistics. Along the way, I worked in various jobs in financial software consultancy, accounting, commercial law, translation, and selling dog food. I’m now a data scientist, and I’ve done projects with a Premiership football team, an auction house, a scientific research funding body, a cargo company, and two different medical charities. I’m currently on a six-month placement with Solar Turbines, working on making huge turbine engines more efficient and reliable. I haven’t followed a path so much as got lost in the forest, and I’ve thoroughly enjoyed taking in all the trees.
Now, if you’re like my friend Dave, then great! You know what your goal is, and you’re probably doing what you need to do to get there. But if you’re reading a blog about post-PhD career paths, you’re probably a bit more like me. It’s exciting, because you can do anything! But it’s also overwhelming, because you should consider everything.
Writing about the joys of not having goals may sound flippant, but aimlessly wandering successfully takes a lot of effort. To put it in context, this is what my summer in 2016 looked like:
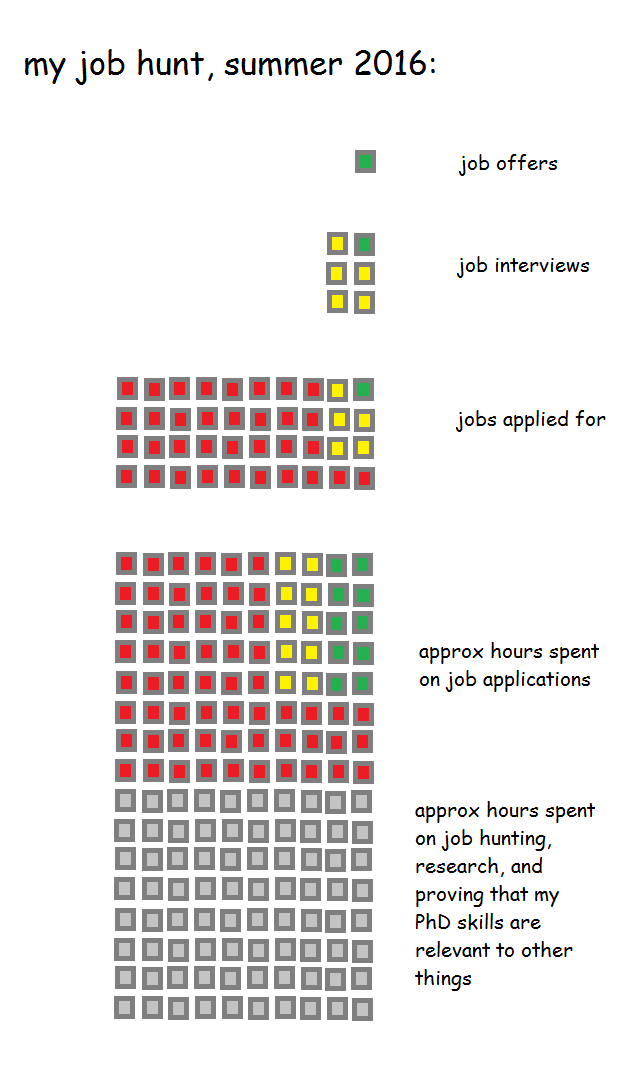
I applied for something like 35 or 40 jobs in various fields, I went to six interviews, and I received one job offer (I withdrew from another two interviews before attending, because I’d have taken my current job at The Information Lab even if I’d been offered any of the others). Each job application took a good two hours or so to write, so that’s maybe eighty hours of work. The job application process for The Information Lab meant I had to download and learn a new bit of software, so I probably spent at least ten hours on that application alone.
But just the hours spent applying for jobs wasn’t enough. My PhD was about how special kinds of onomatopoeic words might or might not be related to multisensory processing and perhaps synaesthesia… and that’s the general summary version. PhD research is highly specific, which also means it’s highly irrelevant to most non-academic jobs. When you talk about your PhD, this is what you think you’re saying, and how it compares to what most people hear:

Unlike the content of your PhD itself, the wider skills you learn are valuable, widely transferable, and highly sought. However, it’s your responsibility to show this to people. You could be a brilliant analyst, but nobody’s going to listen if you only talk about your skills in the context of your research. So, for every two hours or so I spent on a particular job application, I probably spent another two hours creating a portfolio on my blog. I used my coding, statistical, and data visualisation skills to play with various different data sources, such as looking at how the gender gap in GCSE results in England corresponds to various measures of how “good” a school is, or looking at football stats to show that the 2016 Portugal side are the worst winners of a European Championship. This took a lot of time and effort, but every single organisation that invited me to an interview said that it was this portfolio of work on my blog that had got me there. Not my PhD work.
This means that I spent about 160 hours, or twenty eight-hour days, or just under one working month, on getting one job offer. This probably sounds quite daunting. And yeah, it is. Getting a job outside academia was like writing an extra chapter for my PhD.
But the good news is that while it might be hard work, it won’t be wasted work. I’ve spoken to a fair few PhD students looking for a career outside academia, and I think a lot of people fall into a zone of self-defeat; they’re more than qualified for the jobs they’re applying for, but they undersell themselves because they’ve spent years surrounded by frighteningly competent people during their PhDs and only see themselves in relative terms. I felt like this for a long time myself, and it takes a while to get out of this mindset. I think academia does this to people’s perceptions of themselves:

All this means is that academia itself is probably the biggest obstacle to getting a job outside academia. Take the time to research different careers, different people, different ideas; once you can frame your skills and abilities independently of your own research, you’re halfway there.
If you’re considering a career outside academia, you’re already far more qualified than you think you are, you’ve got more to offer than you think you do, and you can be far more than you think you can. But it’s up to you to prove it.