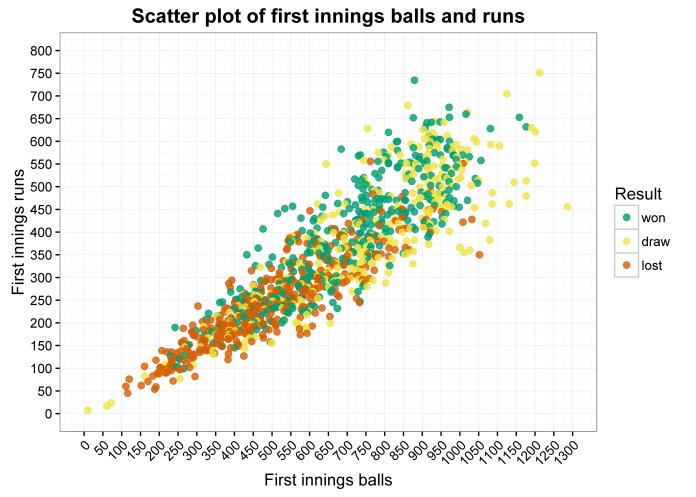
I was looking at the Premiership league table today, and it looks like this:

It’s pretty informative; we can see that Leicester are top, Aston Villa are bottom, and that the rest of the teams are somewhere in between. If we look at the points column on the far right, we can also see how close things are; Villa are stranded at the bottom and definitely going down, Leicester are five points clear, and there’s a close battle for the final Champions League spot between Manchester City, West Ham, and Manchester United, who are only separated by a single point.
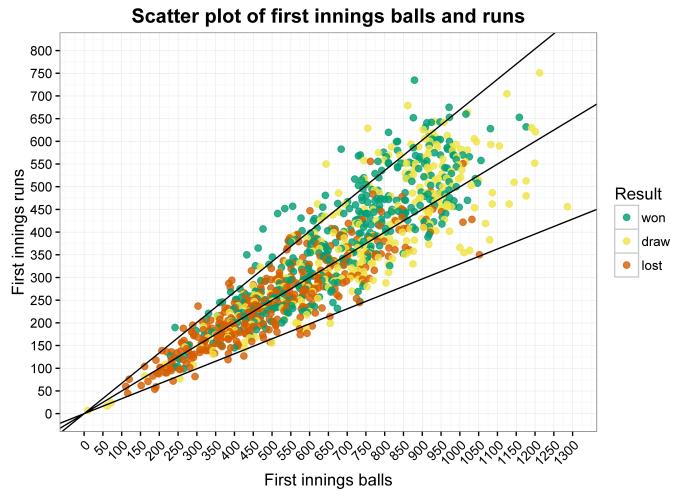
Thing is, that requires reading the points column closely. If you take the league table as a simple visual guide, it doesn’t show the distribution of teams throughout the league very well. If you say that Stoke are 8th, that sounds like a solid mid-table season… but what it doesn’t tell you is that Stoke are as close to 4th place and the Champions League as they are to 10th place, which is also solid mid-table. A more visually honest league table would look something a little like this*:

*definitely not to scale.
Screen-shotting a webpage and dragging things about in MS Paint isn’t the best way to go about this, so I’ve scraped the data and had a look at plotting it in R instead.
Firstly, let’s plot each team as a coloured dot, equally spaced apart in the way that the league table shows them:
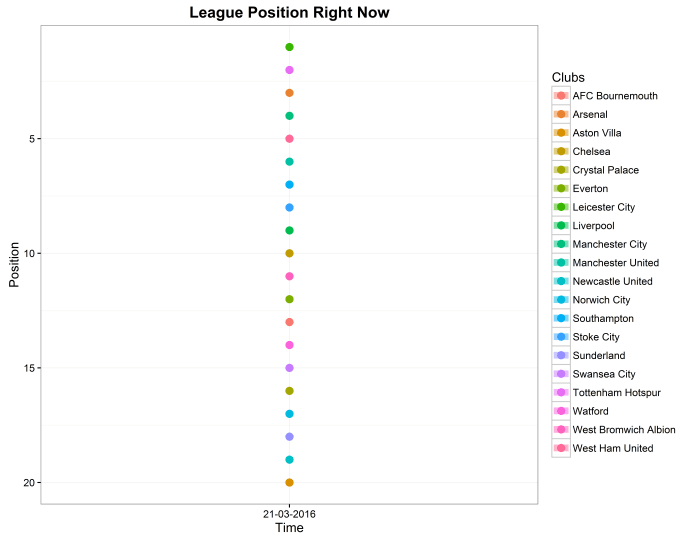
(colour-coding here is automatic; I tried giving each point the team home shirt colours, but just ended up with loads of red, blue, and white dots, which was actually a lot worse)
Now, let’s compare that with the distribution of points to show how the league positions are distributed. Here, I’ve jittered them slightly so that teams with equal points (West Ham and Manchester United in 5th and 6th, Everton and Bournemouth in 12th and 13th) don’t overlap:

This is far more informative. It shows just how doomed Aston Villa are, and shows that there’s barely any difference between 10th and 15th. It also shows that the fight for survival is between Norwich, Sunderland, and Newcastle, who are all placed closely together.
Since the information is out there, it’d also be interesting to see how this applies to league position over time. Sadly, Premiership matches aren’t all played at 3pm on Saturday anymore, they’re staggered over several days. This means that the league table will change every couple of days, which is far too much to plot over most of a season. So, I wrote a webscraper to get the league tables every Monday between the start of the season and now, which roughly corresponds to a full round of matches.
Let’s start with looking at league position:

This looks more like a nightmare tube map than an informative league table, but there are a few things we can pick out. Obviously, there’s how useless Aston Villa have been, rooted to the bottom since the end of October. We can also see the steady rise of Tottenham, in a dashing shade of lavender, working their way up from 8th in the middle of October to 2nd now. Chelsea’s recovery from flirting with relegation in December to being secure in mid-table now is fairly clear, while we can also see how Crystal Palace have done the reverse, plummeting from 5th at the end of the year to 16th now.
An alternative way of visualising how well teams do over time is by plotting their total number of points over time:
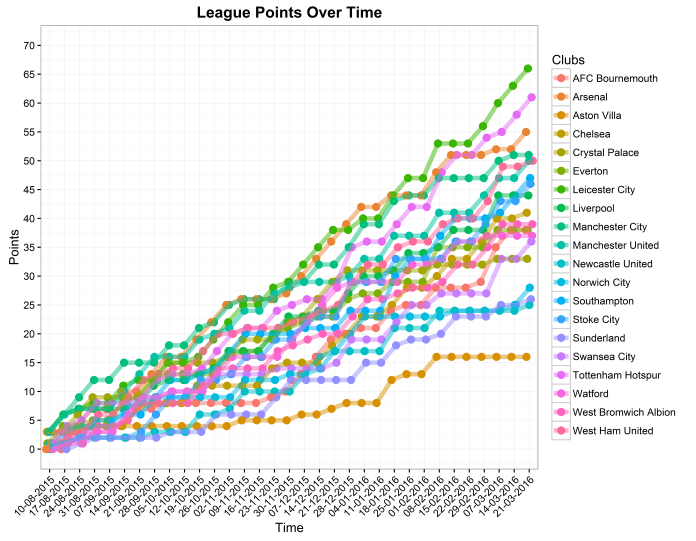
This is visually more satisfying than looking at league position over time, as we can see how the clusters of teams in similar positions have formed. Aston Villa have been bottom since October, but they were at least relatively close to Sunderland even at the end of December. Since then, though, the gap between bottom and 19th as opened up to nine points. We can also see how Leicester and Arsenal were neck and neck in first and second for most of the season, but the moment when Leicester really roared ahead was in mid-February. Finally, the relegation fight again looks like it’s a competition between Norwich, Sunderland, and Newcastle for 17th; despite Crystal Palace’s slump, the difference between 16th and 17th is one of the biggest differences between consecutive positions in the league. This is because Norwich, Sunderland, and Newcastle haven’t won many points recently, whereas Swansea and Bournemouth, who were 16th and 15th and also close to the relegation zone back in February, have both had winning streaks in the last month.
One of the drawbacks with plotting points over time is that, for most of the early part of the season, teams are so close together that you can’t really see the clusters and trends.
So, we can also calculate a ratio of how many points a team has compared to the top and bottom team at any given week. To do this, I calculated the points difference between top and bottom teams each week, and then calculated every team’s points as a proportion of where they are.
For example, right now, Leicester have 66 points and Aston Villa have 16. That’s a nice round difference of 50 points across the whole league. Let’s express that points difference on a scale of 0 to 1, where Aston Villa are at one extreme end at 0 and Leicester are at the other extreme end at 1.
Tottenham, in 2nd, have 61 points, or five points fewer than Leicester and 45 points more than Aston Villa. This means that, proportionally, they’re 90% along the points difference spectrum. This means they get a relative position of 0.9, as shown below:
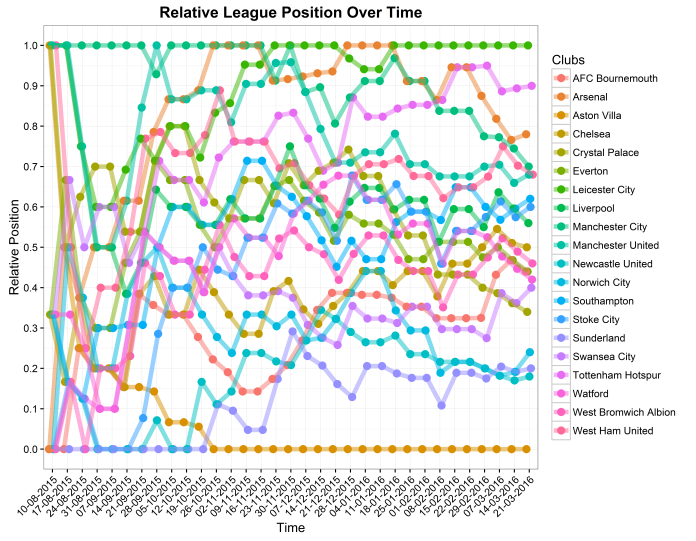
This is a lot more complicated, and perhaps needlessly so. It reminds me more of stock market data than a football league table. I plotted it this way to be able to show how close or far teams were from each other in the early parts of the season, but even then, the lines are messy and all over the place until about the start of October, when the main trends start to show. One thing that means is that however badly your team are doing in terms of points and position, there’s little use in sacking a manager before about November; there’s not enough data, and teams are too close together, to show whether it’s a minor blip or a terminal decline. Of course, if your team are doing badly in terms of points and position and playing like they’ve never seen a football before, then there’s a definite problem.
To make it really fancy/silly (delete as appropriate), I’ve plotted form guides of relative league position over time. Instead of joining each individual dot each week as above, it smooths over data points to create an average trajectory. At this point, labelling the relative position is meaningless as it isn’t designed to be read off precisely, but instead provides an overall guide to how well teams are doing:

Here, the narratives of each team’s season are more obvious. Aston Villa started out okay, but sank like a stone after a couple of months. Sunderland were fairly awful for a fairly long time, but the upswing started with Sam Allardyce’s appointment in October and they’ve done well to haul themselves up and into contention for 17th. Arsenal had a poor start to the season, then shot up, rapidly to first near the end of the year, but then they did an Arsenal and got progressively worse from about January onwards. Still, their nosedive isn’t as bad as Manchester City’s; after being top for the first couple of months, they’ve drifted further and further down. It’s more pronounced since Pep Guardiola was announced as their next manager in February, but they were quietly in decline for a while before that anyway. Finally, looking at Chelsea’s narrative line is interesting. While they’ve improved since Guus Hiddink took over, their league position improvement is far more to do with other teams declining over the last couple of months. Four teams (Crystal Palace, Everton, Watford, and West Brom) have crossed Chelsea’s narrative line since February.
I don’t expect these graphs to catch on instead of league tables, but I definitely find them useful for visualising how well teams are doing in comparison to each other, rather than just looking at their position.