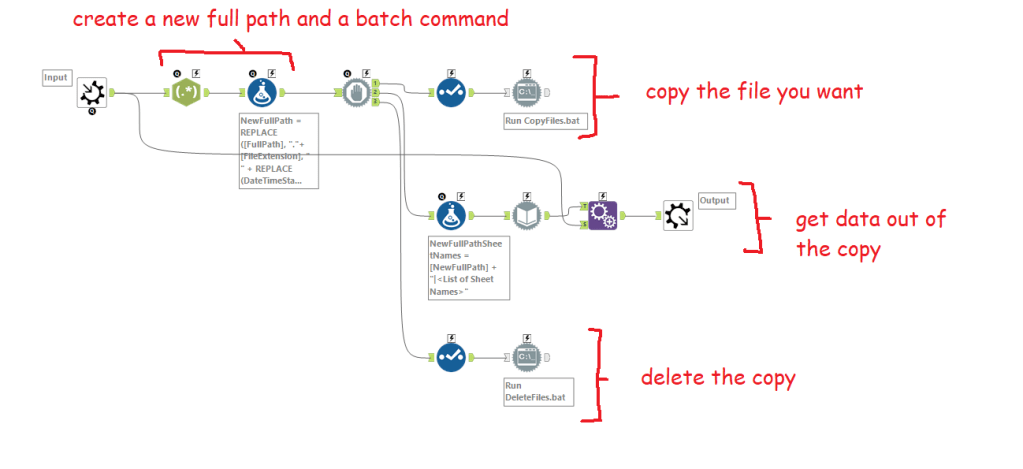
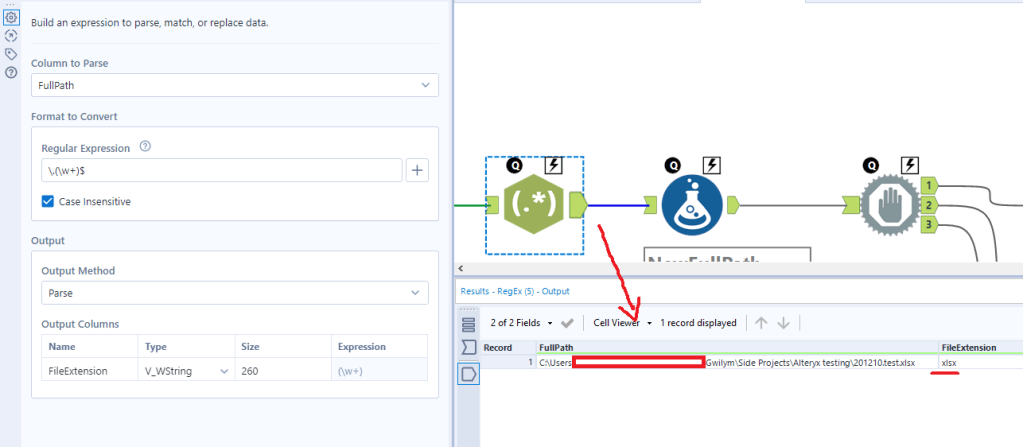
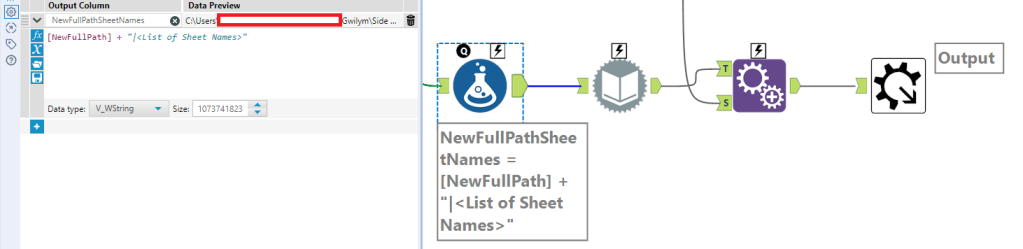
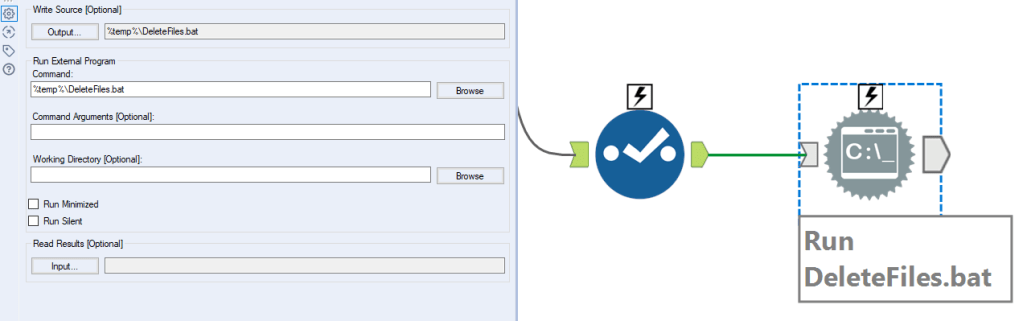
First things first – keeping and updating important data in an Excel file is not a good idea. There’s a massive risk of human error, which is why there’s a whole industry of information management tools that do a much better job at it.
But sometimes it’s inevitable, and you’ll end up with a situation where a file called CrucialInformation.csv or something like that is feeding into all kinds of different systems, meaning that it’s now a production file that other things depend on. And maybe you’re the person who’s been given the responsibility of keeping it updated. The data person at your job has said “this file is really important, make sure you don’t accidentally put wrong information in or delete anything out of it because then everything will break, okay, have fun, bye!”, and left you to it.
So, how do you responsibly manage a production csv file without breaking things and while minimising mistakes?
In this example, let’s say we work for a shop that sells food items, and the government has introduced new restrictions around items with the ingredient madeupylose in them. Items with high levels of madeupylose can only be sold to over 18s from behind the counter with the cigarettes, items with medium levels of madeupylose can be sold to over 18s from the normal shelves, and items with low levels of madeupylose can be sold to anybody as normal. This isn’t one of the main ingredients that we track in the proper systems yet, so while the data team are working on getting this set up in the databases, we need to manually track which items have madeupylose in them as a short-term solution.
(just to be explicit, this is a completely made-up ingredient in a completely made-up example! but I do use this approach for making targeted updates to large files)
We’ve got a production file called MadeupyloseItems.csv which stores the data, and it looks like this:
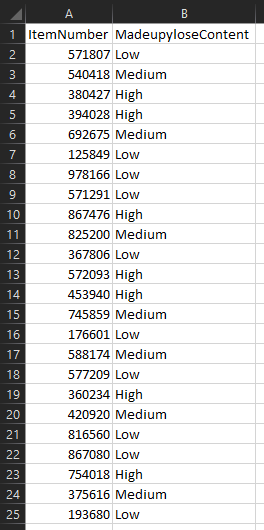
Let’s go through how to make controlled updates to this file and not break everything.
Step 1: don’t even touch it, just make copies
First of all, the safest thing to do is to pretty much never touch the production file. Firstly, because having a file open will lock it, so any background process that’s trying to access the data inside it won’t be able to. Secondly, because creating copies means we can have an archive and muck about with things safe in the knowledge that we won’t mess it up.
Wherever the production file is saved, I generally create a folder called “_archive”:

I do all the actual work on files saved in here, and almost never touch the file itself. Let’s have a look at what’s already in there:

There are two archived, datestamped files in there already – the csv from 12th September 2022, and a copy of the live production file with the datestamp from when it was last saved. It’s important to keep them there just in case I make a mistake and need to restore an old version.
There’s also the Madeupylose updater file, which I use to make my updates.
Step 2: create a totally separate Excel file to manage changes
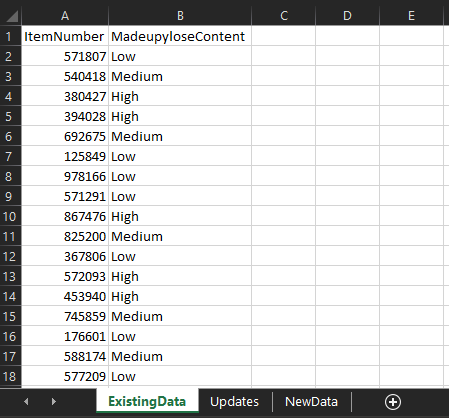
I use a dedicated Excel file to manage the changes I make to production csv files. In the first tab, I copy/paste all the data from the most recent file – in this case, I’ve copy/pasted it out of the 220914 Madeupylose.csv file in the _archive folder so I don’t have to open the live file:
In the next tab, I make my actual changes. I’ve got some items that I’m adding in and some items that I’m recategorising:
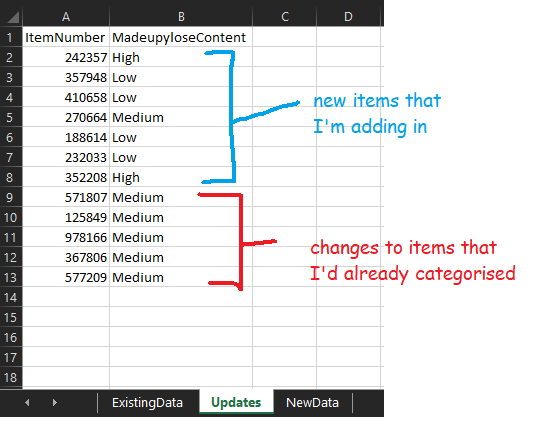
I can use this file to add in some checks – for example, have I spelled “High”, “Medium”, and “Low” correctly? Are they all the same format? There are loads of things you could do here, like sticking a filter on to check individual values, making sure that there are no duplicates, and so on.
Once I’m happy with my updates, I now need to add them to the production file somehow. I could potentially just open the file and add them in… but that would involve opening the file, for a start, and maybe disrupting another process. And it’s not just a case of adding them in – I could simply copy/paste the new items, but I’d have to find the already-categorised items and have to change them, which would be quite easy to make a mistake on (and I really don’t want to hit CTRL+F a load of times).
So, this is where I create a third tab called New Data and use a couple of xlookups.
Step 3: xlookups
If you haven’t come across xlookups before, they’re just like vlookups but simpler and better.
Firstly, I’m going to create a new column in the ExistingData tab, and I’ll use this formula:
=XLOOKUP(ExistingData!A2, Updates!A:A, Updates!A:A)
What this does is take the item number in the existing data tab, look for it in the updates tab, and if it finds it in the updates tab, it’ll return that number. If it doesn’t find it, it gives me an #N/A value:

What this means is that I can distinguish between the items that have already been categorised that I’ve changed and the ones that I haven’t. I know that anything with an #N/A value in the lookup column is an item that I haven’t changed at all. So, I can add a filter to the lookup column, and select only the #N/A values:

I’ll copy/paste columns A and B for these items into the NewData tab. Then, I’ll copy/paste columns A and B for all items in the Updates tab into the NewData tab underneath (and remember to remove the headers!). Now, I’ve got the full information in one place:

What I like about this approach is that it works the same whether you’re updating 20 records or 20,000 records – once you’ve made your updates in the updates tab, the xlookups to get it all transferred over only take seconds, and you can be sure that you’ve definitely got all the things you need in the NewData tab.
Step 4: update the production file
We’re now ready to update the production file. I prefer to take an extra step to create a whole new csv and never actually touch the production file. So, I’m going to take everything in the NewData tab, copy/paste it into a new file, and save that as a csv called “220916 MadeupyloseItems.csv” in the _archive folder:
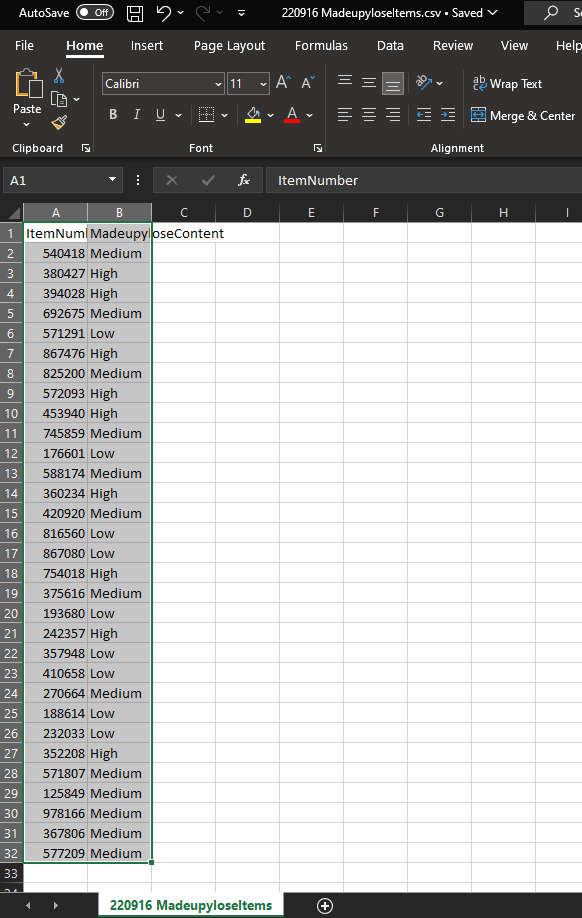

We’ve got the archived version of the current file – it’s the one from 220914, so there’s a backup in case I’ve messed up the latest update somehow. We’ve also got the archived version of the new file that I want to be the production file. The final step is to move that into production by overwriting the production file. That’s as simple as going back to the 220916 MadeupyloseItems.csv file in Excel, hit Save As, and overwrite the live file:

And there we have it! We’ve updated the live production file without even touching it, we’ve carefully tracked which lines we’re adding in and which lines we’re changing, and we’ve got a full set of backups just in case.