I have a new article out!
Gwilym Lockwood, Mark Dingemanse, and Peter Hagoort. 2016. “Sound-Symbolism Boosts Novel Word Learning.” Journal of Experimental Psychology: Learning, Memory, and Cognition. doi:10.1037/xlm0000235 (download link, go on, it’s only eight pages)
and I’m particularly proud of this one because:
a) it’s a full article discussing some of the stats I’ve been talking about at conferences for almost two years, and
b) it’s probably the only scientific article to formally cite Professor Oak’s Pokédex.


So, if you like things like iconicity and logit mixed models and flawed experiments cunningly disguised as pre-tests that I meant to do all along, you can read it here.
Enough of that, though. I know that what you’re really here for is Sound-symbolism boosts novel word learning: the MS Paint version.
The first thing we did was to select our words from almost a hundred ideophones and arbitrary adjectives. Participants heard the Japanese word, then saw two possible translations – one real, one opposite – and they had to guess which the correct one was. This was pretty easy for the ideophone task. People can generally guess the correct meaning with some certainty, because it just kind of sounds right for one of the options (due to the cross-modal correspondences between the sound of the word and its sensory meaning). It was a fair bit harder for the arbitrary adjectives, where there are no giveaways in the sound of the word.

It’s kind of taken for granted in the literature that people can guess the meanings of ideophones at above chance accuracy in a 2AFC test, but I’ve always struggled to find a body of research which shows this. This pre-test shows that people can indeed guess ideophones at above chance accuracy in a 2AFC test – at 63.1% accuracy (μ=50%, p<0.001) across 95 ideophones, in fact. So, now, anybody who wants to make that claim has the stats to do so. Nice. We’re now rerunning this online with thousands of people as part of the Groot Nationaal Onderzoek project, so stay tuned for more on that.
Then, two different groups did a learning task. We originally had the learning task as a 2AFC set up where participants learned by guessing and then getting feedback. In terms of results, this did work… but about a third of the participants realised that they could “learn” by ignoring the Japanese words completely and just remembering to pick fat when they saw the options fat and thin. Damn.

Anyway. We got two more groups in to do separate learning and test rounds with a much better design. One group got all the ideophones, half with their real meanings, half with their opposite meanings. The other group got all the arbitrary adjectives, half with their real meanings, half with their opposite meanings.
In the same way that it’s easy to guess the meanings of the ideophones, we predicted that the ideophones with their real translations would be easy to learn because of the cross-modal correspondences between linguistic sound and sensory meaning…

…that the ideophones with their opposite translations would be hard to learn, because the sounds and meanings clash rather than match…

…and that there wouldn’t be much difference between conditions for the arbitrary adjectives, because there’s no real association between sound and meaning in arbitrary words anyway.
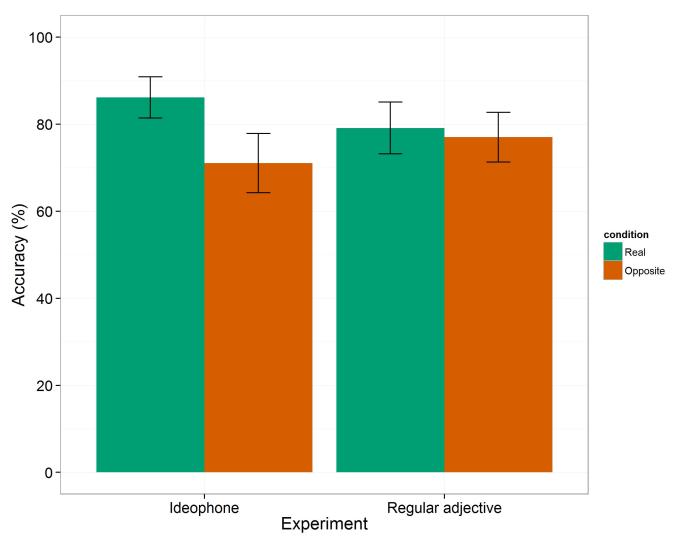
And sure enough, that’s exactly what we found. Participants were right 86.1% of the time for ideophones in the real condition, but only 71.1% for ideophones in the opposite condition. With the arbitrary adjectives, it was 79.1% versus 77%, which isn’t a proper difference.
Additional bonus for replication fans! (that’s everybody, right?): in a follow-up EEG experiment doing this exact same task with Japanese ideophones, another 29 participants got basically the same results (86.7% for the real condition, 71.3% for the opposite condition). That’s going to be submitted in the next couple of weeks.
Here’s the histogram from the paper… but in glorious technicolour:
(It would have cost us $900 to put one colour figure in the article, even though it’s the publisher who’s printing it and making money from it. The whole situation is quite silly.)
The point of this study is that it’s easier to learn words that sound like what they mean than words that don’t sound like what they mean, and that words that don’t particularly sound like anything are somewhere in the middle. This seems fairly obvious, but people have assumed for a long time that this doesn’t really happen. There’s been a fair bit of research about onomatopoeia and ideophones helping babies learn their first language, but not that much yet about studies with adults. It also provides some support for the broader suggestion that we use similar sounds to talk about and understand sensory things across languages, but not so much for other things, so words with sound-symbolism may well have been how language started out in the first place.
I’d love to re-run this study on a more informal (and probably unethical) basis where a class of school students learning Japanese are given a week to learn the same word list for a vocab test where they’d have to write down the Japanese words on a piece of paper. I reckon that there’d be the same kind of difference between conditions, but it’d be nice to see that happen when they really have to learn the words to produce a week later, not just recognise a few minutes later. If anybody wants to offer me a teaching position at a high school where I can try this out and probably upset lots of parents, get in touch; I need a job when my PhD contract runs out in August.
The thing I find funniest about this entire study is that when I was studying Japanese during my undergrad degree, I found ideophones really difficult to learn. I thought they all sounded kind of the same, and pretty daft to boot. The ideophone for “exciting/excited” is wakuwaku, which I felt so uncomfortable saying that I feigned indifference about things in oral exams to avoid saying it (but to be fair, feigned indifference was my approach to most things in my late teens and early twenties). There’s probably an ideophone to express the internal psychological conflict you get when you realise you’re doing a PhD in something you always tried to ignore during your undergrad degree, but I’m not sure what it is. I’ll bet my old Japanese lecturers would be pretty niyaniya if they knew, though.