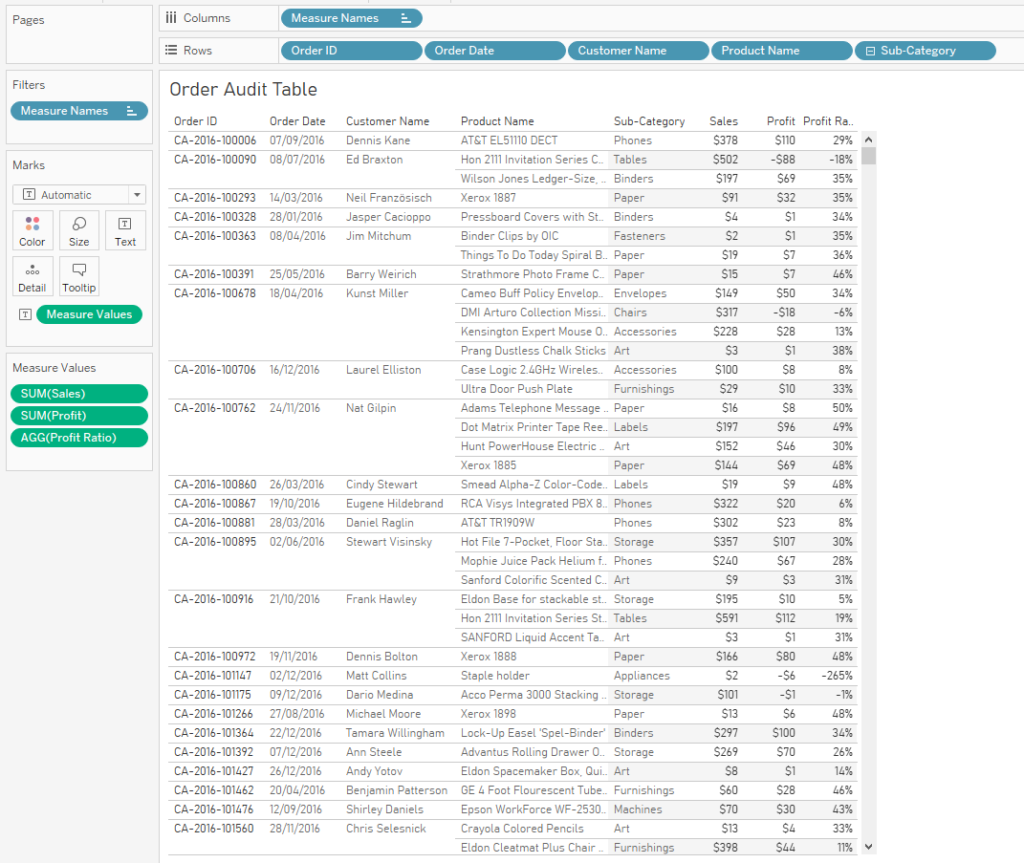
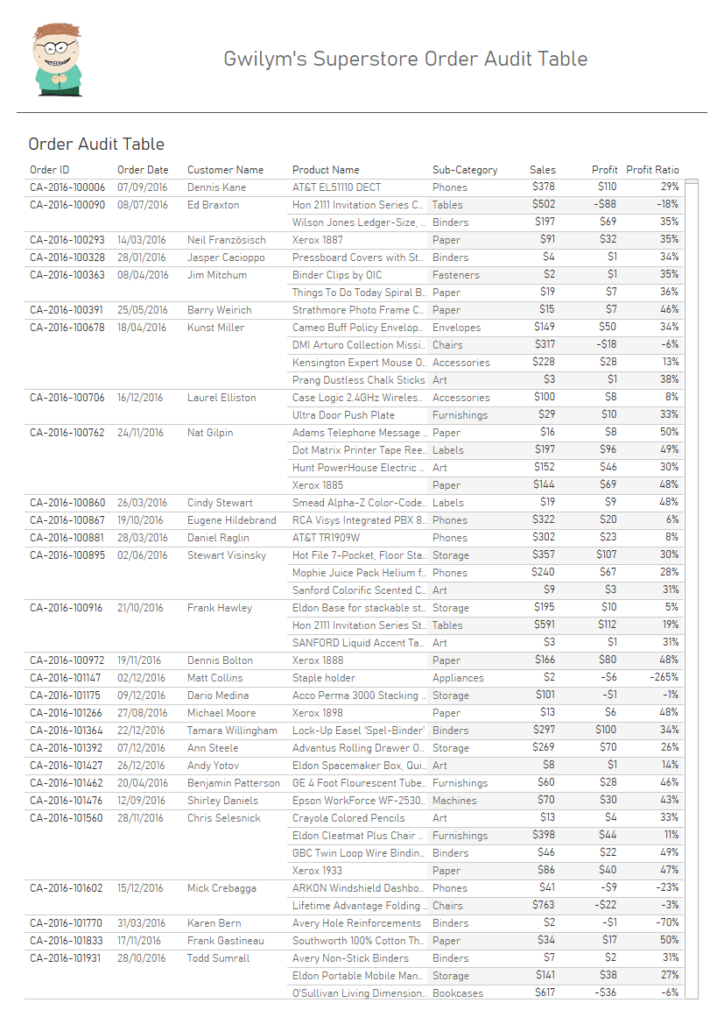
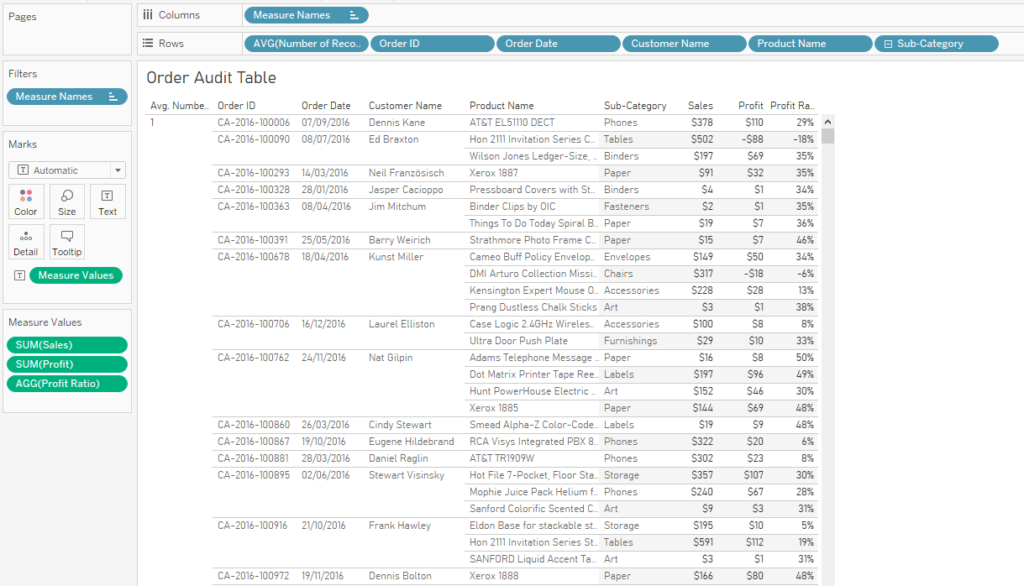
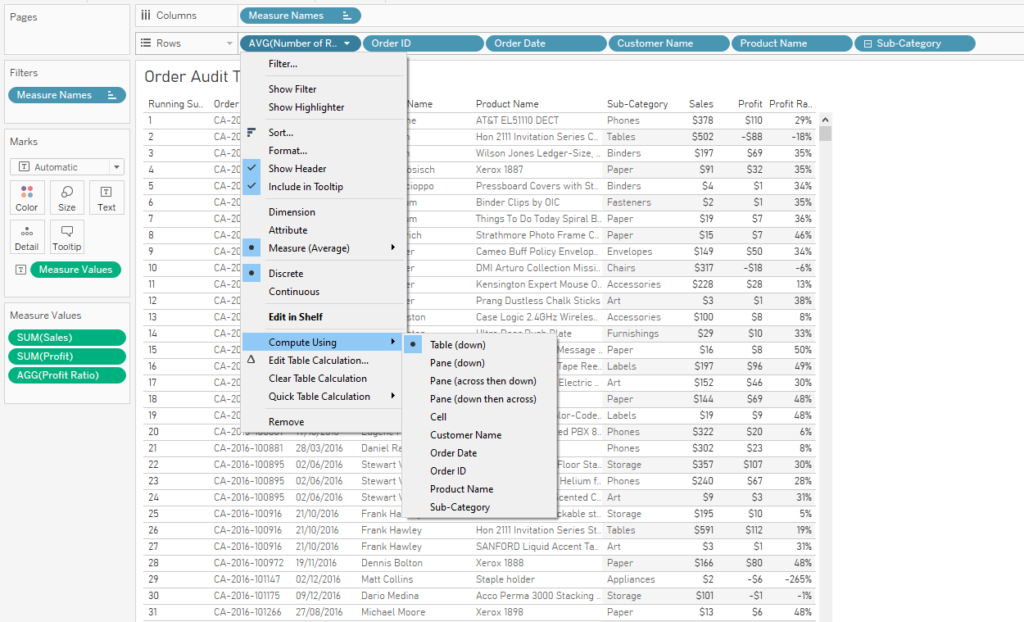
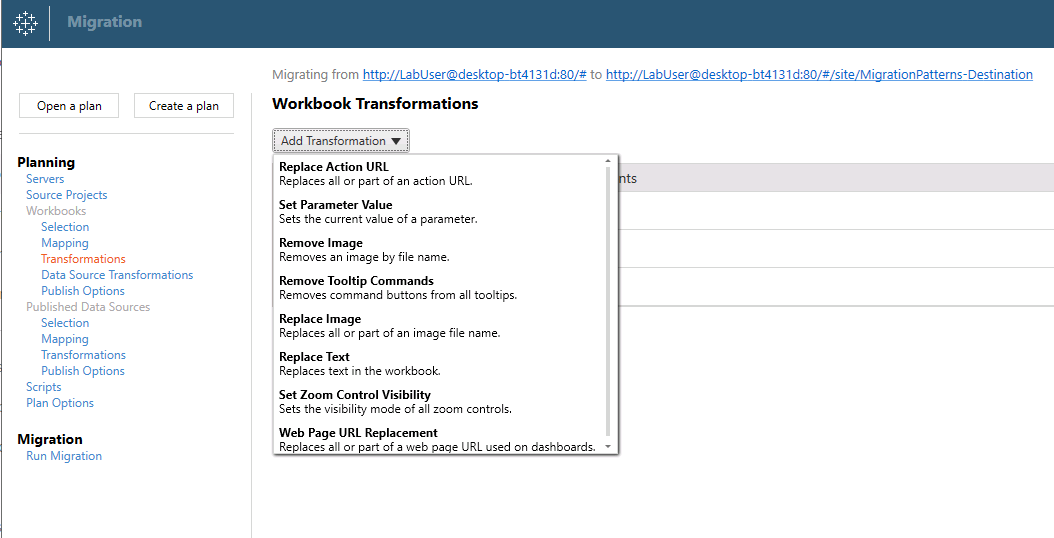
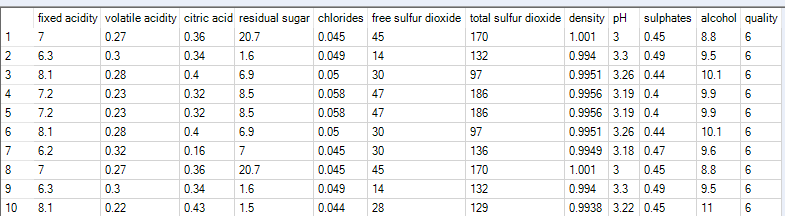Here’s a quick Tableau tip I’ve used a fair bit lately. It’s a really simple one but I haven’t seen it blogged about before – apologies if you’ve written about it and I’ve unintentionally ripped you off.
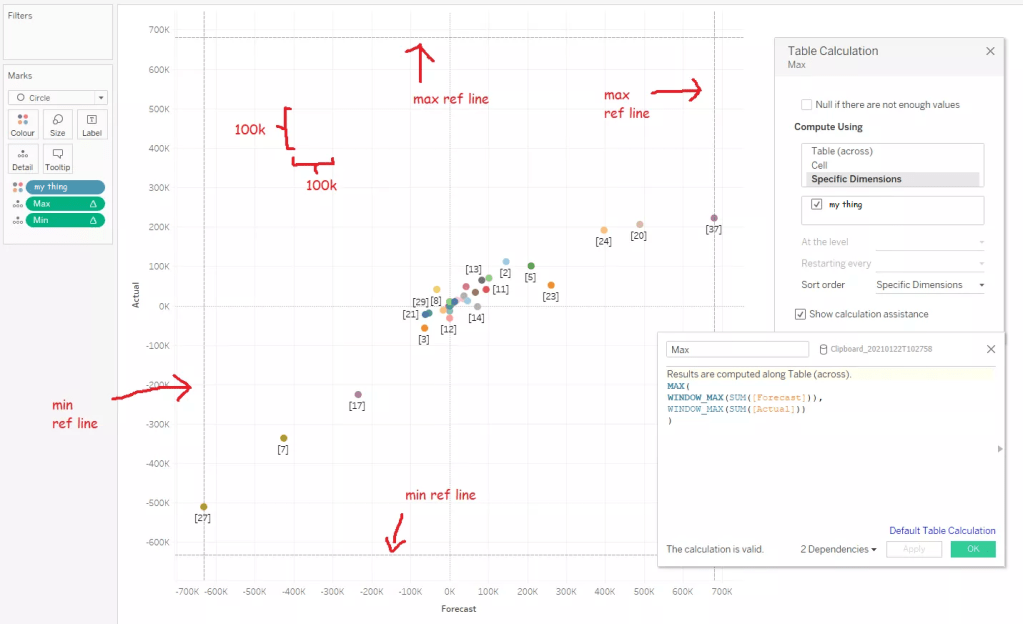
When Tableau creates a scatterplot, it automatically sizes the axes to the extent of the data. That’s often exactly how I want it to look, but sometimes, it’s not. For example, in this situation, I’m comparing a forecast I made with the actuals, and the different axis scaling makes my forecast look better than it is:
I want to get around that – instead of Tableau fitting the two axis scales to the data available, I want to force Tableau to fit the two axis scales to fit each other, giving me an equal scale on both axes. I can do this with two calculations and four reference lines, which is a little more effort than just fixing my axes, but it’s also a lot more robust than fixing my axes, which isn’t dynamic.
The max calc finds the window_max of the measures on each axis, and then finds the max of that. In my case, this is SUM([Forecast]) and SUM([Actual]), which you can switch out for whatever your measure is. Basically, it means “what’s the point with the highest value on either axis?”. The min calc does the same thing but with the min of the two window_mins.
That returns the highest and lowest value across both axes. You can then put those on each axis as four reference lines – take the max of the max calc and the min of the min calc on each axis – and then make the reference lines invisible.
And that’s it! A perfectly square scatterplot with the same scale on both axes. If you’re putting it in a dashboard, make sure to fix the sheet size so that it’s square there too.
Survival analysis is a way of looking at the time it takes for something to happen. It’s a bit different from the normal predictive approaches; we’re not trying to predict a binary property like in a logistic regression, and we’re not trying to predict a continuous variable like in a linear regression. Instead, we’re looking at whether or not a thing happens, and how long it might take that thing to happen.
One use case is in clinical trials (which is where it started, and why it’s called survival analysis). The outcome is whether or not a disease kills somebody, and the time is the time it takes for it to happen. If a drug works, the outcome will happen less often and/or take longer. Cheery stuff.
In the non-clinical world, it’s used for things like customer churn, where you’re looking at how long it takes for somebody to cancel their subscription, or things like failure rates, where you’re looking at how long it takes for lightbulbs to blow, or for fruit to go bad.
This is a long blog (a really long blog) that’ll cover the principles of survival analysis, how to do it in Alteryx, and how to visualise it in Tableau. Feel free to skip ahead to whichever section(s) you fancy. I could have split it up into several different ones, but one of my bugbears as a blog reader is when everything isn’t in one place and I have to skip from tab to tab, especially if blog part 1 doesn’t link to blog part 2, and so on. So, yeah, it’s a big one, but you’ve got a CTRL key and an F key, so search away for whatever specific bit you need.
Principles of survival analysis
Survival curves, or Kaplan-Meier graphs
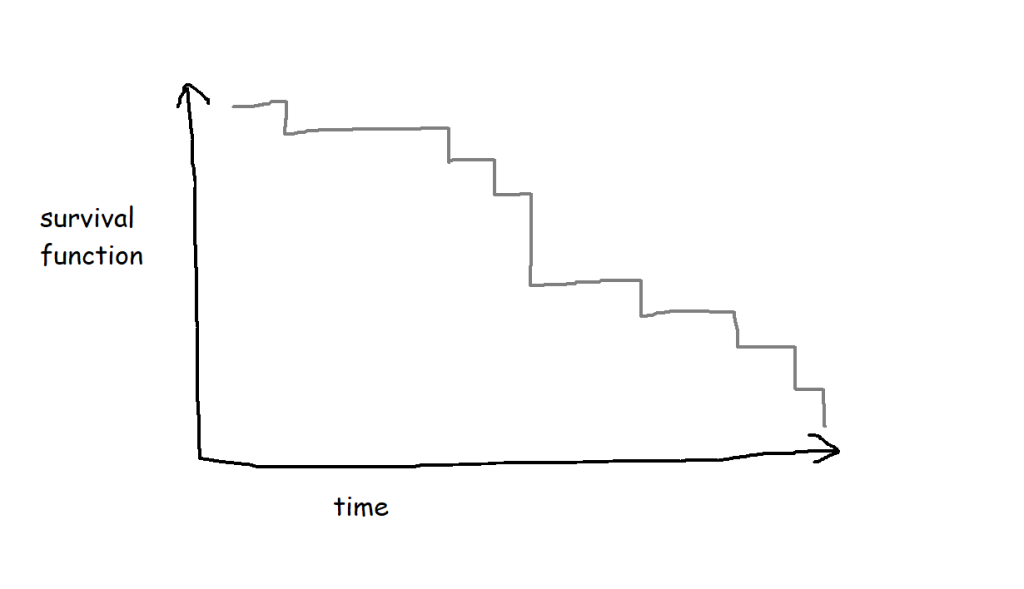
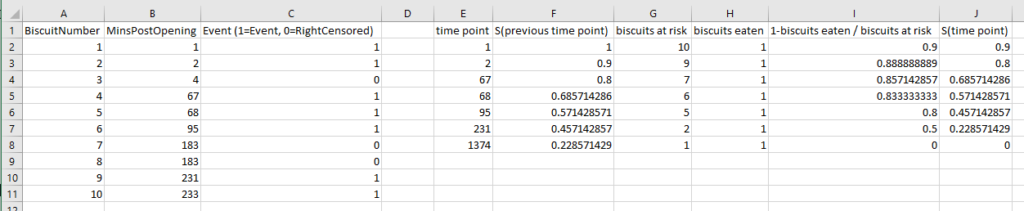
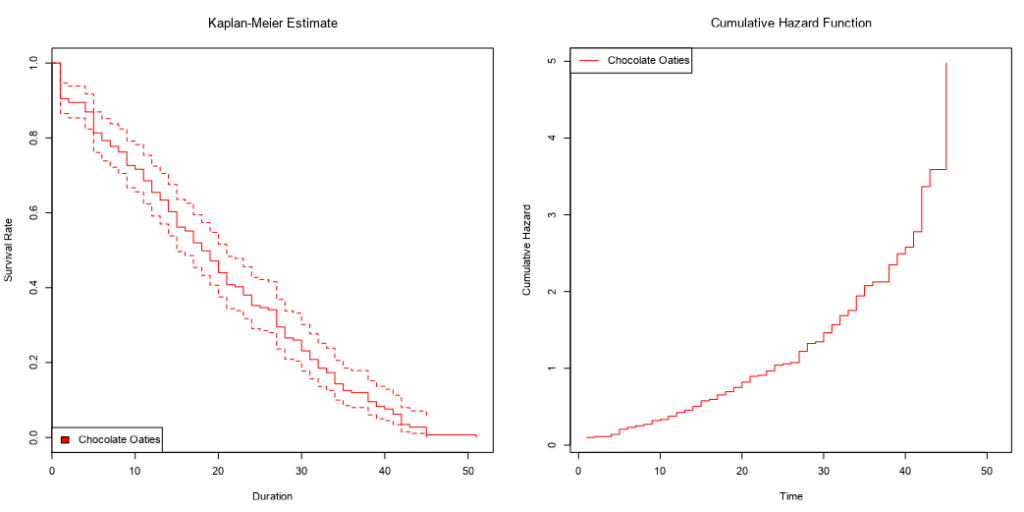
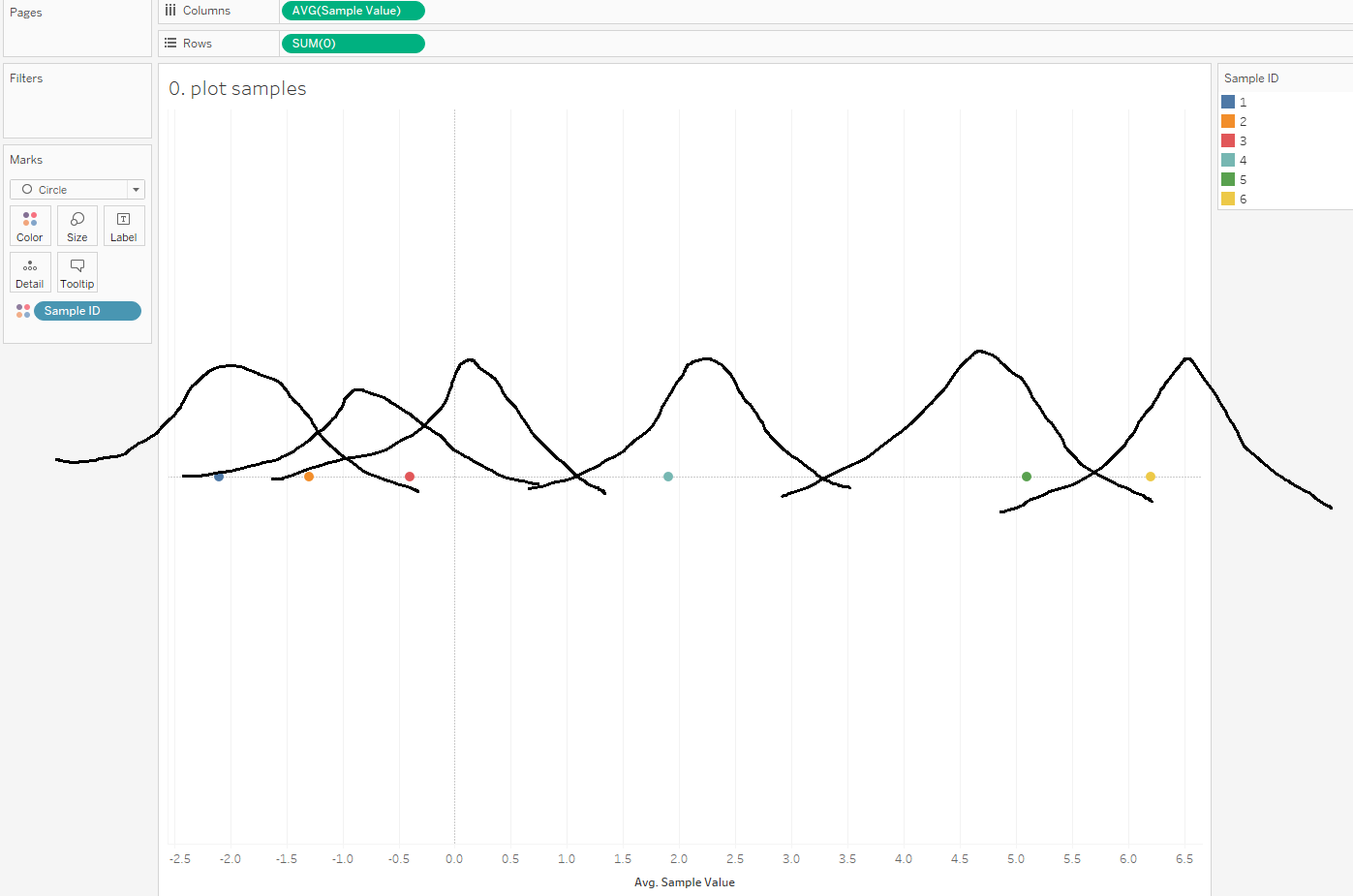
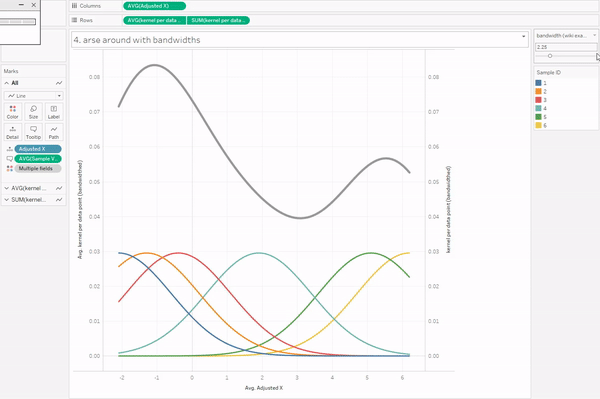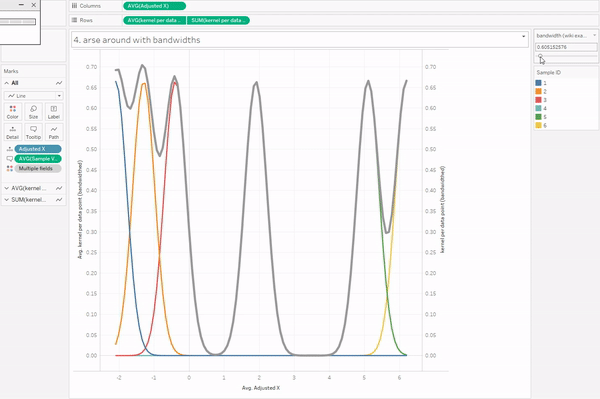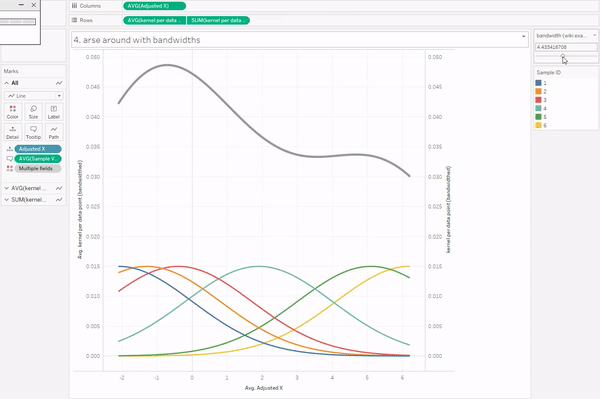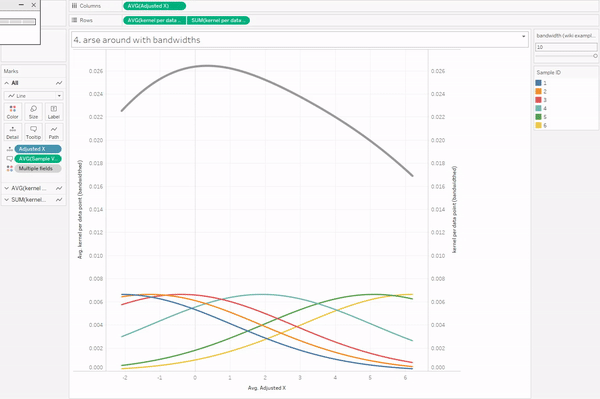
Survival analysis is most often visualised with Kaplan-Meier graphs, or survival curves, which look a bit like this:
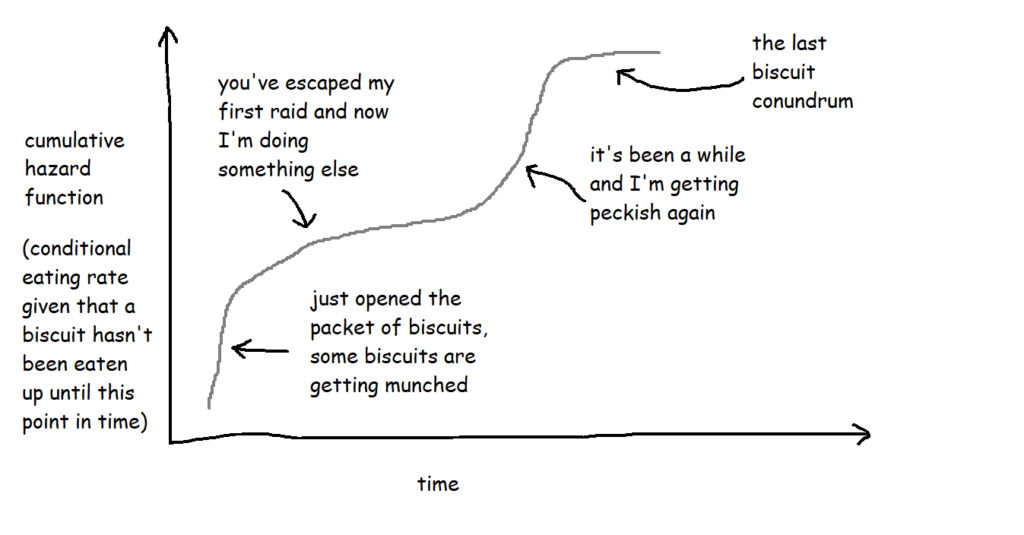
The survival function on the y-axis shows the probability that a thing will avoid something happening to it for a certain amount of time. At the start, where time = 0, the probability is 1 because nothing has happened yet; over time, something happens to more and more things, until something has happened to all the things.
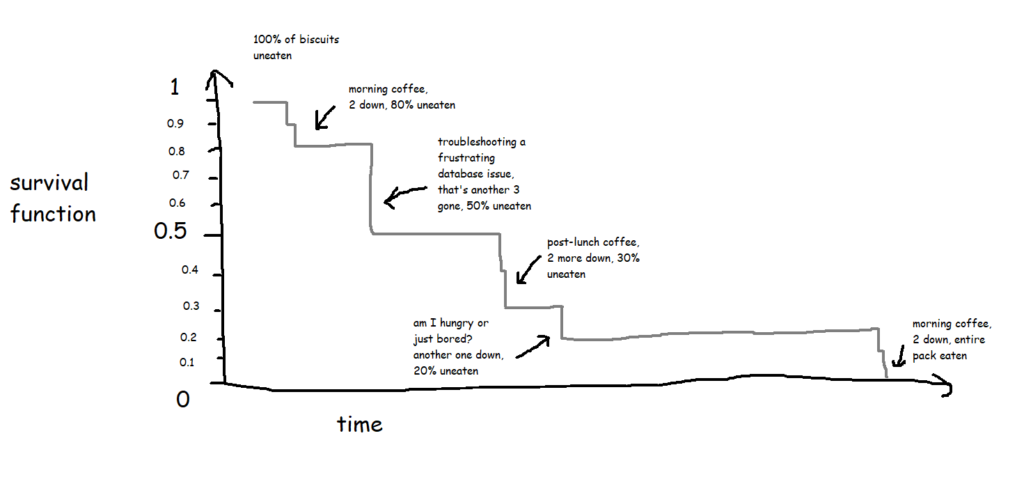
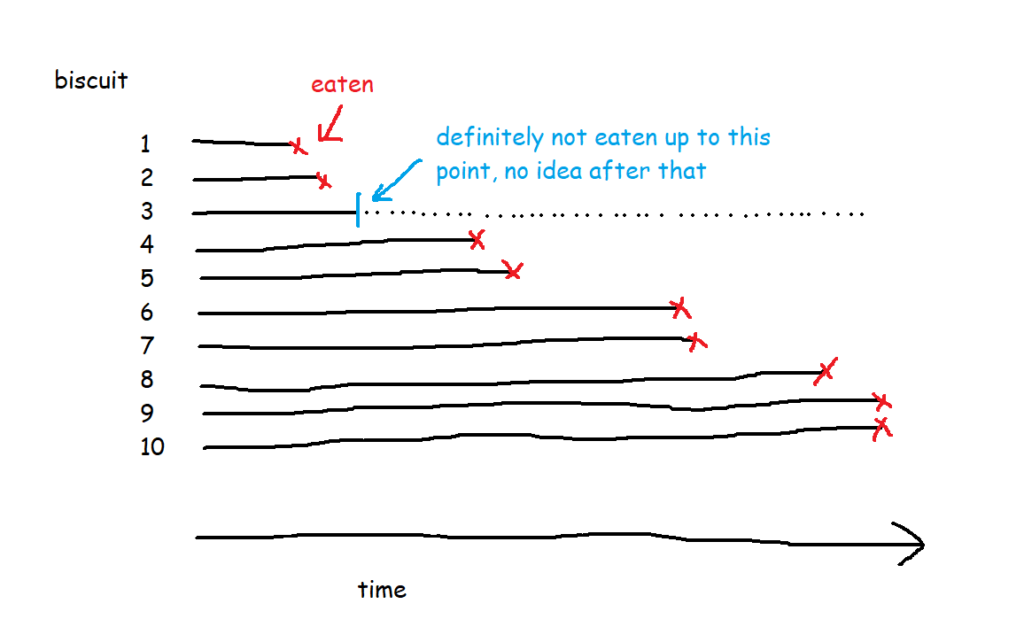
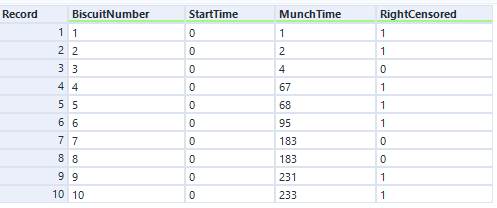
A lot of the examples are fairly morbid, so to illustrate this, I’ll talk about biscuits instead. I’ve just bought a packet of supermarket own-brand chocolate oaties, and they’re not going to last long. I’ve already had three. Okay, five. So, the biscuits are the things, being eaten is the event, and the time it’s taken between me buying the packet and eating the biscuit is the time duration we’re interested in.
Survival functions, or S(t)
In its simplest form, where every biscuit eventually gets eaten, a survival function is equivalent to the percentage of biscuits remaining at any given point:
This is the survival curve for a packet of ten biscuits that I have sole access to. And in cases like this, where there’s a single packet of biscuits where every biscuit gets eaten, the survival function is nice and simple.
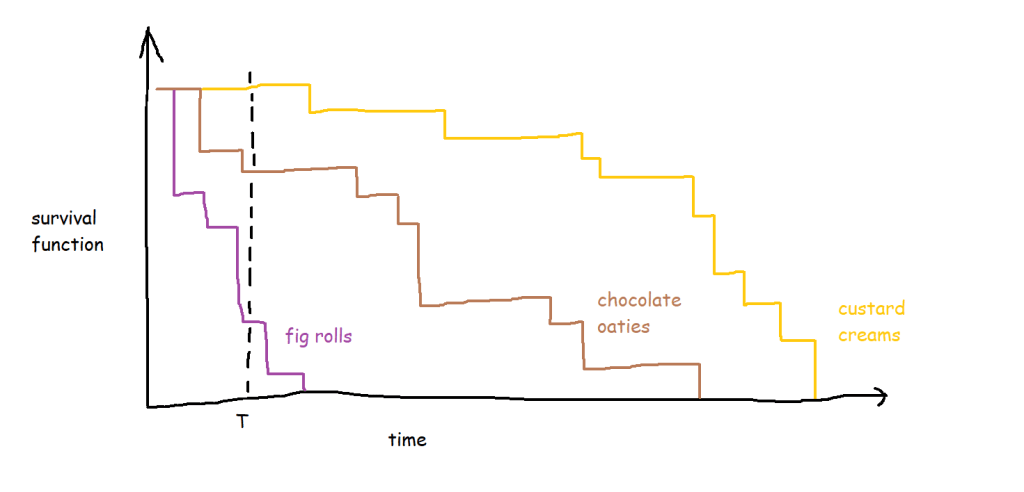
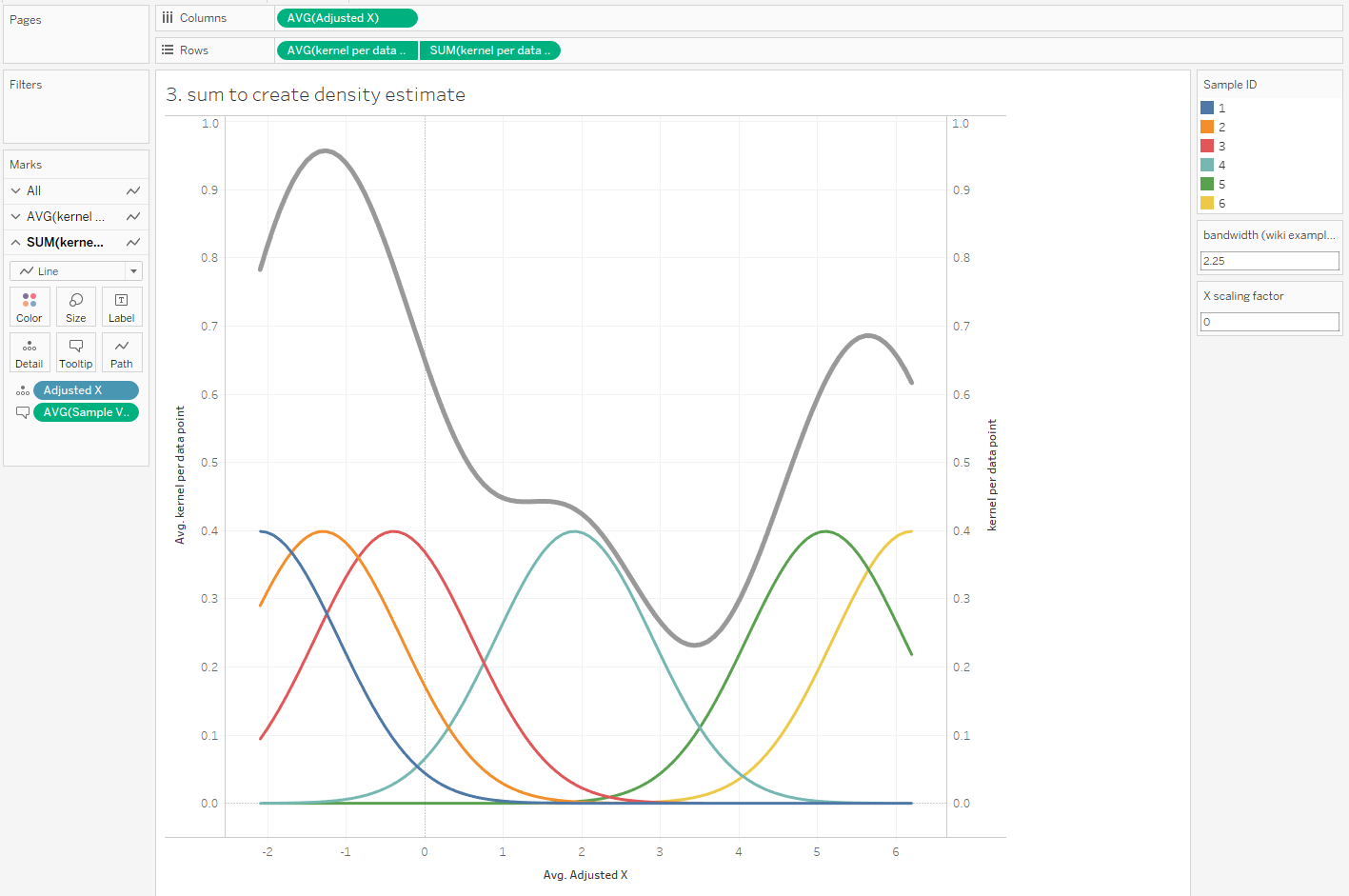
The curve gets more complicated and more interesting when you build up the data over a period of time for multiple packets of multiple biscuits. My biscuit consumption looks a little bit like this:
I’m not a huge fan of custard creams, so I don’t eat them as quickly. I really like chocolate oaties, and I can’t get enough of fig rolls, so I eat those ones much more quickly. This means that the probability that a particular biscuit will remain unmunched by time point T is around 100% for a custard cream, around 70% for a chocolate oatie, and around 30% for a fig roll:
(this assumes I’ve decanted the biscuits into a biscuit tin or something – if I’ve left them in the packet and I’m munching them sequentially, then the probability isn’t consistent for any given biscuit, but let’s leave that aside for now)
A quick detour to talk about censoring
But in most survival analysis situations, the event won’t happen to every thing, or to put it another way, the time that the event happens isn’t known for every thing. For example, I’ve bought the packet of biscuits, and I’ve had two, and then a little while later I come back and there are only seven left when there should be eight. What happened to the missing biscuit? I didn’t eat it, so I can’t count that event as having happened, but I can’t assume that it hasn’t been eaten or never will be eaten either. Instead, I have to acknowledge that I don’t know when (or if) the biscuit got eaten, but I can at least work with the duration that I knew for sure that it remained uneaten.
This concept is called censoring. Biscuit number three is censored, because we don’t know when (or if) it was eaten.
There are a few different types of censoring. Right-censored data, which is the most common kind, is where you do know when something started, but you don’t know when the event happened. This could be because the biscuit has gone missing and you don’t know what’s happened to it, or simply because you’ve finished collecting your data and you’re doing your analysis before you’ve finished all the biscuits. If you’re doing survival analysis on customers of a subscription service, like if you’re looking at how long it takes for somebody with a Spotify account to decide to leave Spotify, anybody who still has a Spotify account is right-censored – you know how long they’ve had the account, but you don’t know when (or if) they’re going to cancel their subscription. The event is unknown or hasn’t happened yet. To put it another way, the actual survival time is longer than (or equal to) the observed survival time.
Left-censored data is the other way round. For left-censored data, the actual survival time is shorter than (or equal to) the observed survival time. In the biscuit situation, this would be where I’m starting my survival analysis data collection after I’ve already started the packet of biscuits. I can work out when I bought the packet by looking at my shopping history, and I know what the date and time is right now. I don’t know exactly when I ate the first biscuit, but I know that it has to before now. So, the observed survival time is the time between buying the packet of biscuits and right now, and the data for the missing biscuits is left-censored because I’ve already eaten them, so their actual survival time was shorter than the observed survival time.
There’s also interval censoring, where we only know that the event happened in a given interval. So, with the biscuits, imagine that I don’t record the exact timestamp of when I eat them. Instead, I just check the packet every hour; if the packet was opened at 9am, and a biscuit has been eaten between 11am and 12 noon, I know that the survival time is somewhere between 120 and 180 minutes, but not the exact length.
I normally find that my data is right-censored or not censored, and rarely need to run survival analysis with left- or interval-censored data.
Back to survival functions
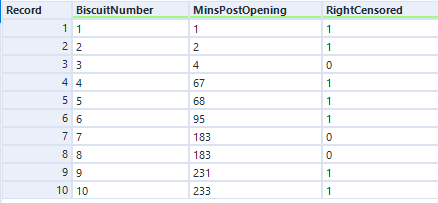
So, let’s have a look at the survival function for this data set of ten packets of biscuits where there are some right-censored biscuits too. It’s no longer as simple as the percentage of biscuits that haven’t been eaten yet.
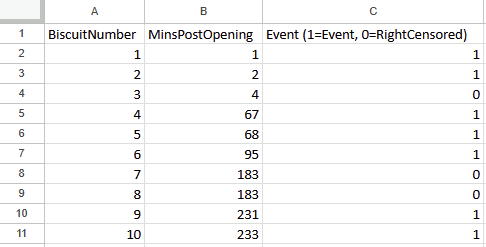
There are ten biscuits in the packet, and I’ve eaten seven of them. Three of them have gone missing in mysterious circumstances, which I’m going to blame on my partner. All I know about BiscuitNumber 4 is that it was gone by minute 4 after the packet was opened, and all I know about BiscuitNumbers 7 and 8 is that they were also gone when I checked the packet at 183 minutes post-opening. My partner probably at them, but I don’t actually know.
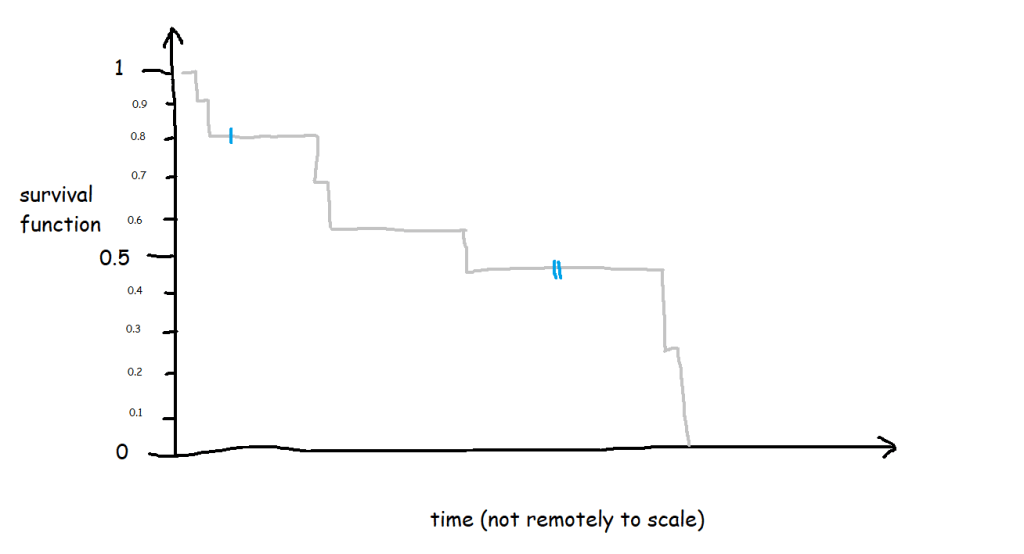
The survival curve for this data looks like this:
The blue lines show where the right-censored biscuits have dropped out; I haven’t eaten them, so I can’t say that the event has happened to them, but they’re not in my data set anymore, and that’s the point at which they left my data set.
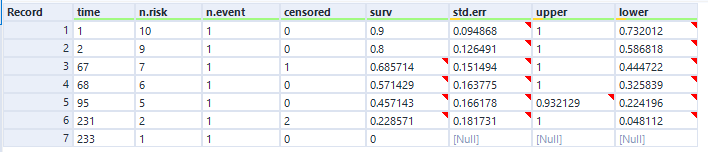
Let’s have a look at the exact numbers on the y-axis:
This is a little less intuitive! The survival function is cumulative, and it’s calculated like this as:
S(t) = S(t-1) * (1 - (# events / # at risk)
which in slightly plainer English is:
[the survival function at the previous point in time] * (1 - [number of events happening at this time point] / [number of things at risk at this time point])
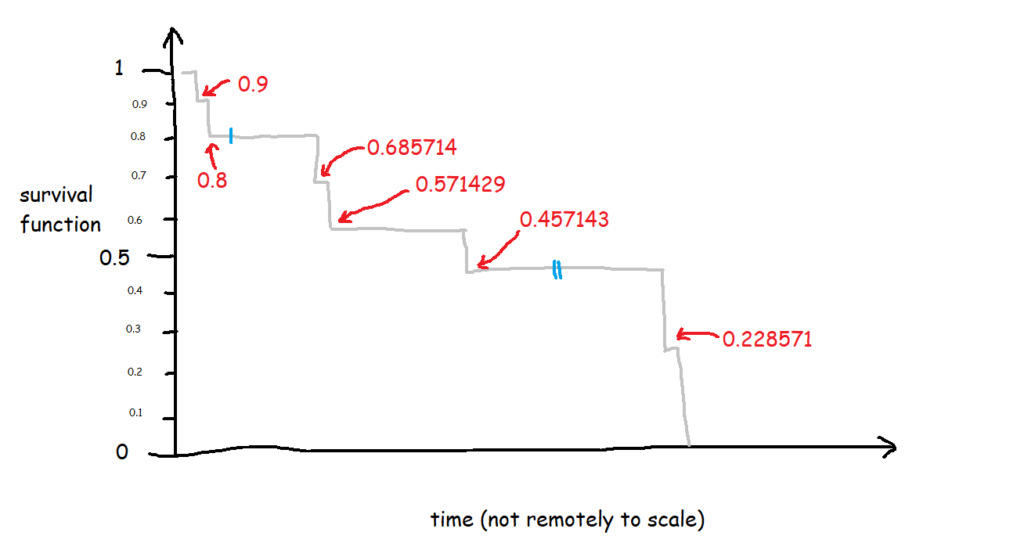
At the first time point, at 1 minute post-opening, I eat the first biscuit. At that point, all 10 biscuits are present and correct, so all 10 biscuits are at risk of being eaten. That makes the survival function at 1 minute post-opening:
1 * (1 - (1/10) = 1 * 0.9
So, we end up with 0.9 at 1 minute post-opening, or S(1) = 0.9.
At the next time point, at 2 minutes post-opening, I eat the second biscuit. At that point, 1 biscuit has already been eaten (BiscuitNumber 1 at 1 minutes post-opening), so we’ve got 9 biscuits which are still at risk. Moreover, the survival function at the previous time point is 0.9. That makes the survival function at 2 minutes post-opening:
0.9 * (1 - (1/9) = 0.9 * 0.8888
So, we end up with 0.8 at 2 minutes post-opening, or S(2) = 0.8. So far, so good.
But then it gets a little trickier, because we’ve got a censored biscuit. BiscuitNumber 3 drops out of our data at 4 minutes post-opening. We don’t adjust the survival curve here because the eating event hasn’t happened, but we do make a note of it, and continue onto the next event, which is when I eat my third biscuit at 67 minutes post-opening. At this point, 2 biscuits have already been eaten (BiscuitNumbers 1 and 2), and 1 biscuit has dropped out of the data (BiscuitNumber 3). That means that there are now 7 biscuits which are still at risk. The survival function at the previous time point is 0.8, so the survival function at 67 minutes post-opening is:
0.8 * (1 - (1/7) = 0.8 * 0.85713
That gives us 0.685714, so S(67) = 0.685714. This is less intuitive now, because it doesn’t map onto an easy interpretation of percentages. You can’t say that 68.57% of biscuits are uneaten – that doesn’t make sense, as there were only 10 biscuits to begin with. Rather, it’s a cumulative, adjusted view; 80% of biscuits were uneaten at the last time point, and then of those 80% that we still know about (i.e. limit the data to biscuits which are either definitely eaten or definitely uneaten), 85.71% of them are still uneaten now. So, you take the 85.71% of the 80%, and you get a survival function of 68.57%, which is the probability that any given biscuit remains unmunched by 67 minutes post-opening, accounting for the fact that we don’t know what’s happened to some biscuits along the way.
I had to work this through step-by-step in an Excel file to fully wrap my head around it, so hopefully this helps if you’re still stuck:
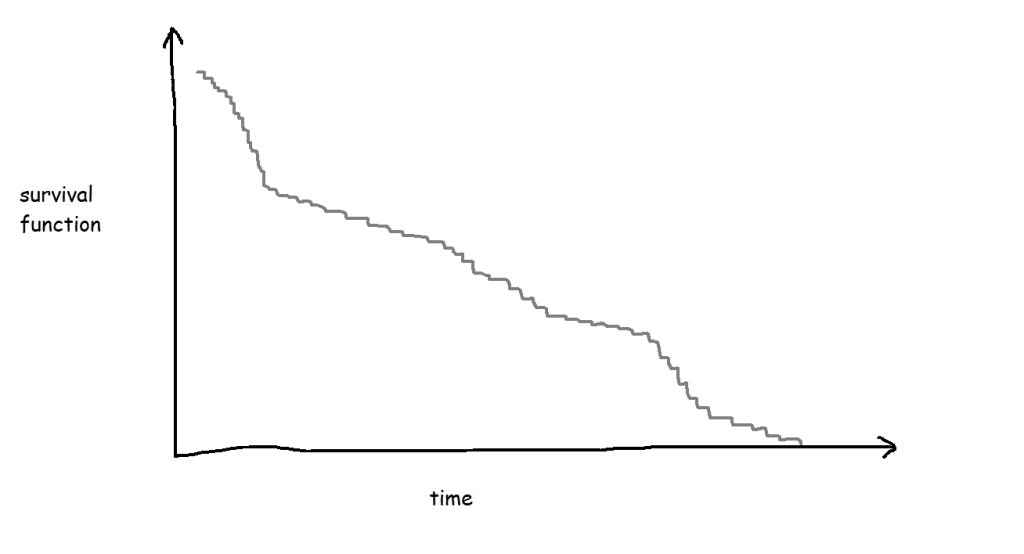
If I collect biscuit data over several packets of biscuits and add them all to my survival analysis model, I’ll get a survival curve with more, smaller steps, like this:
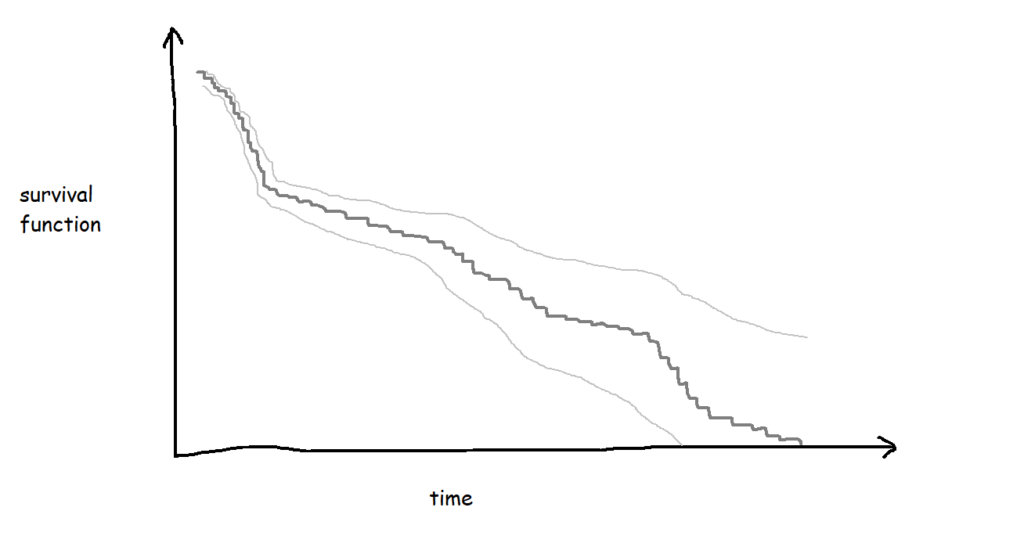
The more biscuits that have gone into my analysis, the more confident I am that the survival curve is an accurate representation of the probability that a biscuit won’t have been eaten by a particular time point. Better still, you can show this by plotting confidence intervals around the survival function too:
Hazard functions, or h(t)
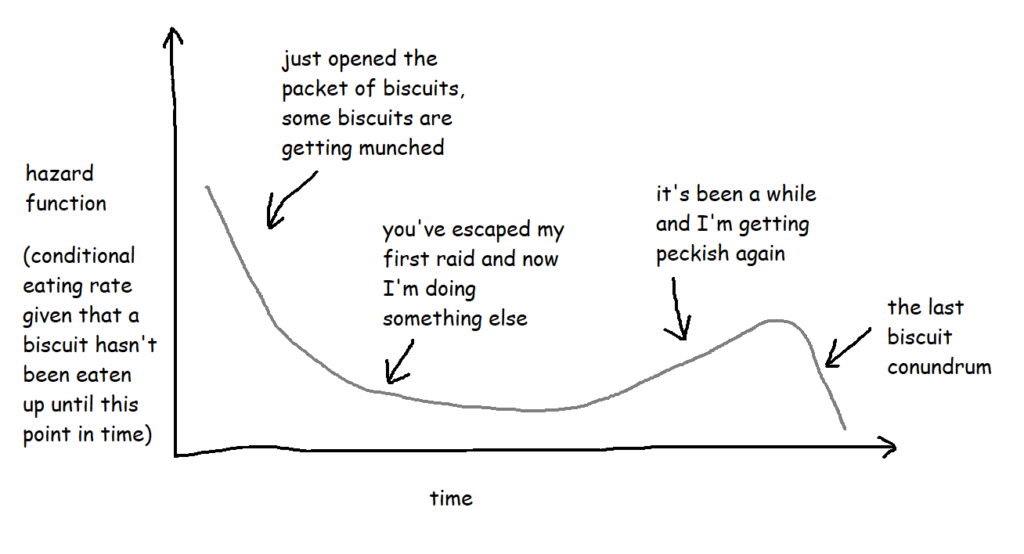
If the survival function tells you what the probability of something not happening by a particular point in time is, a hazard function tells you the risk that something is going to happen given that you’ve made it this far without it happening.
With the biscuit example, when I open the packet, let’s say any given biscuit has a 70% chance of surviving longer than two hours. But what about if the packet is already open? What’s the risk of a biscuit being eaten if it’s already three hours since I opened the packet and that biscuit hasn’t been eaten yet? That’s the hazard function.
Technically, the hazard function isn’t actually a probability – the way it’s calculated is by taking the probability that a thing has survived up until a certain point but the event will happen by a later point and then dividing it by the interval between the two points, so you get the rate that the event will happen, given that it hasn’t happened up until now. But it also involves limits, and there are a lot of blogs and articles out there describing exactly how it works. For the purposes of this blog, it’s more useful to think of it as a conditional failure rate, and you can use the hazard function to interpret risk a bit like this:
These are often plotted cumulatively:
It’s not exactly an intuitive graph, but it essentially shows the total amount of risk faced over time. You can kind of think of it like “how many times would you expect the event to have happened to this thing by now?”. So, in this case, it’s “if this biscuit has made it this far without being eaten, how does that compare to the rest of them? How many times would you expect this biscuit to have been eaten by now?”.
Cox proportional hazards
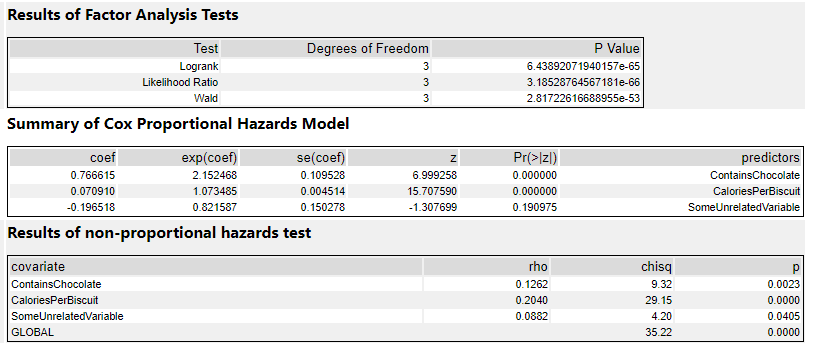
Now that we’ve got our survival curves, we can analyse them with a Cox proportional hazards model, and use that model to predict survival relative risk for future things. It’s a bit like a linear regression for looking at the survival time based on various different factors, and it lets you explore the effect of the different factors on the survival time.
The output of a Cox proportional hazards model should give you the following information for each variable:
The statistical significance for each variable i.e. does it look like this actually has an effect on the survival time? e.g. biscuits with more calories in them taste better, so I’m more likely to eat them more quickly … but is that true?
The coefficients i.e. is it negative or positive? If it’s positive, then the higher this variable gets, the higher the risk of the event happening gets; if it’s negative, then the lower this variable gets, the higher the risk of the event happening gets. e.g. if it turns out that I do indeed eat biscuits with more calories in them more quickly, then the coefficient for the variable CaloriesPerBiscuit will be positive. But if it turns out that I actually eat less calorific biscuits more quickly because they’re less instantly satisfying, then the coefficient for CaloriesPerBiscuit will be negative.
The hazard ratios i.e. the effect size of the variables. If it’s below 1, it reduces the risk; if it’s above 1, it increases the risk. e.g. a hazard ratio of 1.9 for ContainsChocolate means that having chocolate on, in, or around a biscuit increases the hazard by 90%
At this point, it’s a lot easier to explain things with some actual results, so let’s dive into how to do it in Alteryx, and come back to the interpretations later.
Survival analysis in Alteryx
First of all, you’ll need to download the survival analysis tools from the Alteryx Gallery. The search functionality isn’t great, so here’s the links:
Survival analysis tool Download it here Read the documentation here
Survival score tool Download it here Read the documentation here
I’ve also put up an example workflow on the public gallery, which you can download here
Nice. Now, you need some data! Let’s start out with the simple example I used to illustrate Kaplan-Meier survival curves:
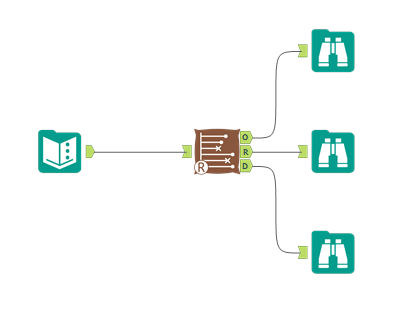
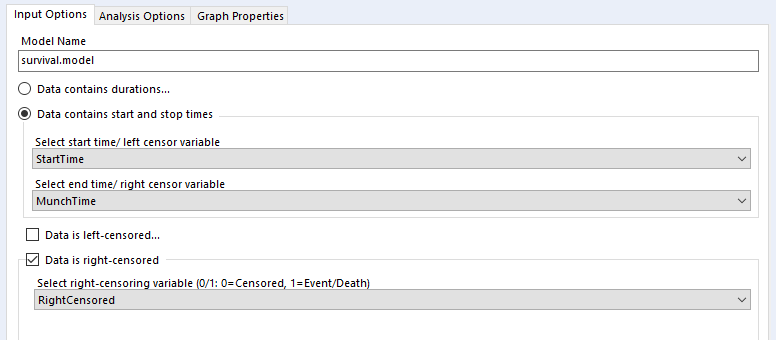
The data needs to have one row per thing, with a field for the duration or survival time, and another field for whether the data is censored or not (the eagle-eyed reader may have spotted something confusing with the RightCensored field – more on that in a moment). Now I can plug it straight into the survival analysis tool:
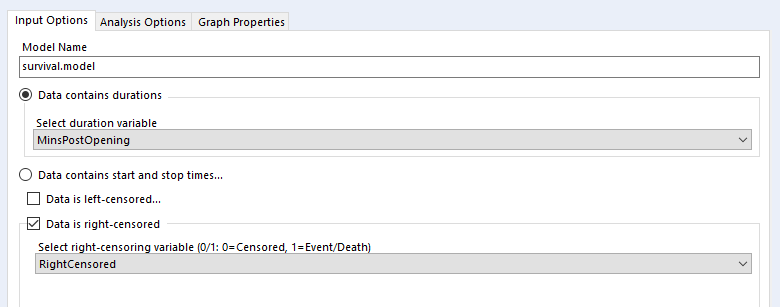
Let’s have a look at how to configure the tool. The input options are the same for both Kaplan-Meier graphs and Cox proportional hazards models:
I’ve selected the option “Data contains durations”, as I have a single field for the number of minutes a biscuit lasted before being eaten, rather than one field for the time of packet opening and another field for the time of biscuit eating. I prefer using a single field for durations for two reasons. Firstly, because the tool doesn’t accept date or datetime fields, only numbers, and I find it easier to calculate the date difference than to convert two date fields into integers; secondly, as it allows me to sort out any other processing I need beforehand (e.g. removing time periods when I wasn’t in the flat because there wasn’t any actual risk of the biscuits being eaten at that time). But, if you have start and stop times in a number format and don’t want to do the time difference calculation yourself, you can have your data like this:
…and set up your tool like this:
…and you should get the same results.
Confusingly, the survival analysis tool asks whether data is censored, and asks for a 0/1 field where 1 = “the event happened” (i.e. this data isn’t actually censored) and 0 = “I don’t know what happened” (i.e. this data is censored). I often get this mixed up. But yes, if your data is right-censored, you need to assign that a 0 value, and if your event has actually happened, that’s a 1.
Kaplan-Meier
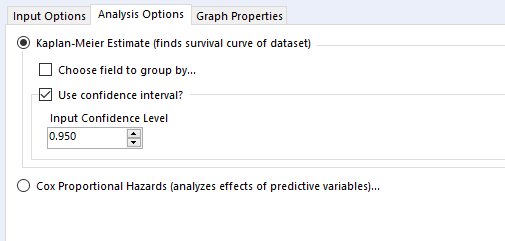
Then there’s the analysis tab. Let’s go over Kaplan-Meier graphs first:
We’re doing the survival curve at the moment, so select the Kaplan-Meier Estimate option. I’d recommend always using the confidence interval – it might make the plots harder to read when you group by a field, but you’ll want that data in the output.
The choose field to group by option is also good to look at, but there’s a strange little catch with this; it won’t work unless the field you’re grouping by is the first field in your data set, so you’ll need to put a select tool on before the survival analysis tool, and make sure that you move your grouping field right to the top.
Now you can run the workflow. There are three outputs: O: Object. You can plug this into a survival score tool, but I don’t really do much with this otherwise R: Report. This is full of interesting information, so stick a browse tool on the end. D: Data. This is brilliantly useful, and I wish more Alteryx predictive tools did this. It’s the stuff that’s shown in the report output, but a data table that you can do stuff with.
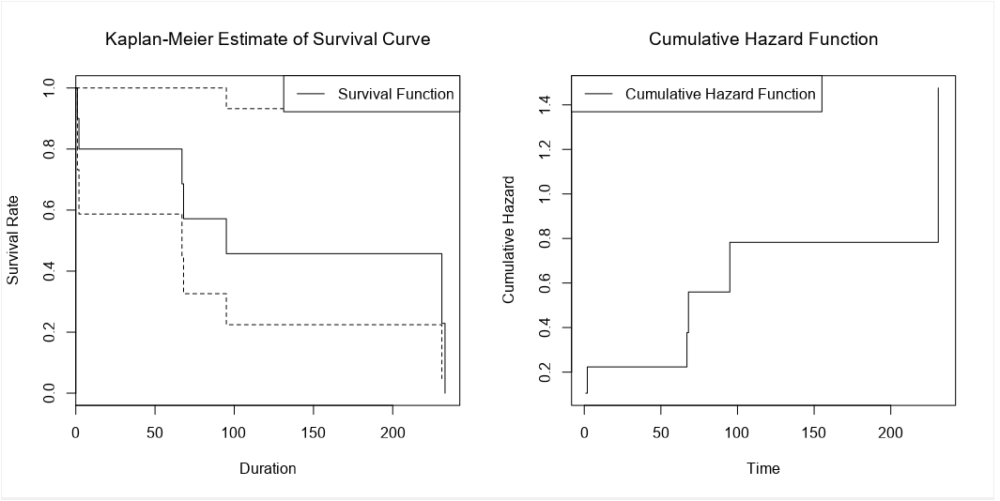
Here’s what the report output looks like:
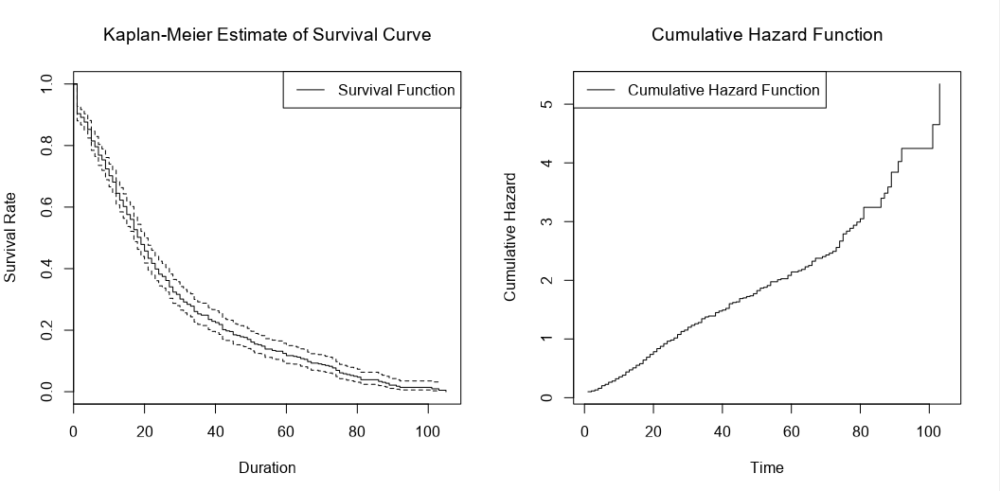
There’s the survival curve, along with some giant confidence intervals because there are so few biscuits in the data set. This is the same one that I was drawing in MS Paint in the first section.
We’ve also got the cumulative hazard function, which I drew earlier too. It’s is the running sum of the hazard functions along the time period. In this particular example, it just looks like the survival curve but rotated a bit, but we’ll see examples where it’s different later.
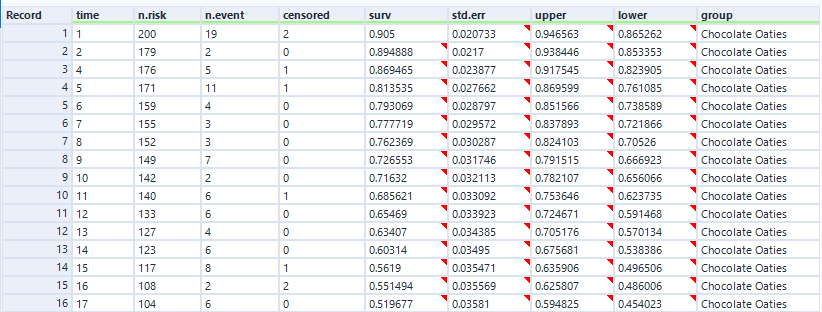
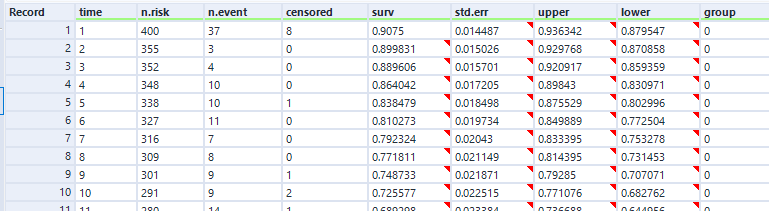
In the data output, we can see the curve data in a table:
And again, this is the data as profiled in the screenshot from Excel earlier when I was working through the survival function calculations.
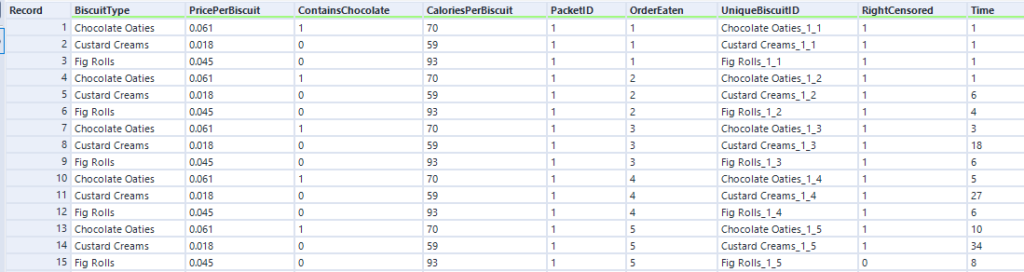
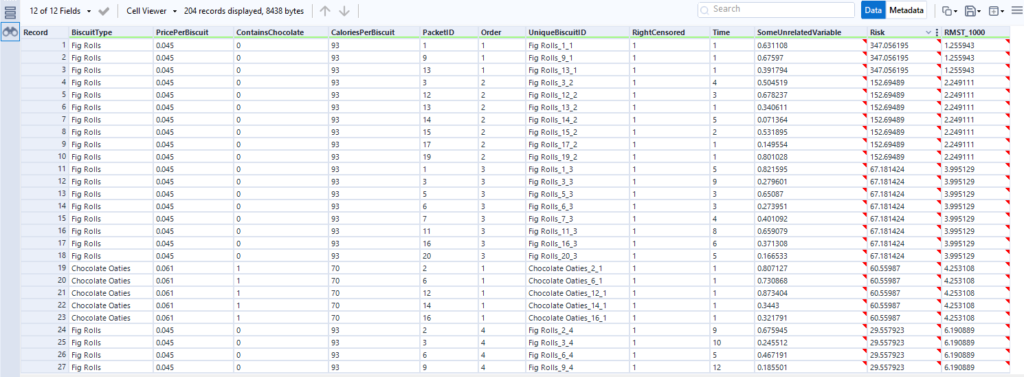
Let’s now move to a bigger data set of biscuits. I’ve tracked my consumption of fig rolls, chocolate oaties, and custard creams in a table that looks like this:
(this is all fake data that I’ve generated for this blog, if you haven’t guessed already – but it is “based on a true story”)
The Time field is the duration – I’ve generated it kind of arbitrarily. We can pretend it’s still minutes, although as you’ll see, I end up finishing a pack of fig rolls in about thirty minutes, which is going it some even for me.
When I run the main survival analysis, I get a nice survival curve of my general biscuit consumption:
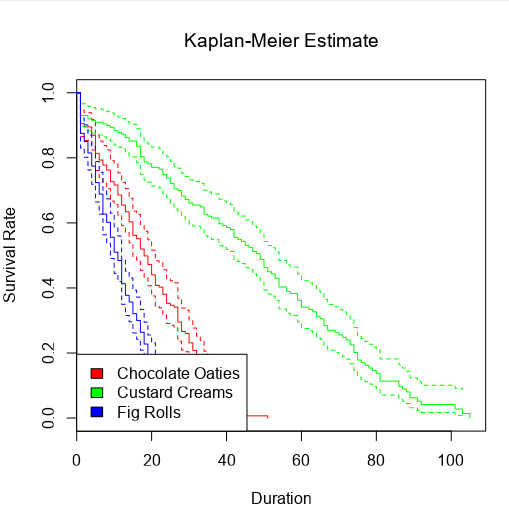
I can also choose the group by option to create separate survival curves for each biscuit type, and it’ll plot the survival curves of all three alongside each other:
…and then the survival curve and cumulative hazard function of each biscuit type individually:
When grouping by a field, you get this extra table in the report output:
The obs column is a simple count of how many biscuits actually got eaten (i.e. the sum of the RightCensored field I created earlier), but I’m not sure where they’re getting the exp values from. I’m also not sure why I don’t get this table when I’m not grouping by any fields.
Another quirk of the survival analysis tool is that I get this warning message about nonstandard censoring regardless of what I do:
I haven’t figured out why it happens – if you do, give me a shout.
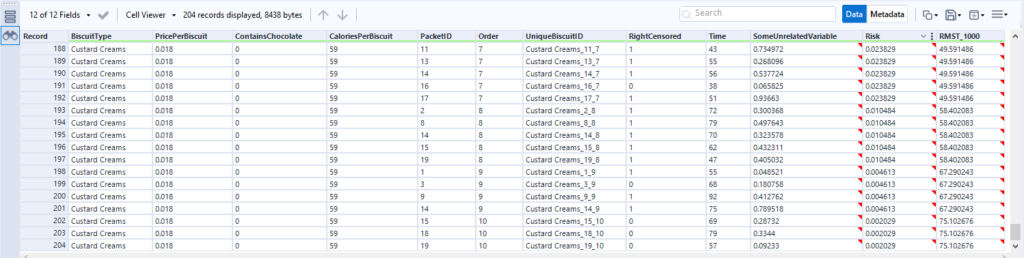
In the data output, we get the survival curve data points for each group, which is really useful. We’ll use this data later and plot it in Tableau:
Cox proportional hazards
Back to the analysis tab, then.
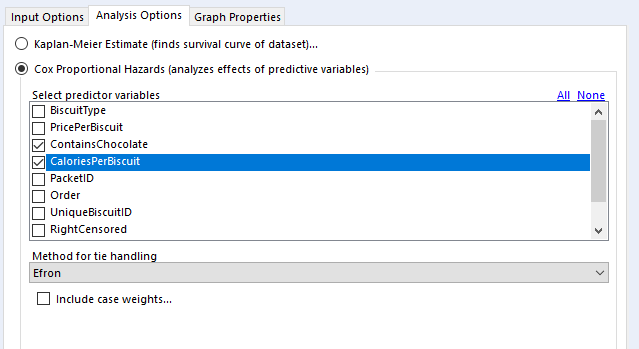
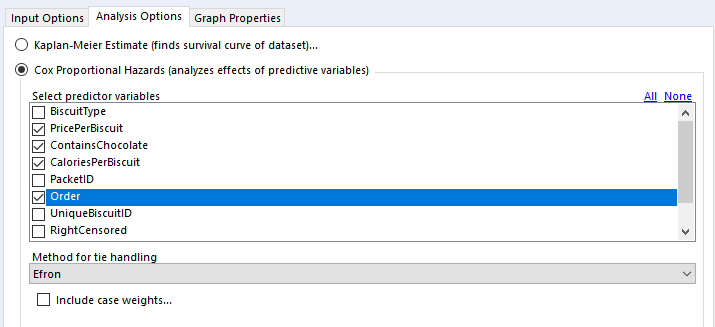
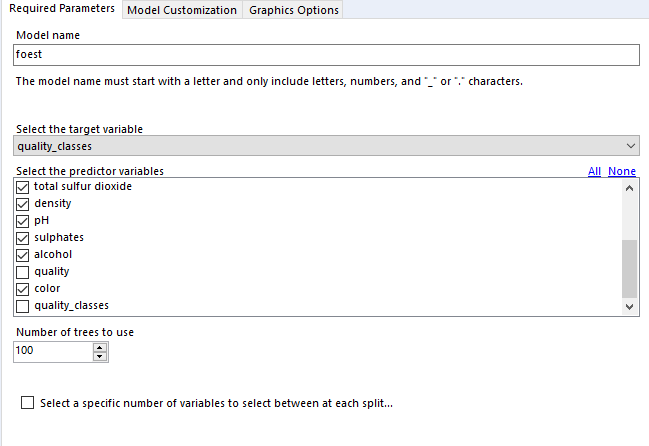
In the “select predictor variables” section, you can select the variables you want to investigate. I generally use binary fields and continuous fields here. You can use categorical fields, but I wouldn’t recommend it, as they get converted to paired binary fields anyway (more on that in a bit).
For tie handling, I just leave it at Efron. The survival R package documentation that the survival analysis tool is built off has a long explanation; the summary version is that if there aren’t many ties in your data (i.e. if there aren’t many things that have the same duration), then it doesn’t really matter which option you use, and Efron is the more accurate one anyway.
Finally, case weights gives you an option to double-count a particular line of data. As far as I can tell, this is functionally equivalent to unioning in every line of data you want to replicate; there’s no difference between running a Cox proportional hazards model on 500 rows where each row has case weight = 2 and running the same model on 1000 rows where it’s the 500 row table unioned to itself. The model returns the same coefficients, but the p-values are different. In any case, it seems like it’s a throwback to when data was reduced as much as possible to keep it light. I can’t see any need to include case weights in your analysis in Alteryx, but again, hit me up if you have a use case where this is necessary.
Here are the results in the results tab:
The factor analysis section is testing whether the model itself is significant. If it’s not (i.e. if the p-value is > 0.05), then the rest of the results are interesting to look at but not really that meaningful. If it is significant, then you can proceed to the rest of the results.
The summary section is the most useful bit. The coef column shows the coefficients. This is where the sign is important – if it’s positive, then there’s a corresponding increase in risk, whereas if it’s negative, then there’s a corresponding decrease in risk. My ContainsChocolate field is positive, so if a biscuit contains chocolate, then there’s an increase in the risk to the biscuit that I’ll eat it. Same goes for CaloriesPerBiscuit, which is also positive. The more calories a biscuit has, the greater the risk that I’ll eat it.
The exp(coef) column shows the exponent of the coefficient, which basically means the effect size of the variable. The exp(coef) for ContainsChocolate is 2.15, which means that having chocolate in the biscuit will more than double the risk that I’ll eat it. The exp(coef) for SomeUnrelatedVariable is 0.82, which suggests that the risk decreases by 18% as SomeUnrelatedVariable rises…
…but as we can see in the Pr(>|z|) column, the p-value for SomeUnrelatedVariable is 0.19, which means it’s not significant (I’d hope not, as I created SomeUnrelatedVariable by just sticking RAND() in a formula tool). So, we can ignore the coef and exp(coef) columns, because they aren’t really meaningful. The ContainsChocolate and CaloriesPerBiscuit fields are significant, so I can use that information to explore my biscuit consumption.
This is where knowing your variables is really important. If I’d coded up my ContainsChocolate variable differently, and set it so that 0 = contains chocolate and 1 = does not contain chocolate, then the model would return -0.766615 in the coef column rather than 0.766615. Likewise, the exp(coef) column would be a little under 0.5 rather than a little over 2. If you mix up which way round your variables go, you’ll draw completely the wrong conclusion from the stats.
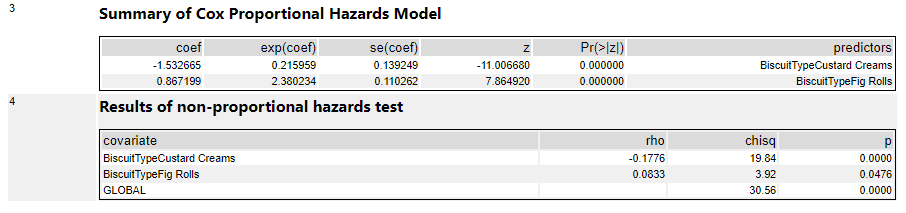
It’s possible to use categorical fields in the Cox proportional hazards model too, but all it does is create new variables by comparing everything to the first item in the categorical field in a binary way. So, in this output, I’ve used BiscuitType as a predictor variable, and the tool has converted that into two variables; chocolate oaties vs. custard creams (where chocolate oaties = 0 and custard creams = 1), and chocolate oaties vs. fig rolls (where Chocolate oaties = 0 and custard creams = 1). The interpretation of these results is that there’s a huge difference between custard creams and chocolate oaties in terms of survival. As the new field BiscuitTypeCustardCreams increases (i.e., for custard creams), the risk of being eaten decreases, as shown by the negative coef value of -1.53, and that translates to a risk reduction of 79% as shown by the exp(coef) value of 0.21:
The more things you’ve got in a categorical field, the more of these new variables you’ll get, and it’ll get messy. I prefer to work out any categorical variables of interest beforehand and translate them into more useful groupings myself first, such as in my field ContainsChocolate.
Combining Cox proportional hazards with a survival score tool
Finally, once you’ve got a model that you’re happy with, you can use it with the survival score tool to predict relative risk and survival times for other biscuits.
I highly recommend validating your model predictions on your original data set so that you can compare the output of the survival score tool with the survival times that actually happened:
What I’ve done here is train my Cox proportional hazards model on 66% of the biscuit data, and then used the output of that model in the survival score tool to predict biscuit survival time for the remaining 34%. I’ve also included Order in the model as the order where the biscuit sits in the packet, as that’s obviously going to affect the survival time of the biscuit. Actually, I shouldn’t really be doing the analysis like this at all, because the fact that there’s an order to them shows that the biscuits aren’t independent, but I’m 4000 words into this analogy now. Just pretend that the biscuits are independent and sitting in a tin, and that the order field is some kind of variable that affects how quickly an individual biscuit gets eaten, yeah? Anyway, here’s the configuration pane:
If I look at the output, it’s pretty good:
This first table is sorted by the relative risk factor that the score tool puts out, and it’s showing that the biscuits with the highest risk of being eaten are the fig rolls in the first few positions in the packet, then the chocolate oaties in the first position in the packet. The actual survival duration (just called Time here) is pretty low too. If I scroll down to see the lowest risk, I can see lower relative risk in the Risk field, and higher actual survival times in the Time field:
So, I’m happy that my model is a good one, and I can now put some new biscuit information to predict survival time for a new set of biscuits. Maybe some bourbons, maybe some ginger nuts, maybe even some garibaldis.
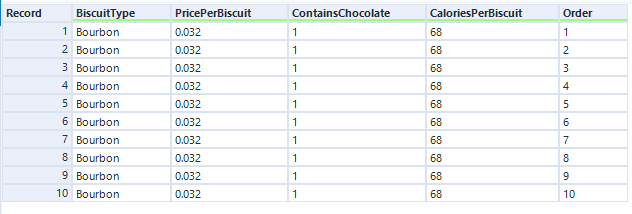
Let’s predict survival time and relative risk for a new packet of bourbons:
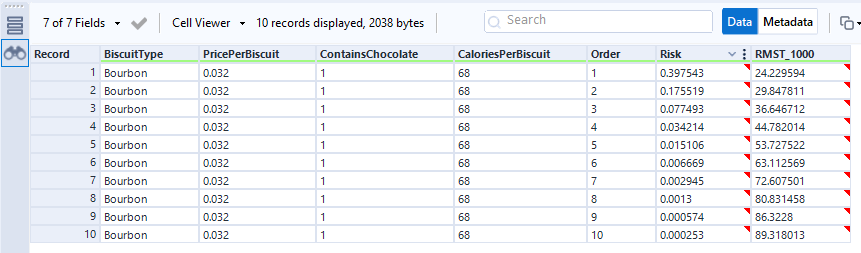
The score tool has established the relative risk for each biscuit in the packet, and the RMST_1000 output shows the number of minutes it’s expecting each biscuit to survive for:
This isn’t perfectly accurate – we’ve already seen in the data that the first two biscuits of most packets get eaten within a couple of minutes, but the time prediction for biscuit number 1 is 24 mins. More data and more different predictor fields will make that more realistic.
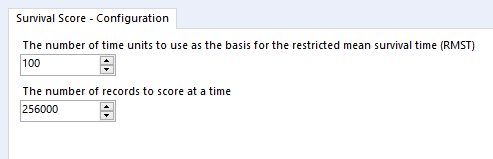
The RMST bit of the RMST field stands for Restricted Mean Survival Time, and it’s set in the survival score tool configuration pane:
It’s a value you can choose to get a relatively realistic estimate of how long something will survive for out of a fixed number of time units. It’s helpful for cases when you’re running your analysis with a lot of right-censored data because the event simply hasn’t happened yet, such as customer churn. Then you can get an estimate of how the survival curve might extend beyond the period you’ve got.
Visualising survival analysis in Tableau
Now that I’ve got my biscuit survival models, I want to visualise them in Tableau, because the default R plots in the browse tool aren’t great.
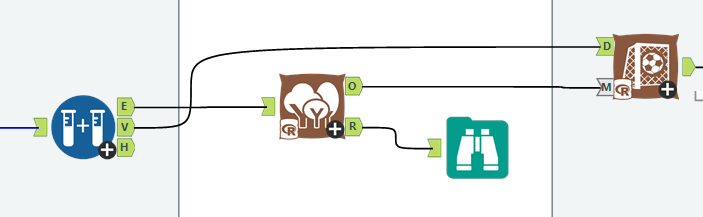
I want three different survival curves – the general biscuits curve, the curves broken down per BiscuitType, and the curves broke down by ContainsChocolate. So, I’m going to need three separate survival tools to get the data for these survival curves.
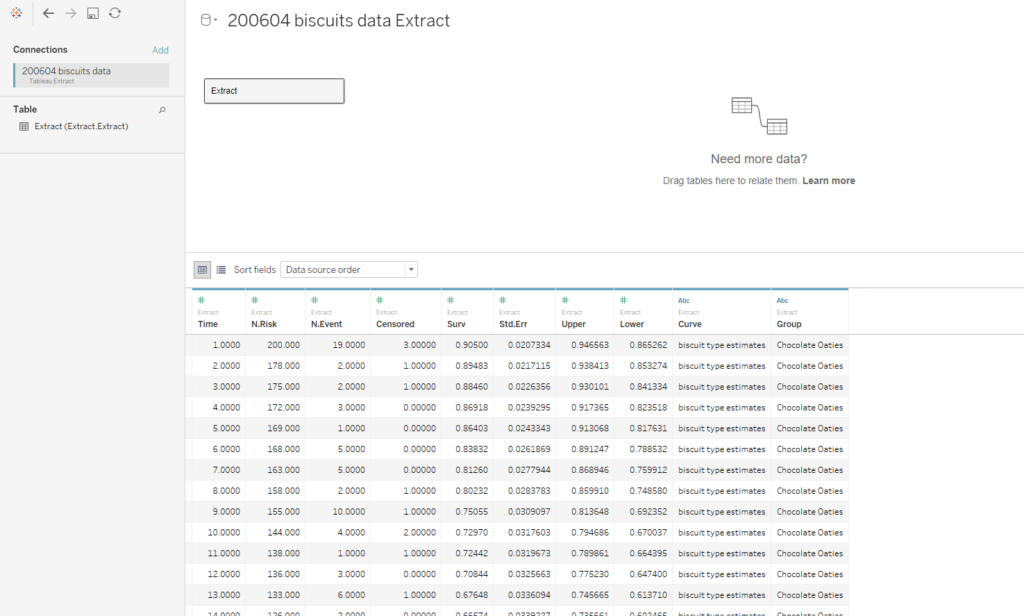
It’s also important to do a little bit of data processing to the output of the D anchor. This is how the data looks:
The first line of data is at time = 1, which is the time of the first event. To make the graph in Tableau, we’ll need an extra line at the top where time = 0 and the survival function = 1. This line needs to be repeated for each group that we’ve grouped by in the survival analysis tool.
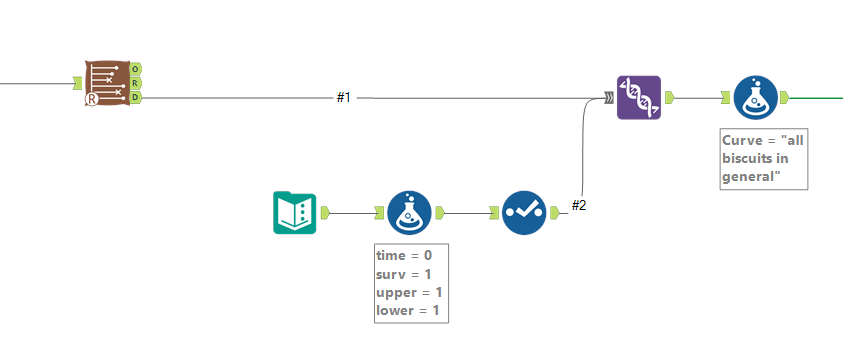
For the single survival curve of all biscuits, I do this by using a text input tool with a single row and single column, adding four new fields in the formula tool (time = 0, surv = 1, upper = 1, lower = 1), deselecting the dummy field, and unioning it in with the survival analysis data output. Then I add a formula tool for that data to label which survival curve it is:
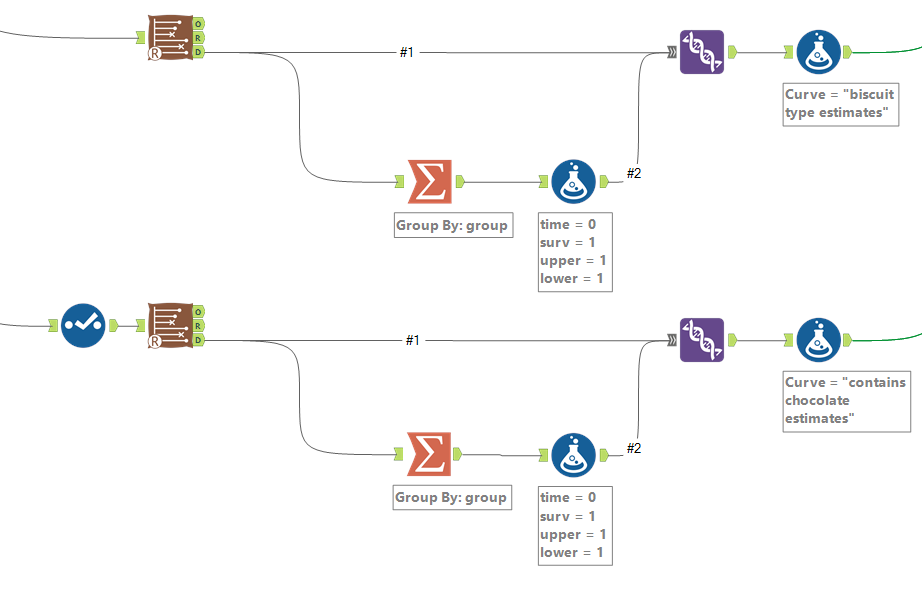
For the survival curves which are split out by a particular field in the group by option, I split off the data output, use a summarise tool to group by the grouping field so that there’s one row per value in the group field, then add the same fields in a formula tool and union these new rows back in. Again, a formula tool after the union is there to label the data for each survival curve:
Then you can union the lot together, and output to Tableau:
This doesn’t cover getting the hazard function or cumulative hazard function. For that, you need to hack the macro itself and add an output to the R tool inside it to put out the data it uses for the cumulative hazard function plot. That’s a topic for another blog.
Now, let’s open this data in Tableau:
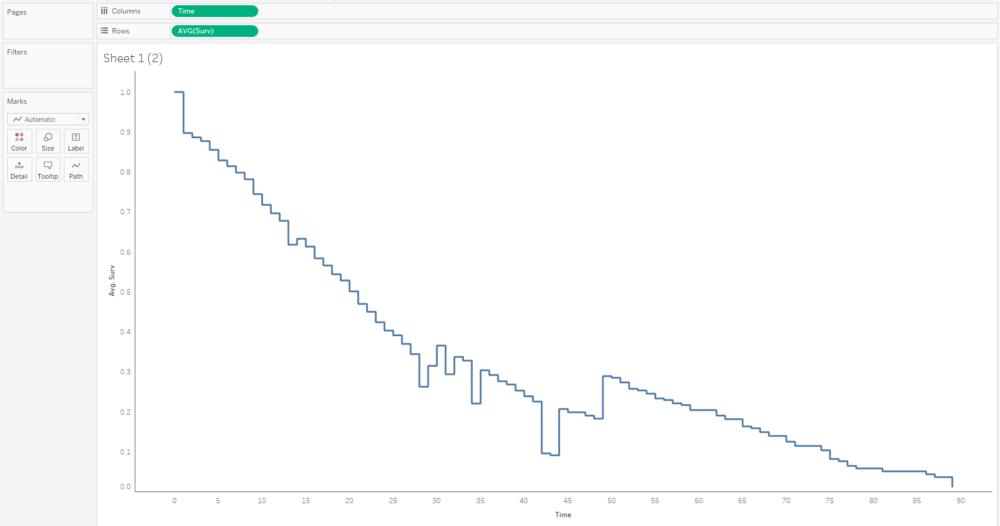
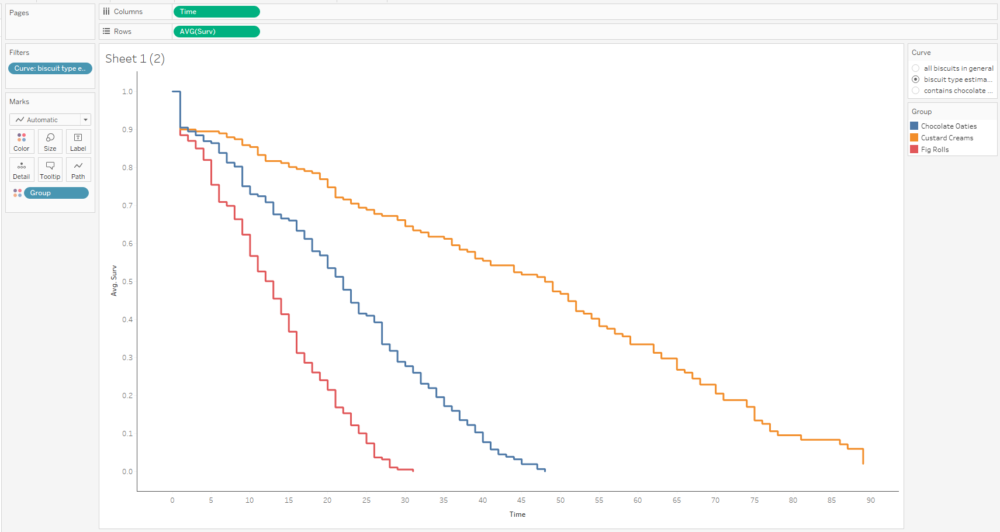
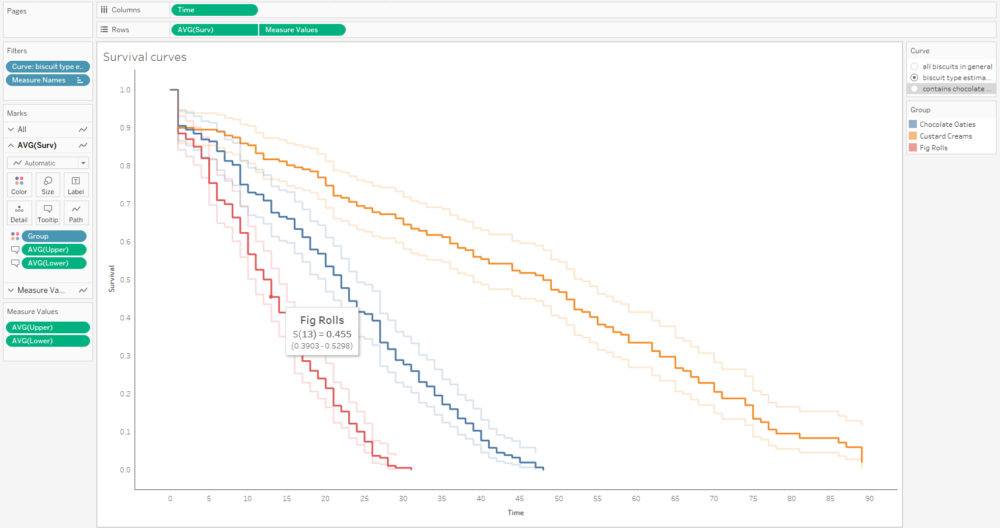
The first step is to plot the average survival function over time. You’ll want your time field to be a continuous measure:
This curve doesn’t make any sense because it seems to jump up and down; that’s because we’ve got several different survival curves in this data, so let’s add a filter to show one at a time:
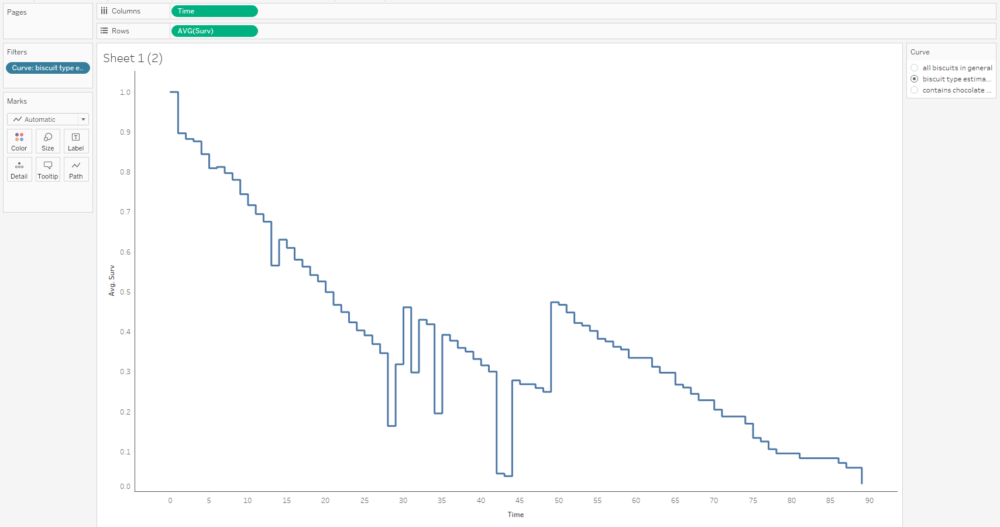
This graph is filtered to the BiscuitType curve only, but it still jumps around because there are three separate curves for the three biscuit types. That means we need to put the grouping field on detail and/or colour too:
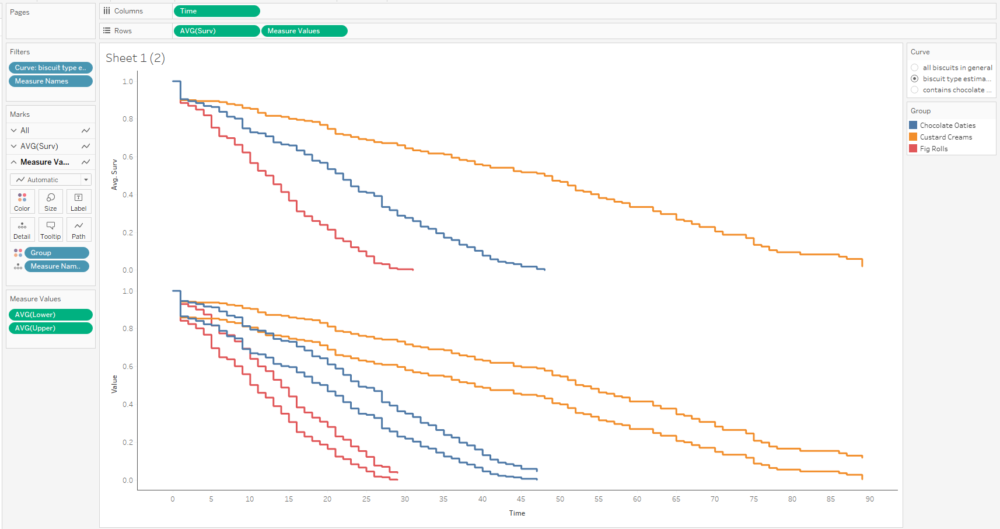
The next step is to add the confidence intervals. I’m going to add them in as measure names/measure values, and then dual axis them with the survival function. In the measure names/measure values step, make sure to put AVG(Lower) and AVG(Upper) together, and put Measure Names on detail with group on colour.
The next step is to put AVG(Surv) and Measure Values on a dual axis, and synchronise it:
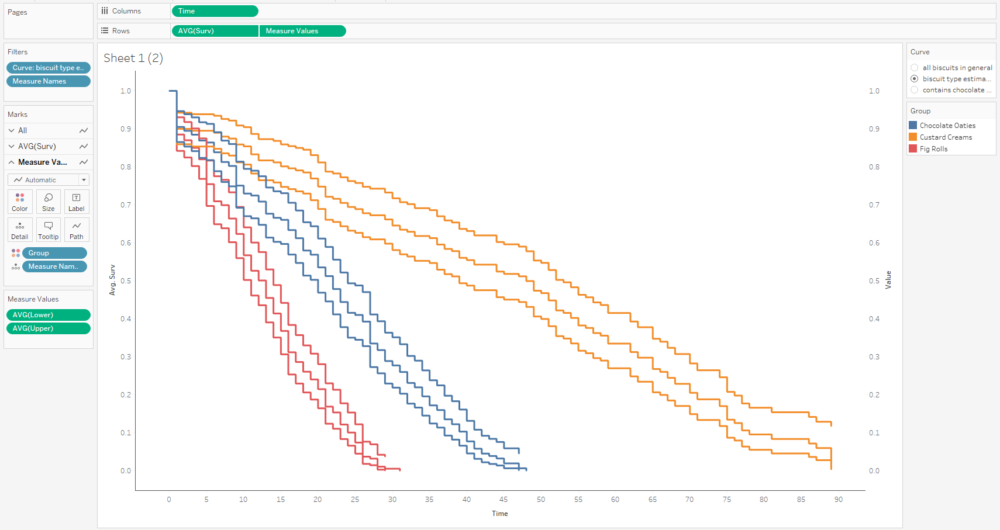
That’s quite nice, but I can’t really distinguish the survival function line that easily, and that’s the most important one. So, I’ll whack the opacity down on the confidence intervals too:
A little bit more formatting and tooltip adjustment, and I’ve got a nice set of survival curves that I can interact with, publish, and share for others to explore:
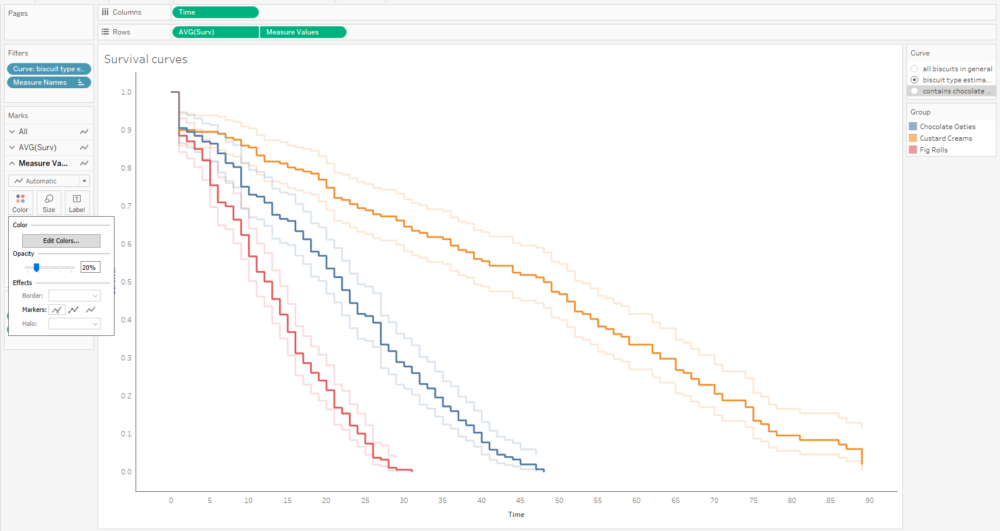
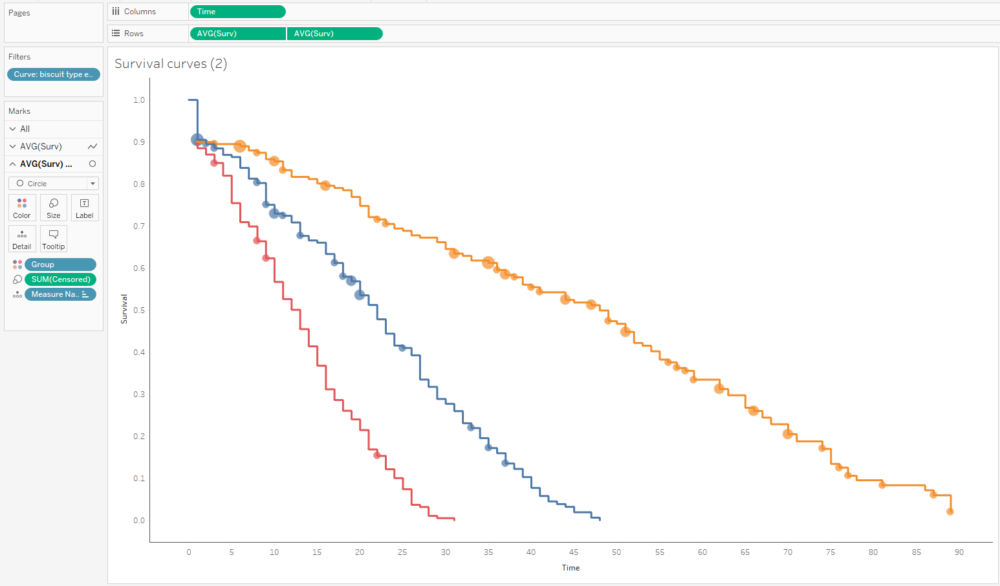
Alternatively, I can plot the number of censored biscuits at each time point as well by plotting AVG(Surv) as circles, and sizing the circles by the number of censored biscuits. The relative lack of censored biscuits for fig rolls in red explains why the confidence intervals are more narrow for fig rolls compared to chocolate oaties and custard creams:
Quite a while ago, I wrote what I thought was a highly-specific blog for a niche use-case – dynamically rounding your Tableau numbers to millions, thousands, billions, or whatever made sense. That ended up being one of my most-viewed blogs.
So today, I’m writing a follow-up. How do you round the number of decimals to a number that actually makes sense?
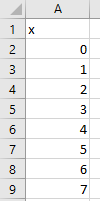
Take this input data:
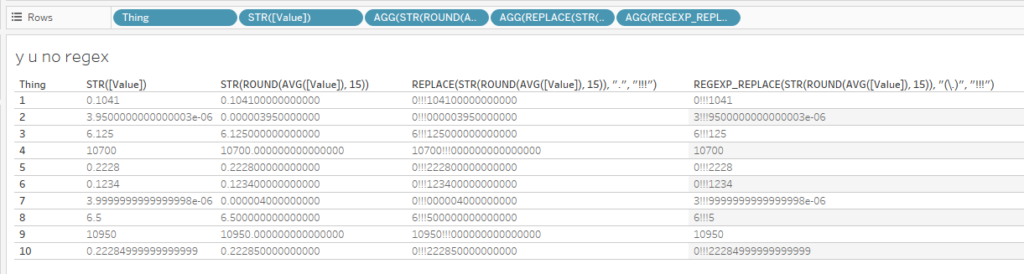
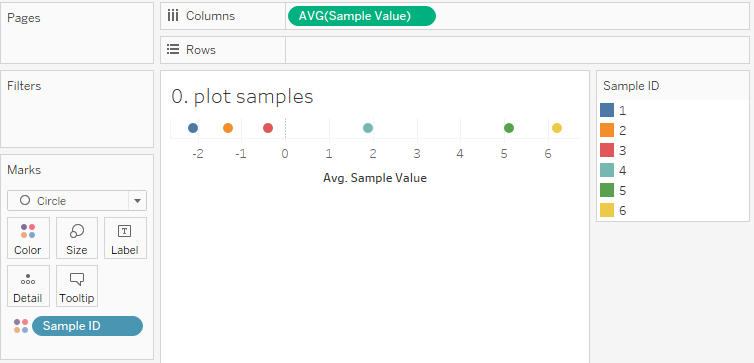
If you plot this in Tableau, it’s normally enough to set the default format to Number (standard). That gives us this:
But if you don’t like the scientific formatting for Thing 2 and 7 in Type b, you’ll have to set the number of decimal places to the right number. But that’ll give you this:
Ew.
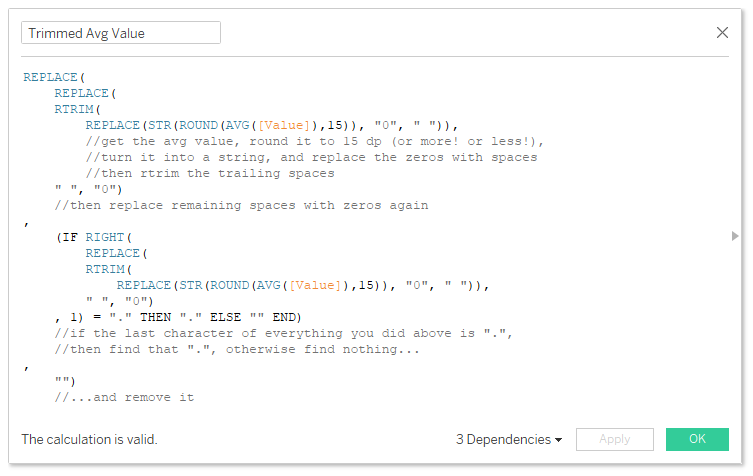
You can get around this with strings. I don’t use this too often, but it comes in handy now and again. Here’s the formula that you can copy/paste and use in your own workbooks:
REPLACE( REPLACE( RTRIM( REPLACE(STR(ROUND(AVG([Value]),15)), "0", " ")), //get the avg value, round it to 15 dp (or more! or less!), //turn it into a string, and replace the zeros with spaces //then rtrim the trailing spaces " ", "0") //then replace remaining spaces with zeros again , (IF RIGHT( REPLACE( RTRIM( REPLACE(STR(ROUND(AVG([Value]),15)), "0", " ")), " ", "0") , 1) = "." THEN "." ELSE "" END) //if the last character of everything you did above is ".", //then find that ".", otherwise find nothing… , "") //…and remove it
Working from inside out, the calculation does this:
Take the AVG() of your field. You’ll want to change this to whichever aggregation makes most sense for your use case. e.g. 6.105
Rounds that aggregation to 15 decimal places. This is almost definitely going to be enough, but hey, you might need to up it to 20 or so. I have never needed to do this. e.g. 6.105000000000000
Turns that into a string. e.g. “6.105000000000000”
Replaces the zeros in the string to spaces. e.g. “6.1 5 ”
Uses RTRIM() to remove all trailing spaces on the right of the string. e.g. “6.1 5”
Replaces any remaining spaces with zeros again. e.g. “6.105”
If the last character of the string is a decimal point, then there are no decimals needed, so it removes that decimal point by replacing it with nothing; otherwise, it leaves it where it is. e.g. “6.105”
And there you go – the number is formatted as a string to the exact number of decimals you’ve got in your Excel file.
Interestingly, there are some differences between the way REPLACE() and REGEX_REPLACE() work. It seems that REPLACE() will wait for the aggregation, rounding, and conversion to string before doing anything, whereas REGEX_REPLACE() will give you the same issues you get as if you just turn a number straight into a string without rounding first.
What are Z scores? How can you calculate them in Tableau? And once you’ve done that, what can you use them for? This blog will cover all of that, using some fake data from a factory that produces things. We’ll have a look at how the things differ from each other across various different manufacturing dimensions, and use that to see what to do with the thing we’re currently building. It’s all in a Tableau Public workbook here.
Firstly, what’s a Z score, and why would we want to use one?
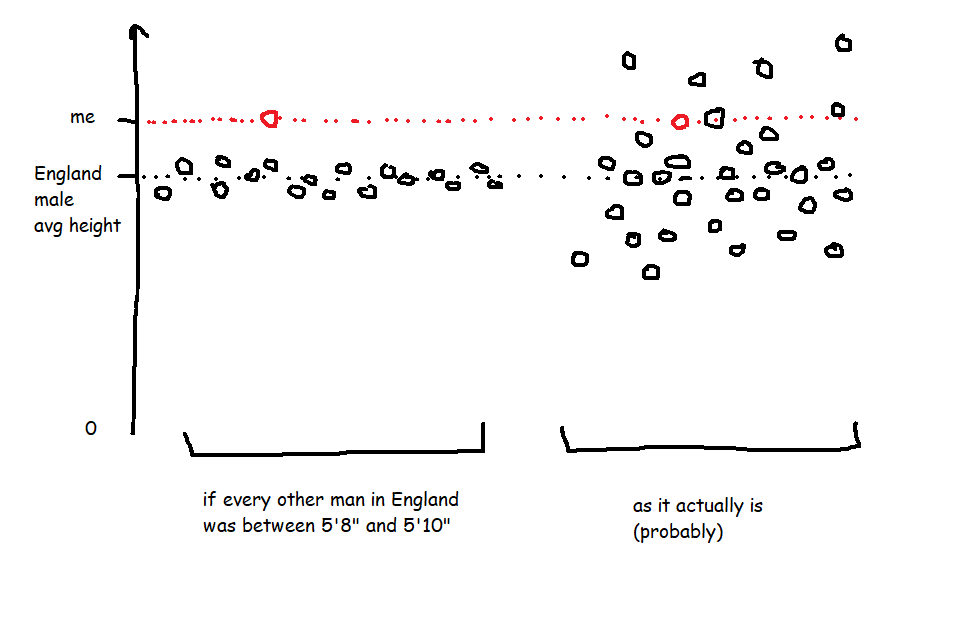
A Z score is a way of looking at how much more, or less, something is from average in a relative way that accounts for the spread of data. For example, let’s start with height. I’m 6’3″ (or 190cm), and I live in England, where, according to wikipedia at the time of writing, the average male height is 5’9″ (or 175cm). That makes me taller than average.
However, averages don’t tell you anything about the spread of data, which means that taking the simple difference in height doesn’t tell you anything about how tall I am relative to everybody else. If every man in England (apart from me) was somewhere between 5’8″ and 5’10”, I’d be an absolute giant, relatively speaking. But as it is, I’m never the tallest guy in the room, so while I’m taller than average, I only feel averagely tall.
This relative difference from average can be expressed in a Z score, which is essentially saying, “how many standard deviations above or below average is this value?”. A Z score is calculated like this:
Value - Average Value / Standard Deviation of Values
So, my height as a Z score compared to men in England would be:
6'3" - 5'9" / Standard Deviation of Heights (which I don't know)
In the hypothetical example where every other man is between 5’8″ and 5’10”, the spread of heights is small, which means that the standard deviation of heights would be really low, which means that my Z score would be really high. But in the real world, the spread of heights is much greater, so the standard deviation of heights is bigger, which means that my Z score is lower.
It also means you can normalise comparisons over different metrics with different scales. Let’s say I’m an Olympic heptathlete. I’m doing seven different events, and the units they’re measured in are different – some are in metres, like the high jump and the shot put, and some are in seconds, like the hurdles and the sprints. The scale of those units is different too – I’ll be able to throw the shot put many times further than I can jump. That makes comparing my performance across my different events difficult! But Z scores let you compare. If my shot put Z score is +2.1 compared to other athletes while my hurdles score is -0.3 compared to other athletes, I know that I need to work on my hurdles more than my shot put.
OK, so Z scores are a way of normalising data to do comparisons. How do I do it in Tableau?
Sets are fantastic for this. Here’s a quick explanation of why before we move onto how to set it all up.
I like using sets to decide which things I’m focusing on (the “I want to know how normal this thing is” group) and which things are in my reference group (the “I want to take this lot as the basis for all my comparisons” group).
A lot of the time, you’ll want all things to be in both groups. For example, if I’m a professional athlete, I want to compare myself to my peer group, and I’ll want to see how my closest rivals compare to the same peer group too. So, I’d stick all the top athletes in my sport in the main group (so I can see their Z scores) and in the reference group (so that I’m comparing everybody to each other).
Actually, I’m very much not a professional athlete… but when I’m out cycling, I might still want to compare myself to the Tour de France pros to see just how out of my league they are. In that case, I’d want all the professional cyclists in the reference group, and I’d want to put myself in the main group, but what I don’t want to do is put myself in the reference group – my slow trundling up Anerley Hill would only bring the reference group’s average performance down and widen the reference group’s standard deviation, and I’d mistakenly make myself look closer to the pros than I actually am.
That’s why I like using sets and set actions in Tableau. Now for the actual Tableau work!
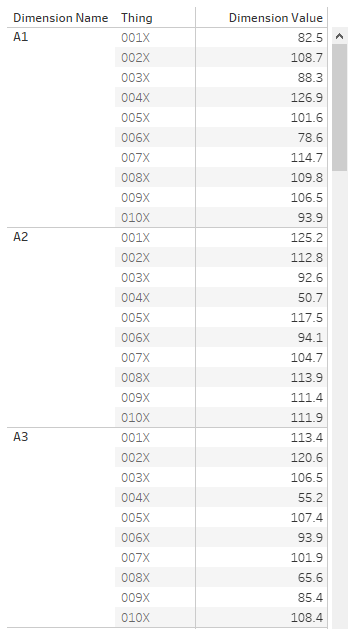
First of all, let’s talk data structure. I’ve got a long and thin data source; a field for the [Dimension Name], a field for the [Thing], and a field for the [Dimension Value]:
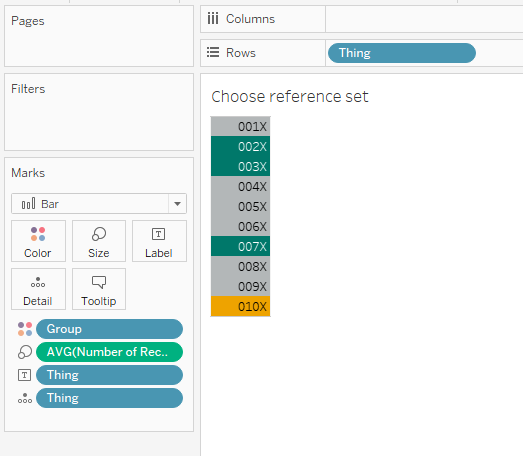
OK. The next step is to set up the sets. I want to create two sets based on my [Thing] field – one for the main analysis set, one for the reference set. You can do this by right-clicking on [Thing] and selecting Create Set.
Now that I’ve got two sets, I can start creating my Z score calculations. The formula for a Z score is:
Value of the thing you want a Z score for - Average value in the reference group / Standard Deviation of values in the reference group
You could do all this in one calculation, but I like breaking mine down into individual parts.
[Reference Set Avg] {FIXED [Dimension Name]: AVG(IF [Reference Set] THEN [Dimension Value] END)}
[Reference Set StDev] IF {FIXED [Dimension Name]: COUNTD(IF [Reference Set] THEN [Dimension Value] END)} =1 THEN 0 ELSE {FIXED [Dimension Name]: STDEV(IF [Reference Set] THEN [Dimension Value] END)} END
Now I can use those two calcs in my Z score calc:
[Z Score] (AVG([Dimension Value]) - AVG([Reference Set Avg])) / AVG([Reference Set Stdev])
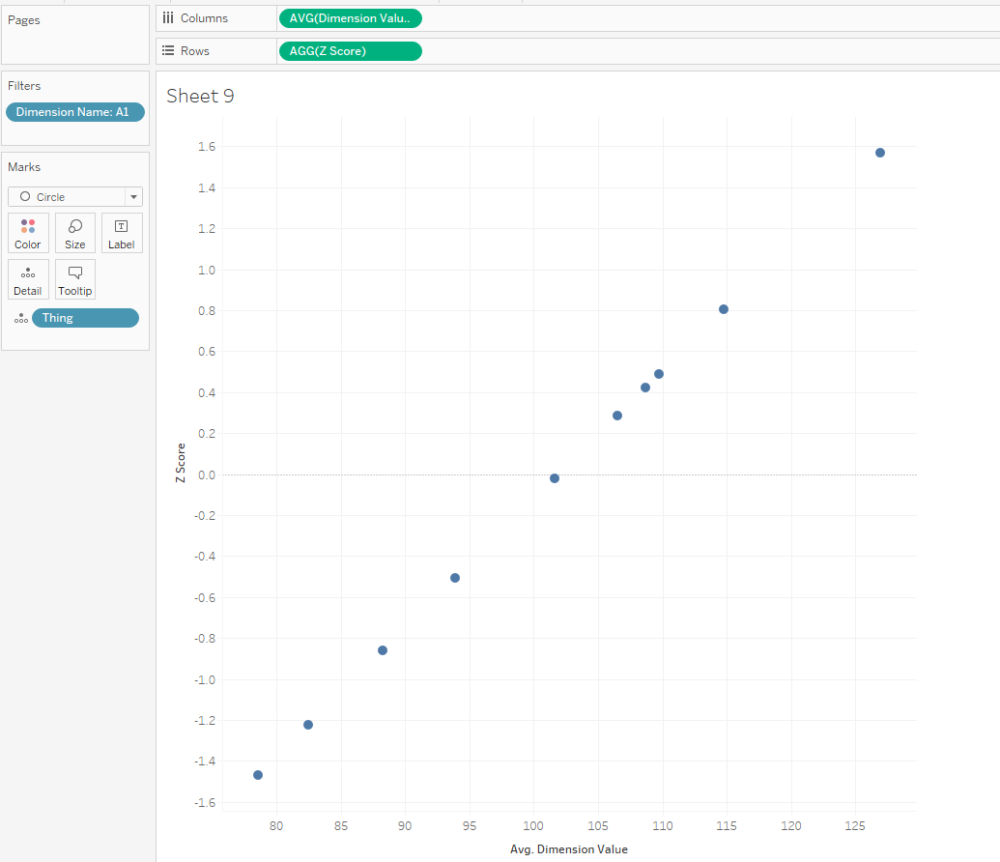
That’s all it takes to calculate Z scores! Here’s a scatterplot of my dimension A1. The actual dimension value and the Z score are perfectly correlated, but now we’ve got a normalised value on the y-axis:
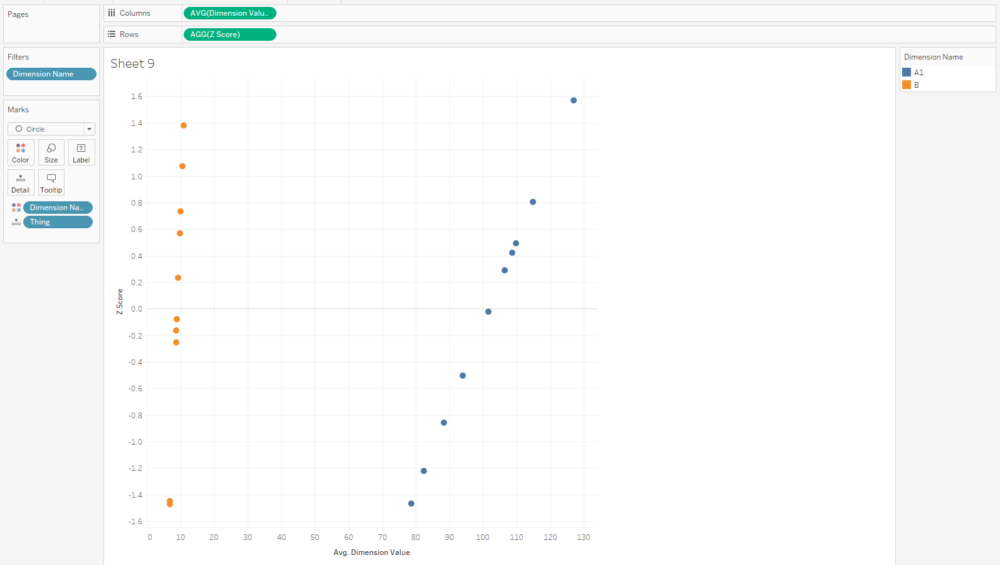
And that normalised value is nice and useful, because now we can compare two dimensions with very different scales, like A1 and B:
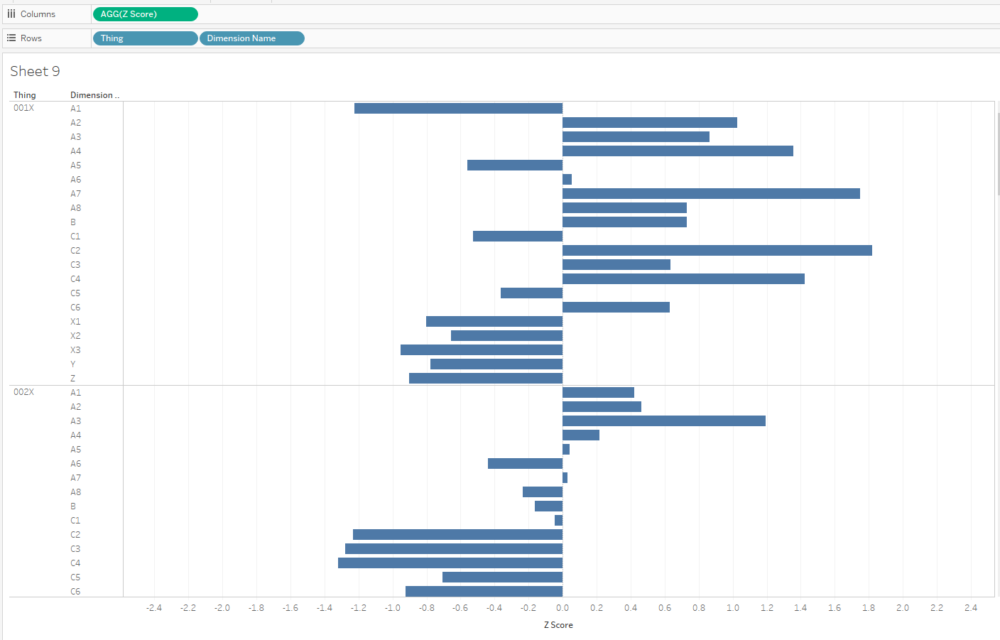
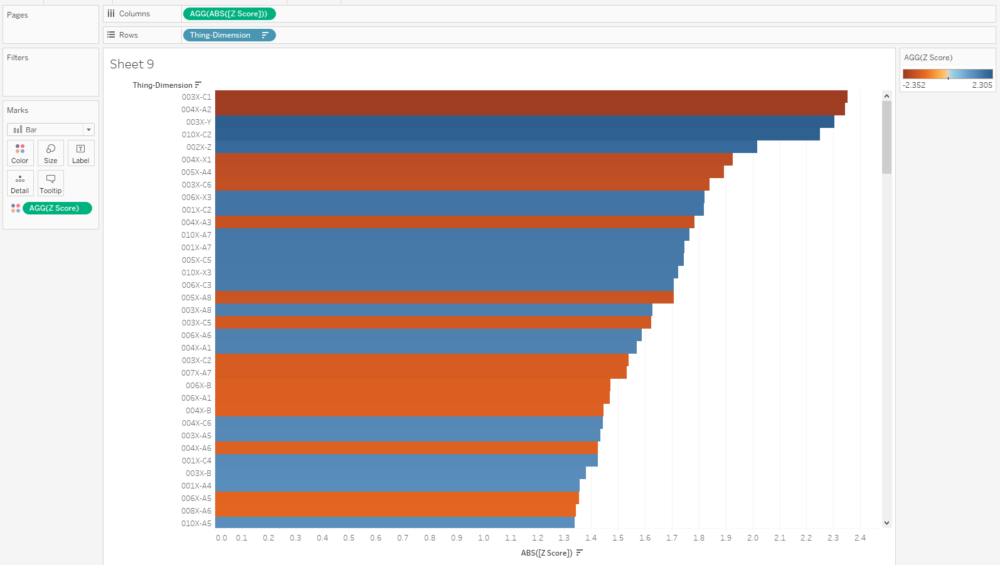
I often plot Z scores on diverging bar charts. A chart like this will show me how a thing compares to other things across multiple dimensions, and a thing’s idiosyncrasies will stick out:
Similarly, if I want to see what the outliers are across a whole data set, I can create a concatenated [Thing-Dimension] field, plot the absolute Z score, colour by the actual Z score, and sort. This instantly shows me where the biggest outliers in my data are:
Eagle-eyed readers may have noticed that I haven’t calculated a separate field for the analysis set, and I’m just using AVG([Dimension Value]) in the numerator. That’ll calculate the Z score for any [Thing] in the view regardless of whether it’s in the analysis set or not, so those readers may be wondering why we need the analysis set at all. Never fear, we’ll use this set in some more advanced calculations that are coming up.
Making Z scores interactive
With a few extra steps, you can create two sheets to use as set member choosers (I think that drop-down set controllers are coming in 2020.2 or 2020.3, which is exciting! But for now, I’m in 2020.1, and this is the workaround we need to update set membership).
I set up my reference set chooser sheet like this:
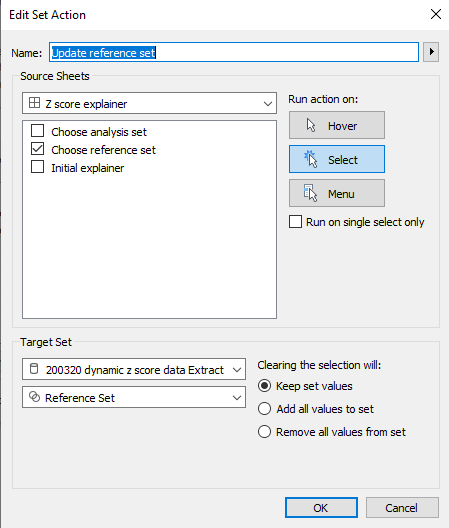
…and then the dashboard action like this:
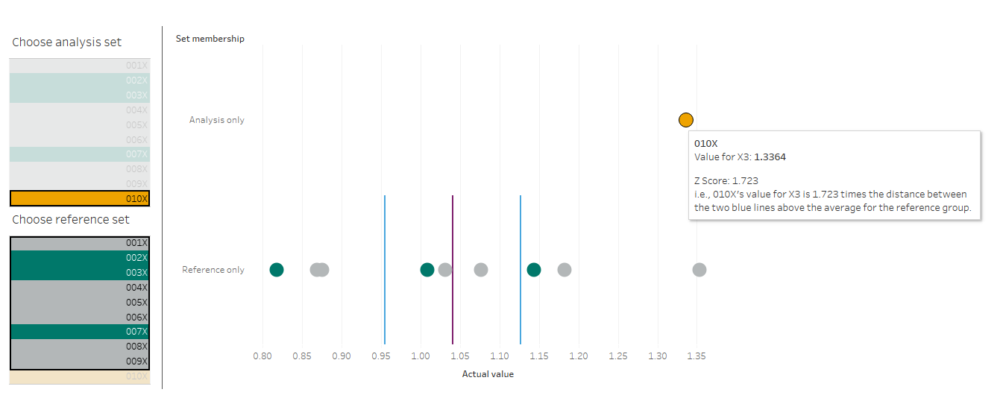
Repeat for the analysis set, and you can build a dashboard a bit like this (click the image to see the interactive version on Tableau Public):
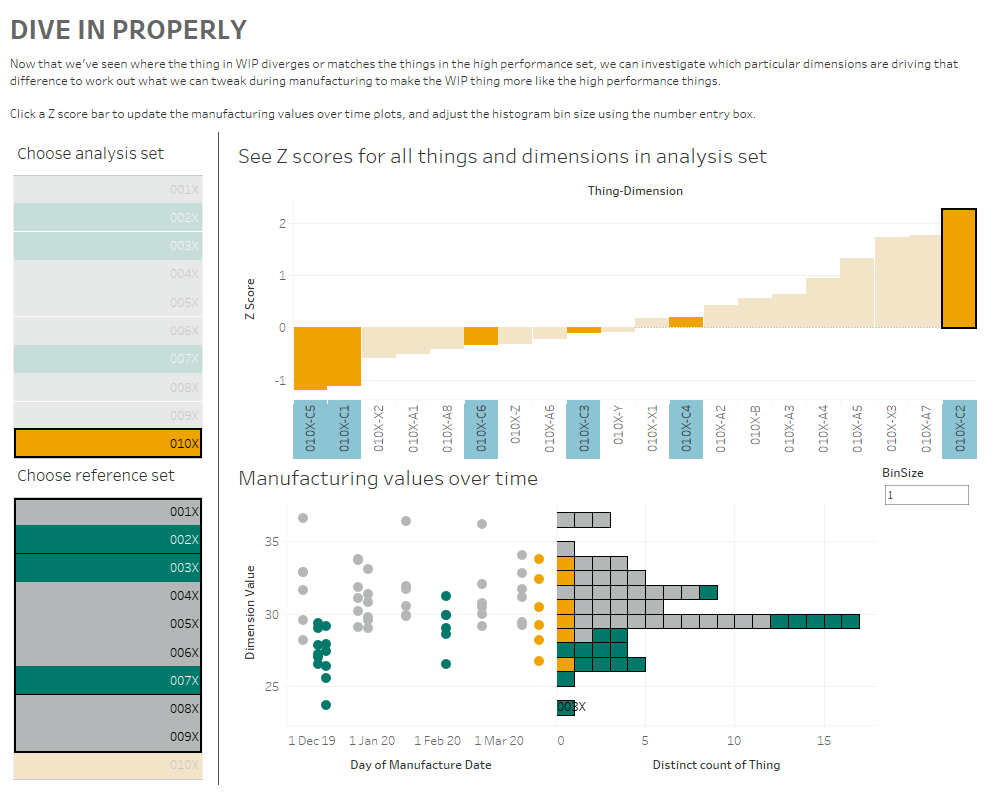
I’m using this to select an individual dimension, and then looking at how 010X compares to 001X through 009X. I’m plotting the actual value on the x-axis, because that’s what I’ll have to adjust in the factory if I decide to make any changes, and I’ve included the Z score in the tooltip.
The nice thing about using sets and set actions is that we can update these Z scores by changing the reference set. Maybe we’ll find out that one of our things, say, 004X, was actually faulty and shouldn’t be included in our set of “normal” things that we’re using as a reference. Do we need to re-run our entire data pipeline? Nope, just deselect it from our reference group selector.
Next steps: comparing Z scores
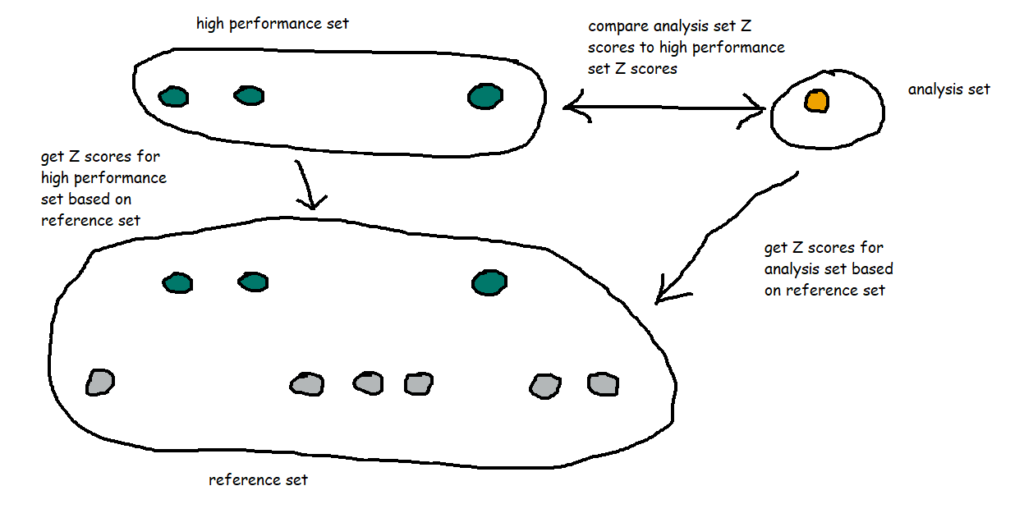
That’s nice and everything, but let’s take it a bit further. I know that 002X, 003X, and 007X were particularly good things, and ideally, all the things I manufacture in future will be like those three. So, I’ve created a new set called [High performance set], and I want to compare my WIP thing 010X to the high performance set based on the same reference set I selected earlier.
That means I’ve got a lot of comparisons going on:
I also want to group my dimensions into themes. For example, A1 through A8 are technically separate dimensions, but they represent the same kind of thing taken at different points – maybe it’s the thickness of a circular plate at eight different points around the circumference of the plate, or maybe it’s the weight of eight different ball bearings in the same part of the thing, or something like that. So, since they’re all related, I want to see how 010X compares to the high performance set across the A dimensions as a group of dimensions. In my workbook, I’ve simply grouped them by regex-ing out any numbers from the dimension name.
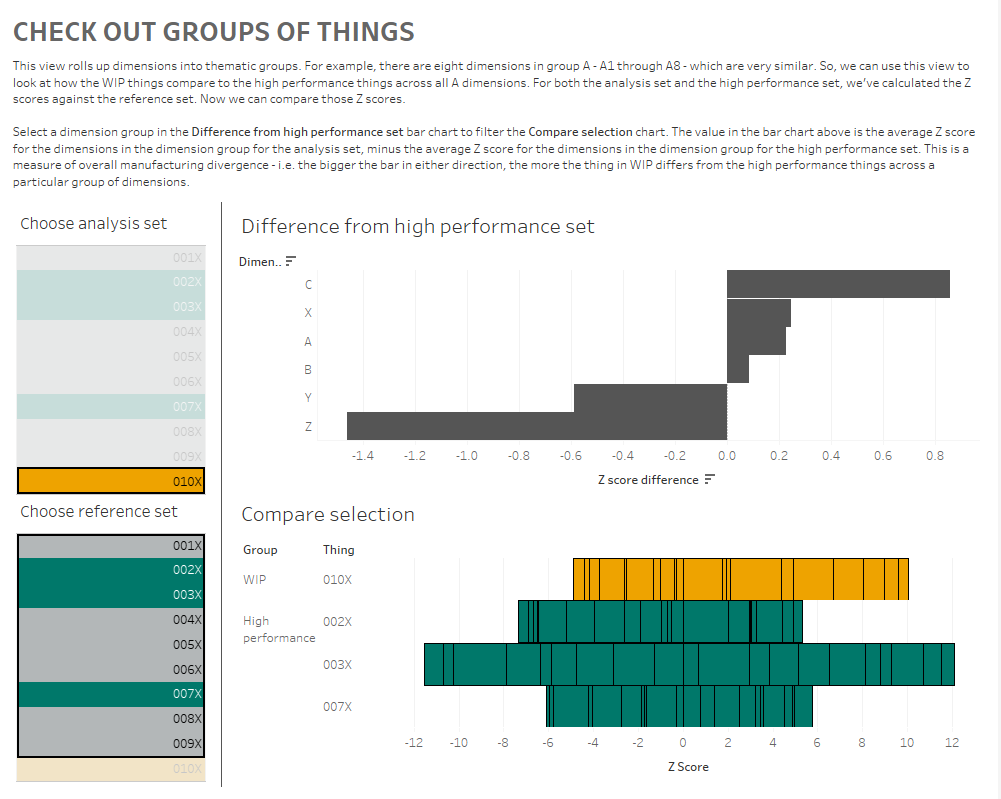
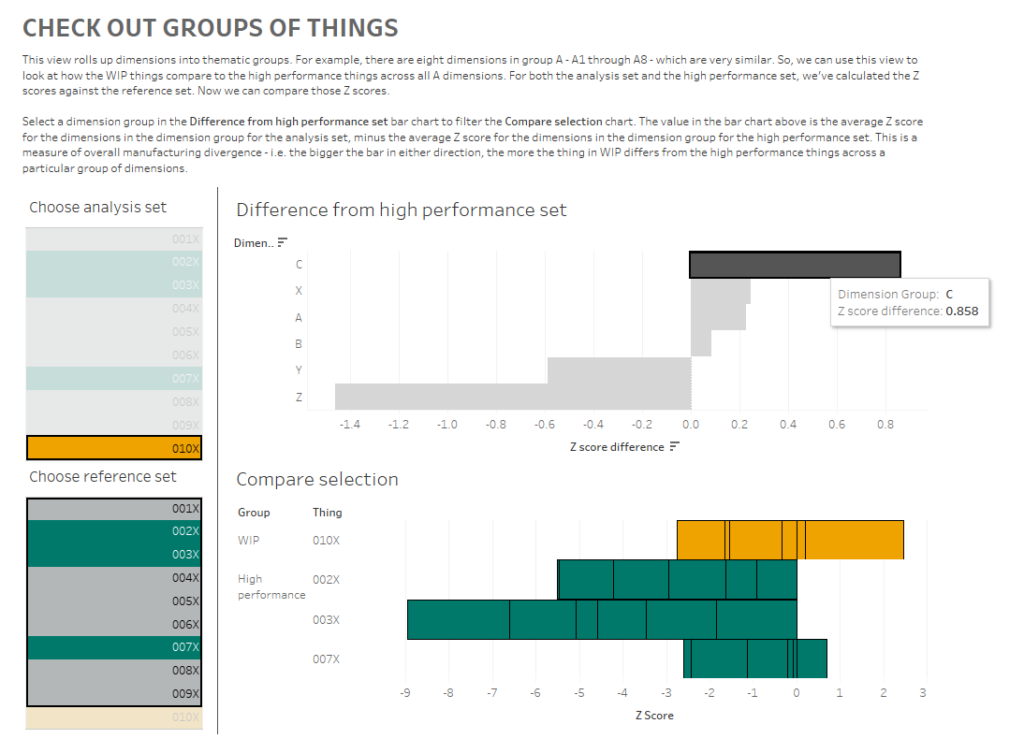
I’ve created a dashboard like this (click for interactive version):
What am I doing here? In the bar chart at the top, I can see how the Z scores for 010X compares to the Z scores for the high performance set for each group of dimensions. I’m finding the Z score for each dimension within a dimension group, and comparing the average Z score for each dimension group for the analysis and high performance sets.
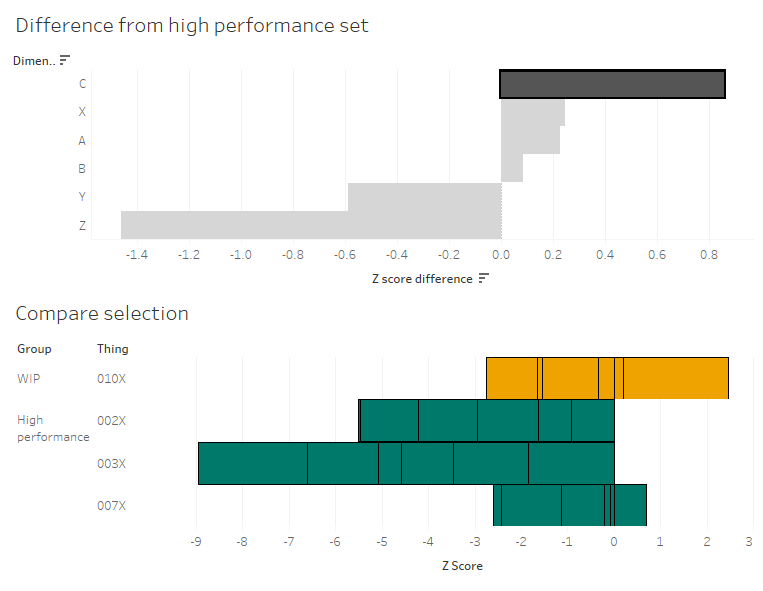
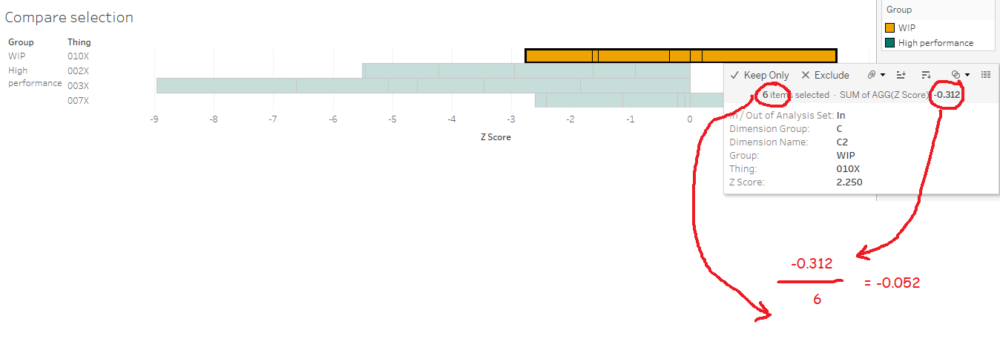
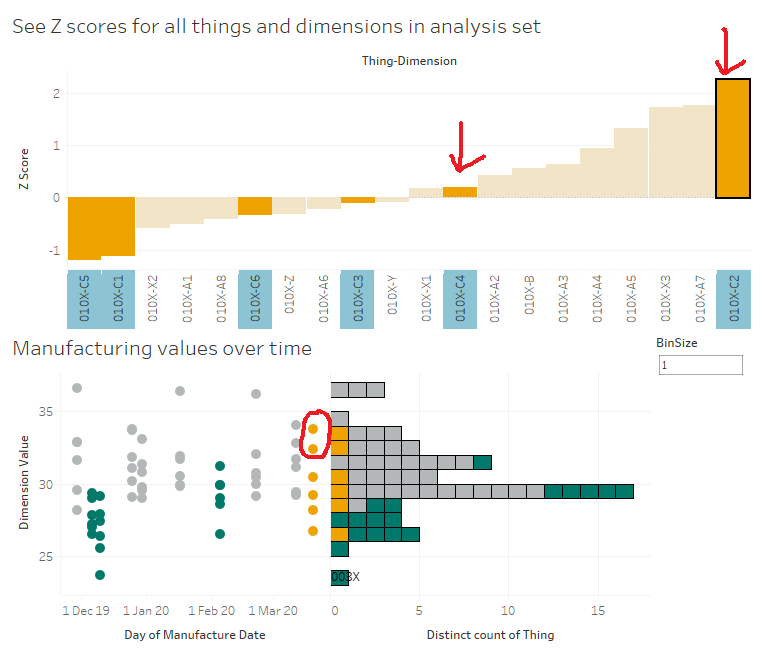
What I’m seeing here is that, on average, the C dimensions in 010X are higher than the high performance set. If I click the C bar, it’ll filter the “compare selection” chart:
This stacked bar chart shows me the Z scores for all C dimensions for the things in the analysis and high performance sets. This is telling me that the high performance things tended to have C dimensions lower than normal across the reference group, and that while 010X also has some C dimensions on the lower side of normal, it’s not as low as the high performance group. So, maybe my manufacturing specifications for the C dimensions are actually a bit high, and I should tune them lower if I want more high performance things.
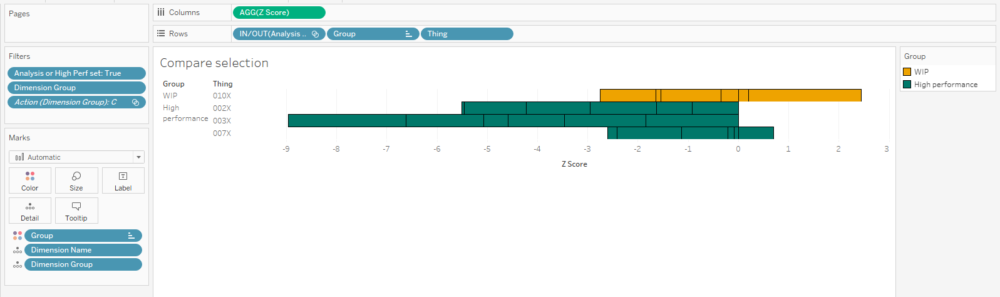
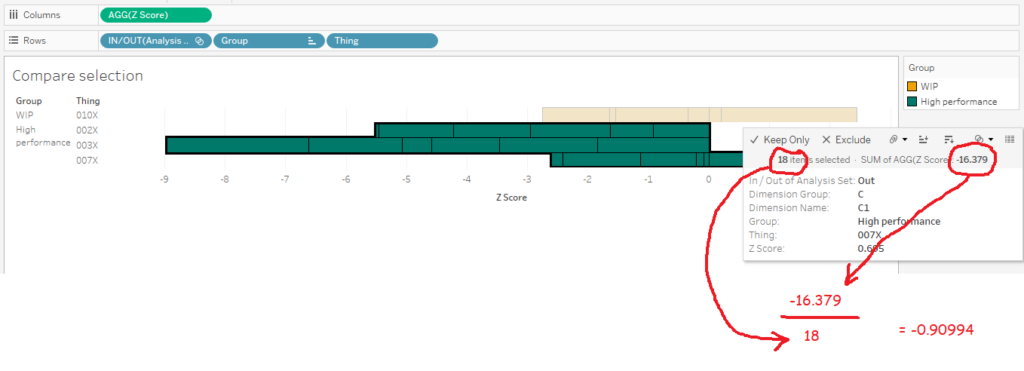
Building the “compare selection” chart is relatively straightforward – put the [Z score] field on columns, and stack your rows with the Group and Thing dimensions, as well as the IN/OUT value of the analysis set so that it’s sorted nicely:
I’ve also created a calculation that returns a T/F value based on set membership and I’m using it to filter the view. It’s simply:
[Analysis or High Perf set] [Analysis Set] OR [High performance set]
…and I’ve set the filter to TRUE.
The tricky bit is getting the values for the diverging bar chart. I like using the compare selection sheet as a way of checking the calculations. What we want to work out is the average Z score across all things and dimensions for the analysis set, and the average Z score across all things and dimensions for the high performance set. Then we want to take the analysis set average and subtract the high performance set average to see the difference.
In other words, we want this:
…minus this:
…which should give me 0.857944.
The first thing we need to do is to create a new field: [Thing-Dimension]. It’s just a concatenated field of [Thing] and [Dimension Name], like this:
To be able to plot the average Z scores and difference in a simple bar chart for each dimension group, we can’t have the thing or dimension in the view, which means we need an LOD which includes those fields:
[Z score (LOD include Thing-Dimension)] ( {INCLUDE [Thing-Dimension]: AVG([Dimension Value])} - {INCLUDE [Thing-Dimension]: AVG([Reference Set Avg])} ) / {INCLUDE [Thing-Dimension]:AVG([Reference Set Stdev])}
Now we can use that field to work out the difference between our sets:
[Z score difference] AVG(IF [Analysis Set] THEN [Z score (LOD include Thing-Dimension)] END) - AVG (IF [High performance set] THEN [Z score (LOD include Thing-Dimension)] END
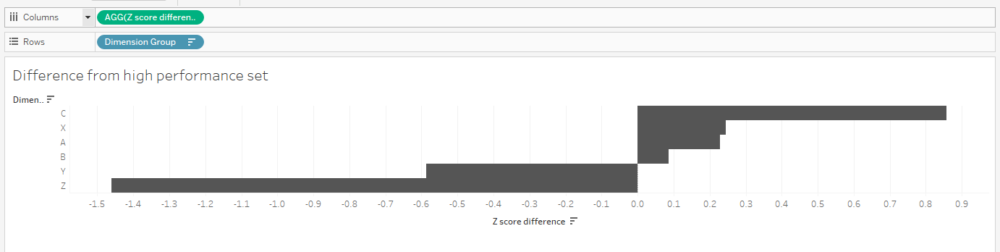
Finally, we can create our bar chart! And it’s nice and simple:
Let’s just check the calc works. Is it 0.857944, as I worked out manually earlier on? Yup, it’s showing up as 0.858 in my tooltip. Lovely:
Now that I’ve compared Z scores across groups of dimensions to get an idea of the general way that my things compare to each other, I can dive back into the actual data to look at what those differences are and potentially fix my manufacturing variance.
Here’s my final dashboard (again, click for the interactive version). I’ve plotted the Z scores for all dimensions for 010X, and I can click any of those Z scores to update the scatterplot and marginal histogram of actual values below. I know that the C dimensions are a bit different for 010X in comparison to the high performance set, so let’s have a look at those:
I can look at that scatterplot and instantly see which of the C dimensions are driving that difference between 010X and the high performance set:
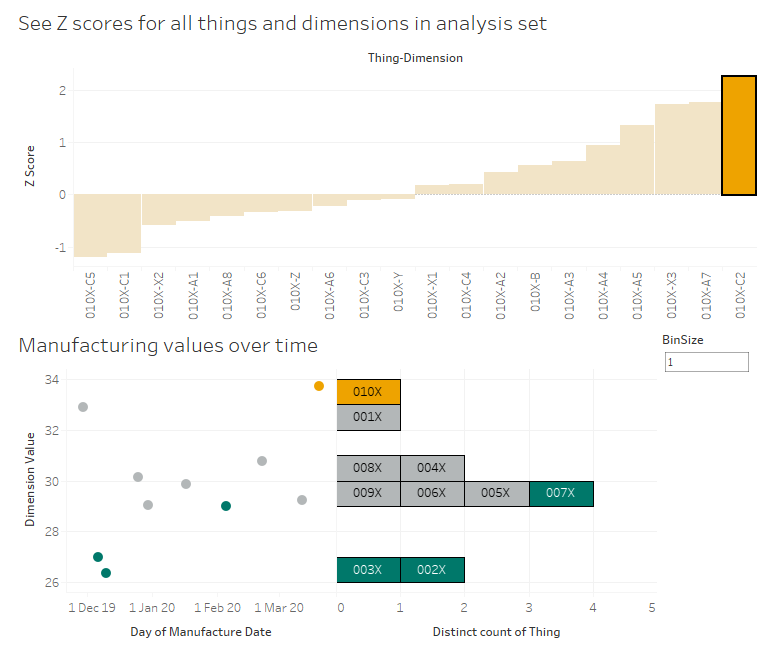
It’s dimensions C2 and C4.
Let’s start with C2. 010X has a high Z score of 2.25, and we can see in the scatterplot that this is a higher value than normal. As it is, that should be raising flags in the factory – that’s a high C2 value, both absolutely and relatively, so we should probably turn it down a bit to be more in line with the others at around 30. As an aside, it’s interesting to see that the high performance set all have low C2 values, so maybe we should turn it down lower than 30 to be closer to the high performance set:
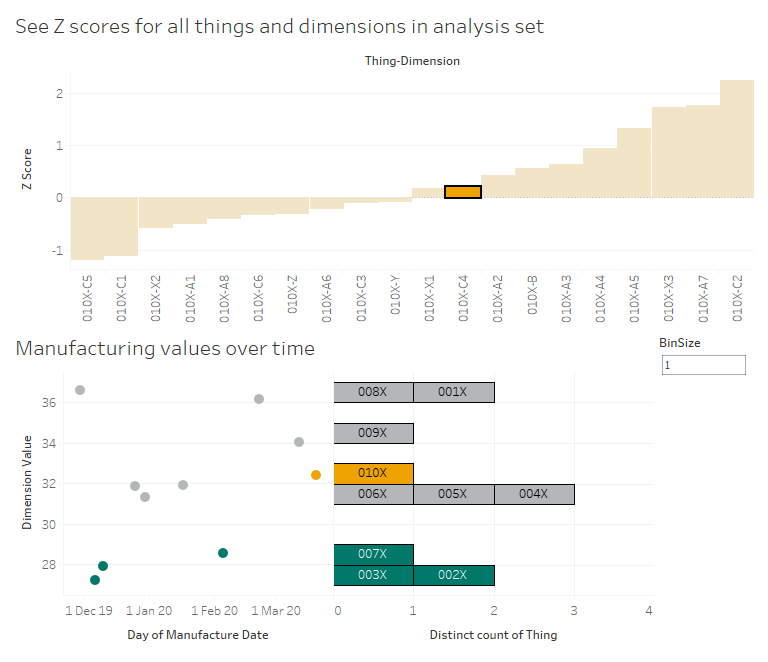
Now, let’s have a look at C4. No issues there, right? 010X has a C4 value which is slightly higher than the average for the reference group, but the Z score is only 0.198, which indicates that it’s pretty much bang on normal. However, we can see that even though it’s normal for the reference group, it’s quite a lot higher than the high performance group. So, again, maybe we’re manufacturing C4 to a specification that says “aim for a C4 value between 30 and 34”, whereas we should consider amending those limits to between 26 and 30 based on how the lowest C4 values have all been the high performance things:
This is just a few of many different ways you can use Z scores and Tableau to look at manufacturing data. There are all kinds of interesting use cases out there – hopefully this explainer helps you build some of your own.
This isn’t my favourite use of Tableau by any stretch of the imagination, but it’s something that comes up now and again when doing Tableau consulting:
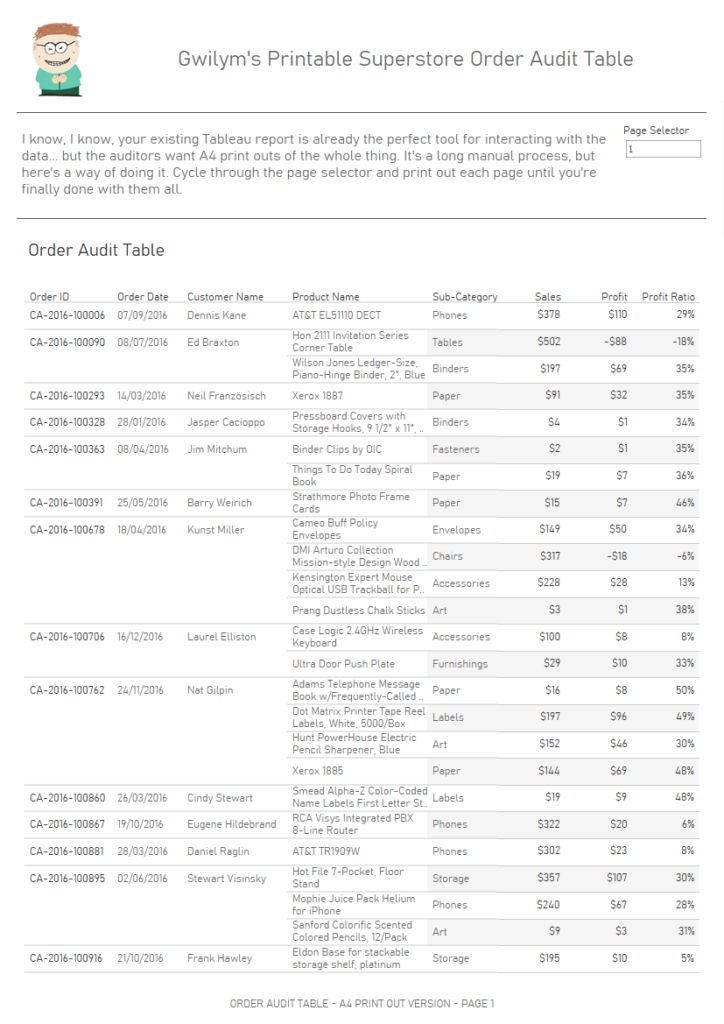
“I’ve got a massive table, which is fine to scroll through online, but I can’t print it. How can I print out this table over multiple pages while keeping all the dashboard formatting and the column headers?”.
My solution to this uses a parameter and a running total calculation using the [Number of Records] field. You can download my workbook from Tableau Public here, and then follow the instructions below.
First of all, let’s create a big old table, something a little like this:
It’s got almost 10,000 rows in it. That’s fine when you’ve got an interactive scroll bar and you’re working with it online, but not so much if you need to create static print outs.
So, the next step is to find a way of making it into pages. What I want to do is put the table on a dashboard, like this:
…and instead of having a scroll bar, I want to fit the data to however many rows fit on the dashboard, and then repeat that dashboard as many times as necessary.
Let’s bring in the AVG([Number of Records]), and switch it to discrete so it functions like a row number where the row number is 1 for each row:
Now let’s add a running total table calculation to it, computing along Table (down). This gives us a dynamic Row ID:
The next step is to create a parameter to select the page number. You’ll need to make it an integer with any allowable value.
Now, we can divide the table into pages. I’ve decided that I’d like to show 25 rows on each page, mostly because that’s an easy number to work with in my head – I know that there’ll be 4 pages for each 100 rows in the data.
We can use the following logic to determine where my 25 row pages start and end:
((RUNNING_SUM(AVG([Number of Records]))-1) / 25) + 1
This is a few more brackets than are technically necessary, but I find that it clarifies the purpose of the calculation. It takes the dynamic Row ID we’ve created, and subtracts 1 from it, so that it goes like 0, 1, 2, 3… instead of 1, 2, 3, 4… and so on. Then, it divides that number by 25, which is the number of rows I want in each table page. Finally, it adds 1 to the whole thing.
This tells us where each page will be:
Why does it subtract 1 and then add 1 again? The first -1 is in order to make sure that all pages have the same number of rows on them. If the Row ID begins on 1, then the first page will always have one row fewer on it, as it’ll take rows 1-24, then the second page will take rows 25-49. Subtracting 1 means that the first page will take rows 0-24, then the second page will take rows 25-49. Then, after dividing the Row IDs by 25, the first page will have a number between 0 and 1. Talking about the first page as page 0 and the second page as page 1 always gets confusing, so I’ve added 1 back on to make it more intuitive.
Now that we’ve got that logic understood, we can create a Page Filter calculated field:
((RUNNING_SUM(AVG([Number of Records]))-1) / 25) + 1 >= [Page Selector] AND ((RUNNING_SUM(AVG([Number of Records]))-1) / 25) + 1 < [Page Selector] + 1
This filters the table to whichever page you’ve selected in the page selection parameter. So, if you’ve selected page 4, it’ll give you all values where the Row ID divided by the number of rows you want per page is >= 4 and < 5. This corresponds to rows 76-100.
Now that the filter is set up correctly, we can get rid of the first two columns in this table entirely and leave it to work in the background. You can put the new version of your table into a dashboard along with the page selector parameter. Tableau also lets you set the dashboard size to common printer paper sizes, so I’ve set this to A4 portrait:
Now, if you need to print out the entire table in a consistent format, you can cycle through all the pages and print them individually. This will obviously take a lot of time for big tables, and it won’t be a pleasant experience, but it does at least make it possible for you!
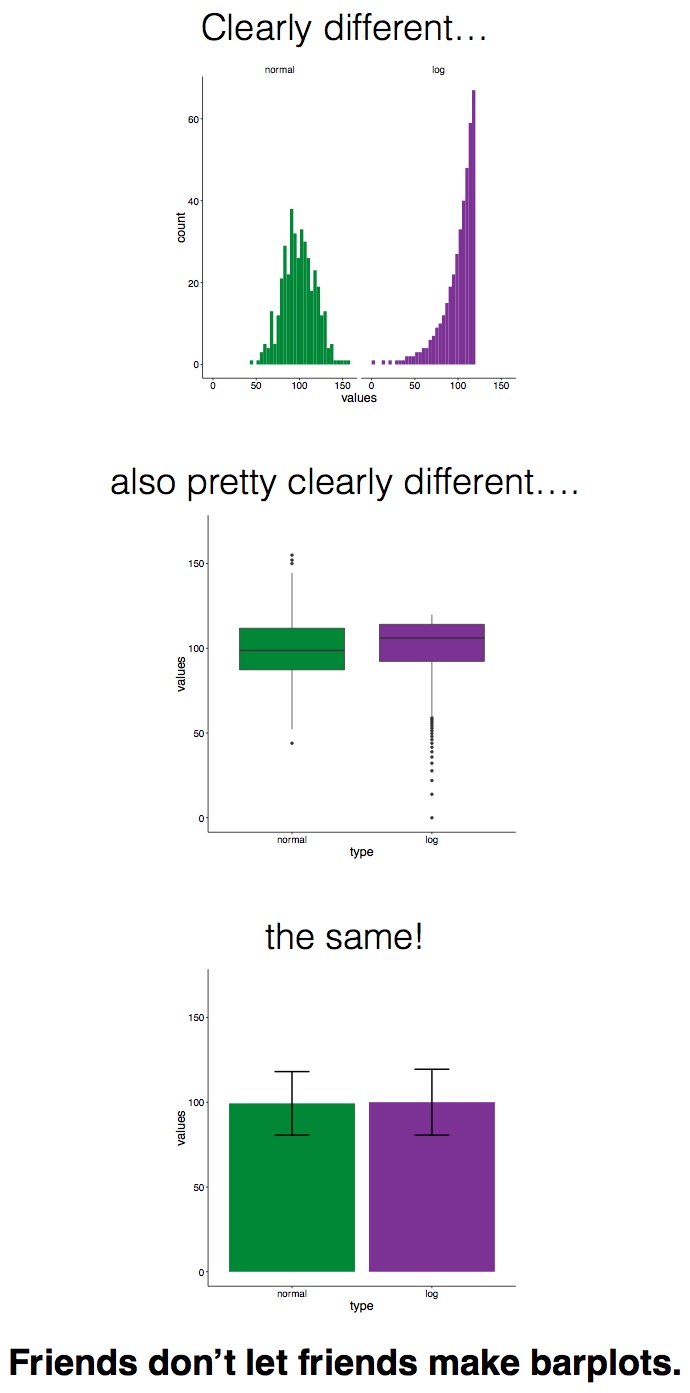
Sometimes when you plot values on a graph, you want to show not only the aggregated value, but also the variance or uncertainty around it. Now, before I get into this blog properly, I want to say that I don’t actually recommend plotting bar graphs with error bars or confidence intervals, as it can be misleading. The Bar Bar Plots campaign has far more information on it, but ultimately it’s more honest, and really straightforward, to show the actual data points in Tableau, so why wouldn’t you just do that?
Friends don’t let friends make barplots – solid advice from Page Piccinini.
But in the event that you do need to show simple bars and an indication of uncertainty, you’ve got two main options:
Standard errors
Confidence intervals
Introduction to the data
I’m going to use some data I collected during an experiment I ran in 2015. In this experiment, Dutch people learned some Japanese ideophones (vividly descriptive words). But there was a catch – half the words they learned were with the real meanings (e.g. fuwafuwa, which means “fluffy”, and they learned that it meant “pluizig”), and half the words they learned were with the opposite meanings (e.g. debudebu, which means “fat”, but they learned that it meant “dun”, or “thin”). Then they did a quick test to see if they remembered the word associations correctly. You can read more about that here, if you like.
All the following graphs in this blog have been created in this workbook on Tableau Public. Please feel free to download and explore how it’s all made!
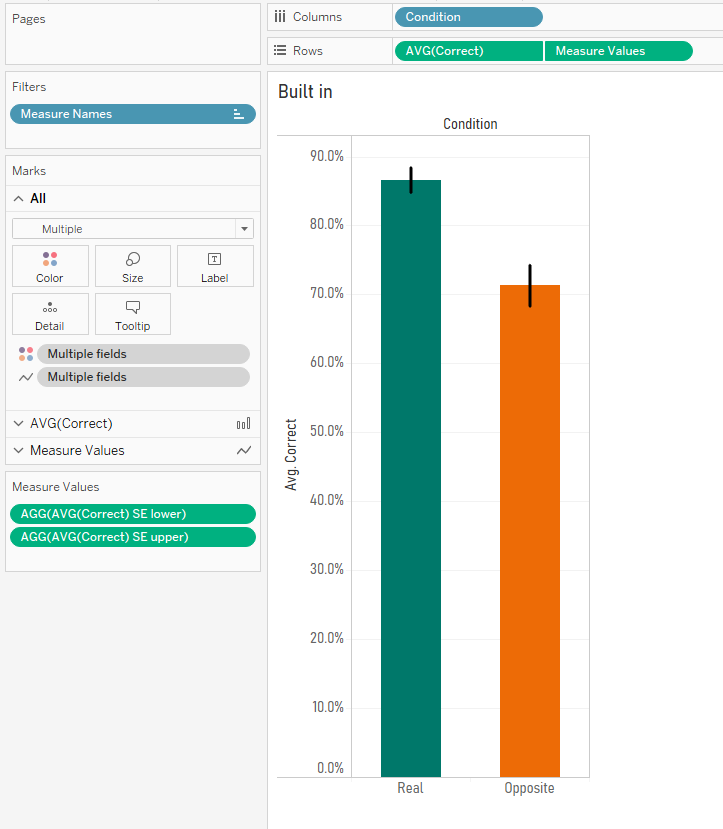
Here’s a simple bar graph of the results. For the words they learned with their real meanings, people answered correctly in the test round 86.7% of the time. But when tested on the words they learned with their opposite meanings, people answered correctly only 71.3% of the time.
But this hides the variation in the data. Sure, the average in each condition (and the difference between them) is what I care about, but with simple bar graphs, it’s easy to forget that lots of individual people are below and above the average in each condition. You can see that variation here:
Also, these are averages taken from a sample. I can’t go to a conference and say, “hey everybody, I’ve done the research and Dutch undergrads get 86.7% correct in the real condition and only 71.3% in the opposite condition”… well, I could, but it would be misleading. I can’t guarantee that these results are definitely in line with what the entire population of Dutch undergrads would get if I somehow managed to test all of them, so I need to make some kind of statement about the uncertainty of that result. I can do this with standard errors or confidence intervals.
Standard errors
Let’s start with standard errors. The standard error of the mean is essentially a way of saying how uncertain you are about the mean based on the size of your sample by estimating the standard deviation of the whole population. The wikipedia article on standard errors is pretty good.
The first step is to create a field for the standard error. This is the standard deviation of the scores per condition, divided by the square root of the number of participants:
STDEV([Correct]) / SQRT(COUNTD([Participant]))
You’ll notice I’ve also got fields for the sample standard deviation and the not sample standard deviation. This is from when I was playing around with different calculations for the standard deviation of the sample vs. the standard deviation of the population. I’m not going to go into it in this blog, but here’s a really nice explainer here, and you can download the workbook to investigate further. In summary, it looks like Tableau’s native STDEV() function uses the formula for the corrected sample standard deviation by default, rather than the population standard deviation. This is pretty nice, it feels like a safer assumption to make. Cheers, Tableau.
Now that we’ve got the standard error, we can create new fields for our upper and lower standard error limits like this:
AVG([Correct]) – [SE] and AVG([Correct]) + [SE]
So, now we can create some nice standard error bars. This uses a combination of measure names/values and dual axes, so it’s a little bit complicated. Firstly, create your simple bars for the correct % per condition:
Now, drag the lower standard error field onto rows to create a separate graph. Drag the upper standard error field onto the same axis of that new graph to set up a measure names/measure values situation:
Now, switch the measure values mark type to line, and drag measure values from columns and drop it on the path card:
All you have to do now is create a dual axis graph, synchronise the axes, and remove condition from colour on the standard error lines:
Great! We’ve now got bar graphs with standard error bars. I mean, I still don’t recommend doing this, but it’s a common request.
Confidence intervals
Now, let’s have a look at confidence intervals. They are a range around your sample mean which tell you that, if you repeated the same study over and over, X% (usually 95%) of confidence intervals from future studies will contain the true population mean. They’re hard to explain (there’s a good blog here), but easy to see.
In Tableau, confidence intervals are really straightforward. You can plot your data points, go to the analytics pane, and bring in an “average with 95% CI” reference line, which creates a reference band around the average:
Nice. This is exactly how I’d like to visualise my experimental data! You can see the average per condition, the confidence intervals, and the underlying participant data.
Quick disclaimer: because I’m looking at percentages here, this is a proportion rather than a hard and fast value, so I shouldn’t actually be using confidence intervals at all… but if we pretend that the 86.7% value is actually an average 0.867 value of something like my participants taking 0.867 seconds taken to respond, or young children being 0.867 metres tall at a certain age, or 0.867 kg lost for each week under a new diet plan, then it’s okay. I’m just going to keep going with my percentages, but please bear this in mind.
However, if your journal insists on old school bar graphs, Tableau’s built in average with 95% CI reference band won’t work. Well, technically it will, it’s just that it’ll show you this:
Because we’ve had to take Participant off detail in order to show an aggregation across participants, the reference band doesn’t know how to compute it, and it assumes that there’s just one data point.
One way around this would to built a dual axis graph. Keep the bars with just condition on colour, and create another axis. Add participant to detail, and set the mark type to circle. Make the circles as small as possible and completely transparent, hit dual axis, synchronise axes, and voila. Now you can have an average with 95% CI reference band again.
The downside is that this is pretty ugly. The reference line/band is way outside the edges of the bars, and it just doesn’t have that standard look that you’re used to. What we actually want is something like our standard error lines from earlier, but with confidence intervals.
The good news is that we can do it! But we’ll have to move away from Tableau’s built in confidence intervals, and create our own calculation, just like we did with standard errors.
The first step is to use the standard error field we made earlier to calculate the confidence intervals. When you look up how to calculate confidence intervals, you’ll probably find something saying that 95% confidence intervals are calculated by taking the mean, and adding/subtracting 1.96 multiplied by the standard error. This 1.96 figure is from the Z distribution, which tells you that 95% of normally distributed data is within 1.96 standard deviations of the mean. And because this is a sample of a population, we multiply that 1.96 by the standard error to get our confidence intervals. Here’s another great blog which breaks it all down.
So, we can create separate fields for our upper and lower confidence interval limits like this:
Once we’ve done that, we can build our graphs. This is the same technique as the standard error bars earlier. Create the measure names/values and dual axis graph with measure names on the line path, and you’ll get the same kind of graph, but now showing confidence intervals instead of standard errors:
Excellent! We’ve now got our 95% confidence intervals… or do we?
Confidence intervals, pt.2 – what’s going on?
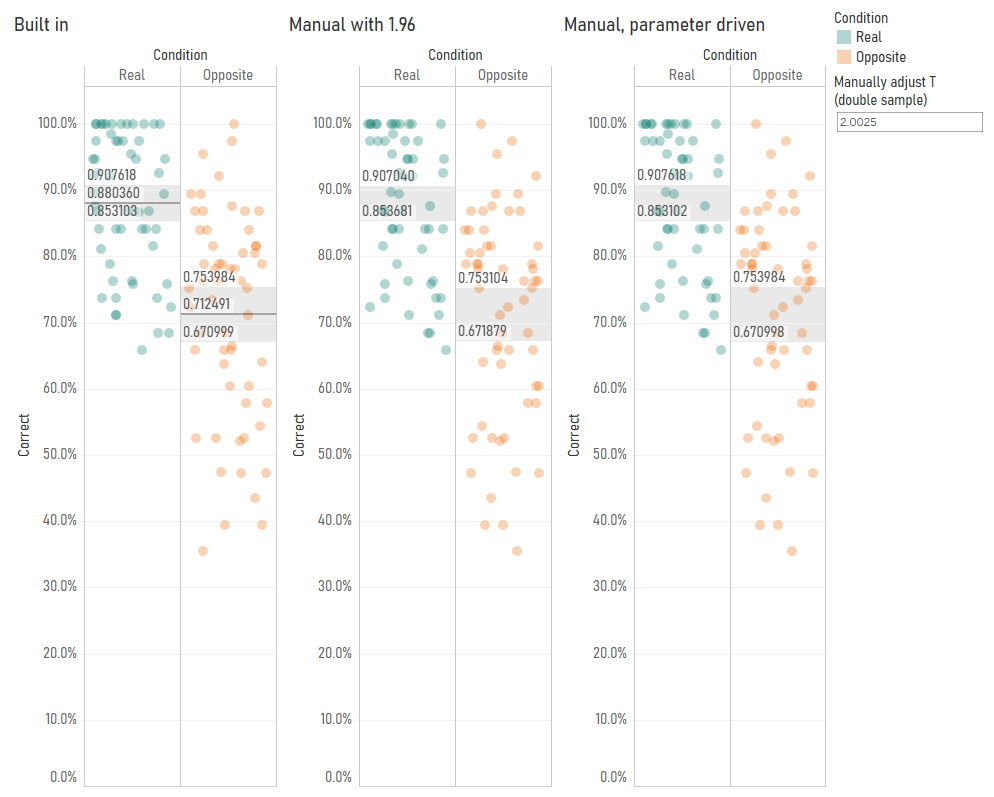
Some of the more statistically minded of you may have been yelling at the screen when I used the 1.96 value from the Z distribution to calculate my confidence intervals. You see, confidence intervals shouldn’t always simply use the Z distribution, even though that’s the standard formula you’ll find when looking up the definition of confidence intervals. Rather, when you’ve got a small sample, which is generally defined as under 30, you should use the T distribution because the size of the sample may skew the normality of the sample. Again, there’s a lot of good information here.
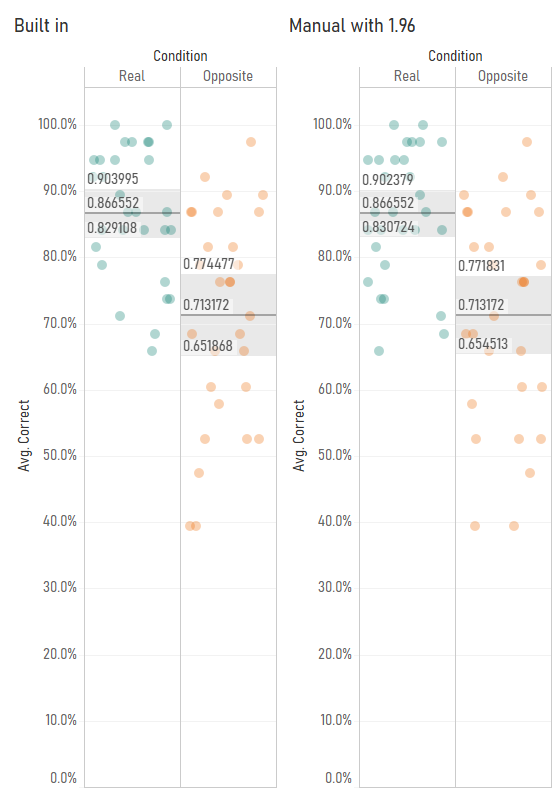
I started investigating this when I noticed that Tableau’s average with 95% confidence interval calculations were different from my manually calculated ones. Have a look at this comparison – you’ll notice that the confidence interval values are slightly different:
I started playing around with the Z/T value in the confidence interval calculation by making it parameter-driven, and I found that Tableau’s confidence interval calculation seemed to use a number like 2.048 rather than 1.96:
This is because Tableau’s confidence interval calculation is using the T distribution rather than the Z distribution. You can find the appropriate T values to use based on your degrees of freedom (which is your sample size minus one) in Appendix B.2 of this very useful pdf (there’s also a table set to 4dp instead of 3dp here). In my case, I’ve got 29 participants, so the degrees of freedom is 28, and the lookup table shows that the relevant T value for a 95% confidence interval is 2.048, so I can put that in my confidence interval calculations. It also looks like Tableau’s confidence intervals are calculated on a more precise number than 2.048, which suggests that the back end is calculating it directly from the T distribution rather than using the fairly common approach of looking it up in a table where everything is rounded to three decimal places. That’s pretty nice too.
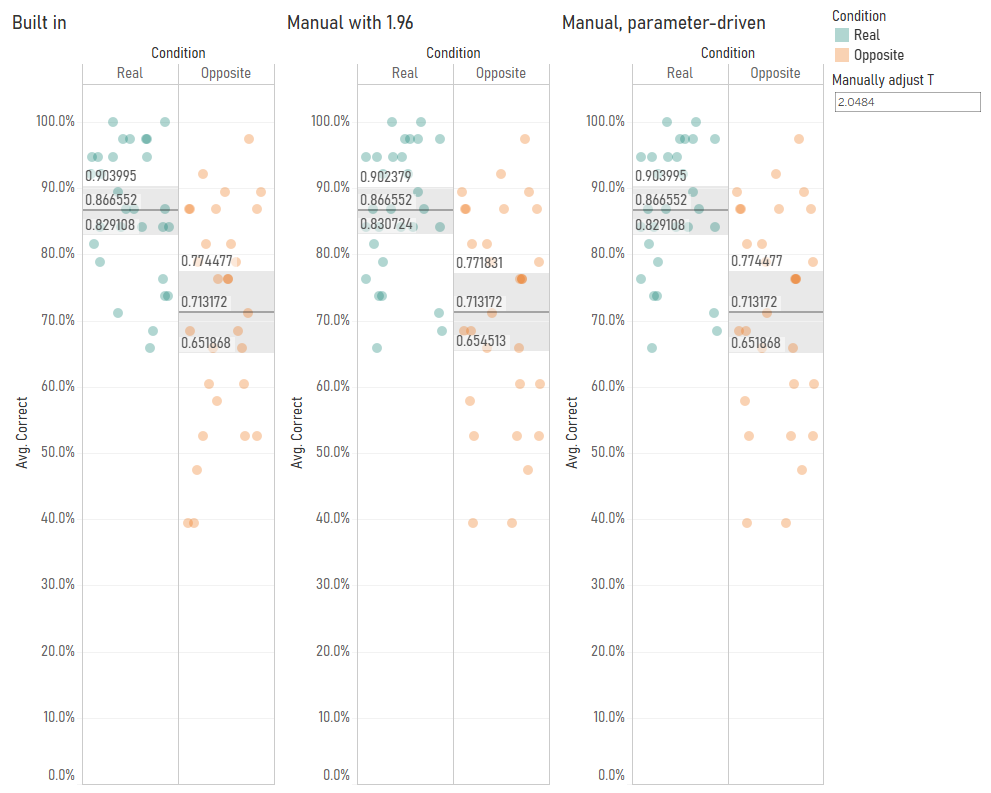
My next step was to check whether Tableau switches between the T and Z distributions based on sample size. So, I duplicated my data and fudged the [correct] field by a random number to create a sample of 58 participants. With 58 participants, it’s fine to use the Z distribution to calculate 95% confidence intervals. But even then, it looks like Tableau is using the T distribution – when I set my parameter to 2.0025 using the slightly-more-precise values in the T table here, you can see that the confidence intervals using T values, not Z values, match Tableau’s calculations:
This is pretty good as well, I think. As your sample size increases, the T distribution starts to match the Z distribution more and more closely anyway. Notice how, with 29 participants, the T value was 2.0484, and with 58 participants, it was 2.0025. This is getting closer and closer to 1.96. At 200 participants, the T value would be 1.9719. Overstating the confidence intervals by using the T distribution is safer default behaviour than accidentally understating them by using the Z distribution.
So, to conclude, I’ve found out the following about confidence intervals in Tableau:
They’re based on standard errors which use the corrected sample standard deviation (and Tableau’s STDEV() function returns the corrected sample standard deviation as well).
They’re based on the T distribution regardless of your sample size.
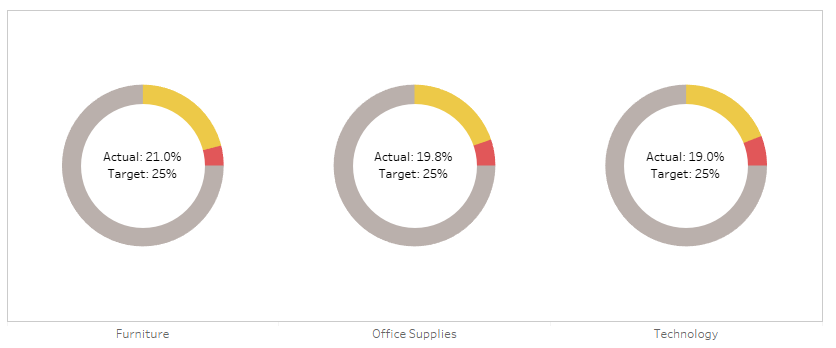
Donut charts aren’t everybody’s cup of tea, but I quite like them for showing a percentage against a total which has to be 100%. Things like the percentage of tickets answered within an hour, or an industrial test pass rate as a percentage, or an on time percentage.
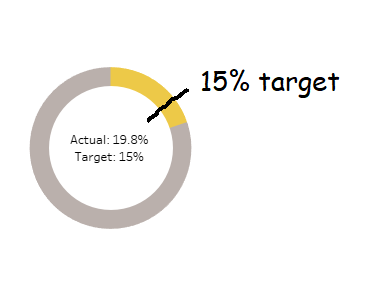
The problem is that percentages often come with targets. If you’re measuring a rate, you’re probably measuring it to check that you’re on target. For example, if you’ve got 19.8% of tickets being answered within an hour, you’ve probably also got a target of 15% or 20% or something, and you’d probably want to show that on your donut chart for context, like this:
In Tableau, you can’t do that, not without creating some pretty filthy trigonometric calculations. But I’ve recently found a workaround which I rather like, which I’ll explain in this blog. You can download the supporting workbook from Tableau Public here.
I’ve used Superstore, which isn’t too ideal for percentages and targets, but hey, it’s something everybody uses. Let’s say you’re the head of sales for California. You know you’re a big market, and you want to keep it that way – you want 15% of all of Superstore’s sales to be in California.
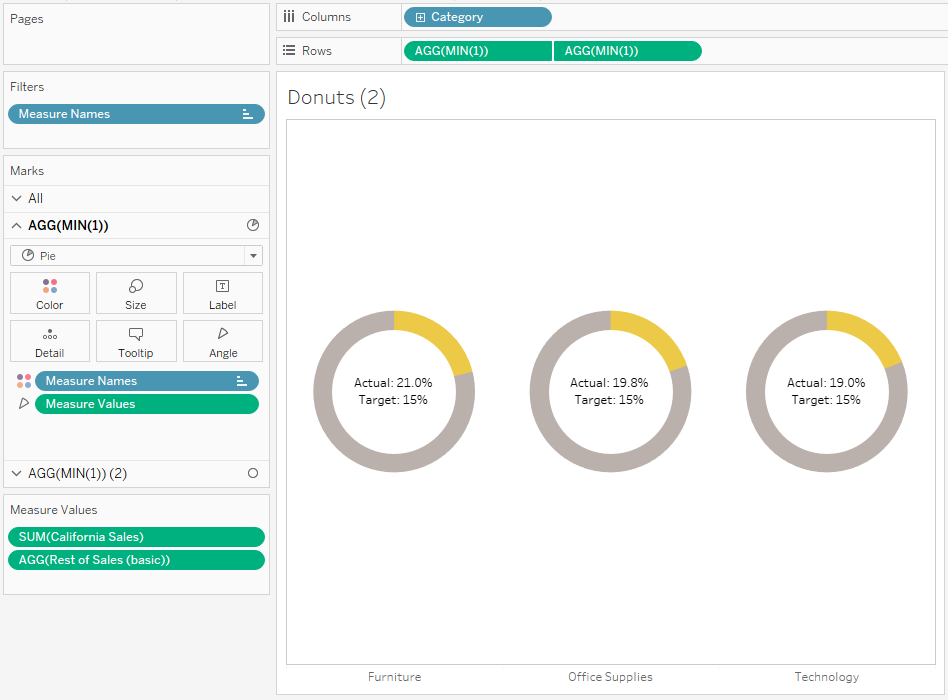
You can create donut charts showing this percentage easily by creating two fields. One called [California Sales], which is:
IF [State] = “California” THEN [Sales] END
The other would be [Rest of US Sales], which is:
SUM([Sales]) – SUM([California Sales])
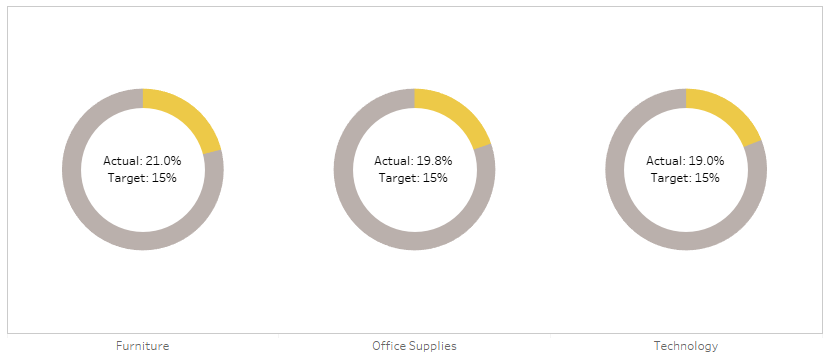
And you’d put it on a donut chart with those two fields as the two measure values, then put measure names on colour, and split it out by category to get something like this:
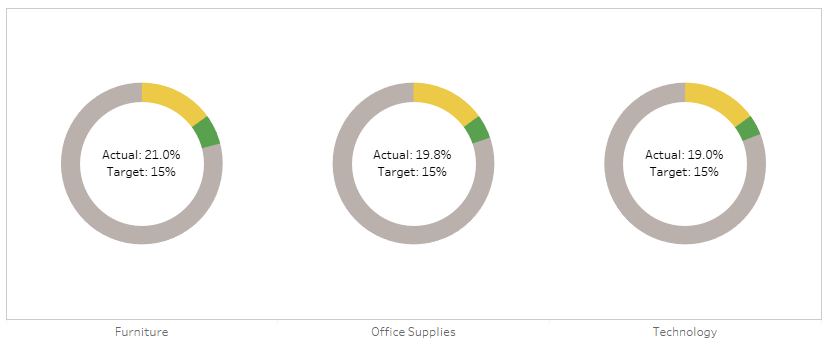
Sadly, we can’t put a reference line at the 15% mark to show the target. Not easily, at least. But what we can do is to play around with the colours. If the percentage is above the target, we could show the percentage up to the target in yellow, and then the overperformance in green, like so:
And if we adjust the target higher, we could show the percentage up to the actual percentage in yellow, and then the underperformance in red, like so:
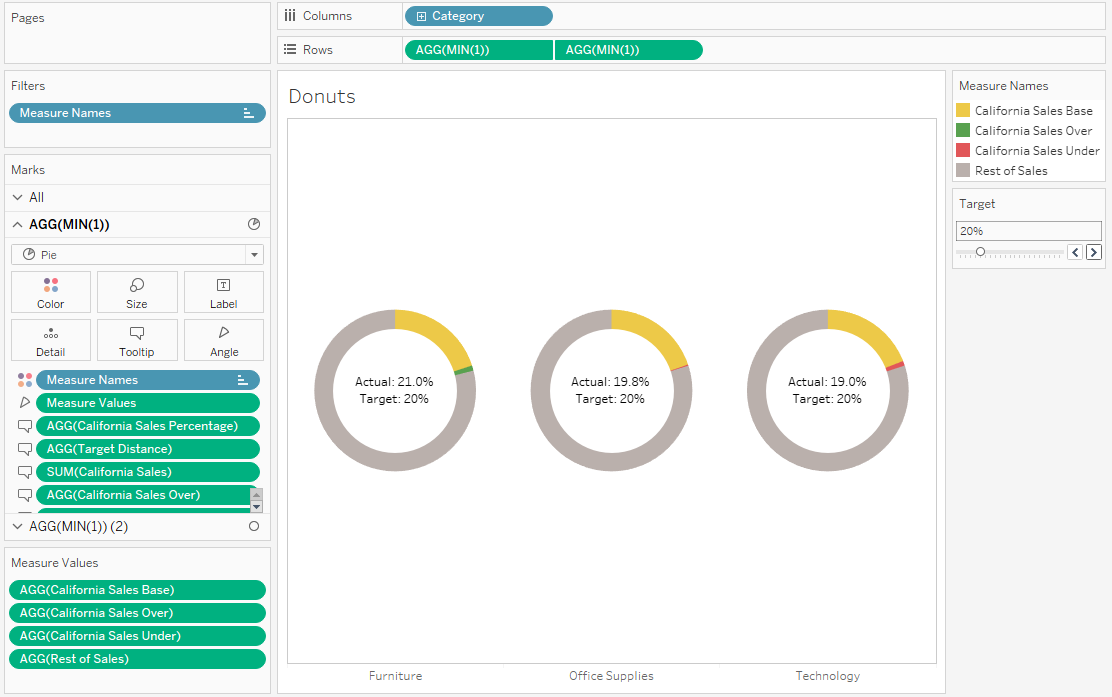
This is a little complicated. It requires a few extra calculations; [California Sales Percentage], [Target Distance], [California Sales Base], [Rest of Sales], [California Sales Over], and [California Sales Under]. Let’s go through the logic one by one.
[California Sales Percentage]
In this calculation, you take the existing [California Sales] field that you’ve made, and found out what that is as a percentage of all sales. It’s simply:
SUM([California Sales]) / SUM([Sales])
[Target Distance]
This is how far from the target the California Sales Percentage is. I’ve used [Target] as a parameter to make it adjustable, but you could also hardcode it. It’s simply the California Sales Percentage minus the target; so, if you’ve got an actual % of 21%, and your target is 15%, then the Target Distance will be 6%. It’s simply:
[California Sales Percentage] – [Target]
[California Sales Base]
This calculation will be what’s in yellow in the donut. If your California Sales Percentage is above the target, then you’ll want it to be yellow up to the target, and then green above that, so this base field will simply be the target. If your California Sales Percentage is below the target, then you’ll want it to be yellow up to the actual sales percentage, and then red for the space between the percentage and the target. So, you can calculate it like this:
IF [Target Distance] > 0 THEN ([Target] * SUM([Sales]))
ELSE SUM([California Sales]) END
[Rest of Sales]
This is the bit in grey. If your California Sales Percentage is above the target, then you’ll want it to be grey from the actual sales up to 100%. If your California Sales Percentage is below the target, then you’ll want it to be grey from the target value up to 100%. That can be calculated like this:
IF [Target Distance] < 0 THEN
SUM([Sales]) – ([Target] * SUM([Sales]))
ELSEIF [Target Distance] > 0 THEN
SUM([Sales]) – SUM([California Sales])
END
[California Sales Over]
This is the bit in green. If your California Sales Percentage is above the target, then you’ll want it to be green between the target and the actual sales percentage. If it’s below target, you don’t want it to show up at all, so set it to zero like this:
IF [Target Distance] > 0 THEN
SUM([California Sales]) – ([Target] * SUM([Sales]))
ELSE 0 END
[California Sales Under]
Finally, this is the bit in red. If your California Sales Percentage is below the target, then you’ll want it to be red between the actual sales percentage and the target. If it’s above target, you don’t want it to show up at all, so set it to zero like this:
IF [Target Distance] < 0 THEN
([Target] * SUM([Sales]))-SUM([California Sales])
ELSE 0 END
Okay! Now we’re ready to build our donuts. This is the easy bit.
Build out your donuts like normal, like this:
Now, instead of the current two measure values, we’ll want all four of the colour ones:
For this one, I’ve set the target to 20% so that there are examples of categories that are above and below target, all in one view.
I’ve been doing a lot of market basket analysis at The Information Lab lately. Market basket analysis is a way of looking for things that people buy at the same time (or that people never buy at the same time) in order to spot trends in people’s behaviour. For example, it’s probably obvious that if somebody buys cereal, they’ll probably also buy milk. Or that if somebody buys tofu, they’re not going to be buying sausages. This is a really nice example of how it all works.
Thing is, after a while, using bread and butter or cereal and milk or sausages and tofu as an example gets kinda dry. And talking about Lego shovels and milligram-level accurate scales is sometimes a little unprofessional, even if it is a perfect example of consumer behaviour.
So, I’ve been analysing the Eurovision Song Contest. The jury votes lend themselves pretty well to market basket analysis, because they’re pretty similar to transactions: each country’s jury (or customer) votes for (or buys) ten countries (or items) at a time (in a basket), and the fact that these countries (or items) are a subset of all possible countries (or items) to vote for (or buy) means that you can make the same selection vs. non-selection distinction. And we all know that some countries always vote for some other countries, regardless of how good the song is, which is part of what makes it fun.
I took the historic Eurovision data collected by Stephan Okhuijsen of Datagraver. Then, using Alteryx, I filtered it to all contests from 1993 onwards, because European countries have been relatively consistent since then. I also filtered it to the final only, and to the jury votes only.
I set the minimum support for a rule to 0.01, which is kind of high for a regular market basket analysis using tens of thousands of SKUs in a supermarket, but works fine for such a closed set of possible choices of countries. I also set the minimum confidence to 0.05. That gave me almost 33,000 association rules, of which about 1,600 were one-to-one country mappings.
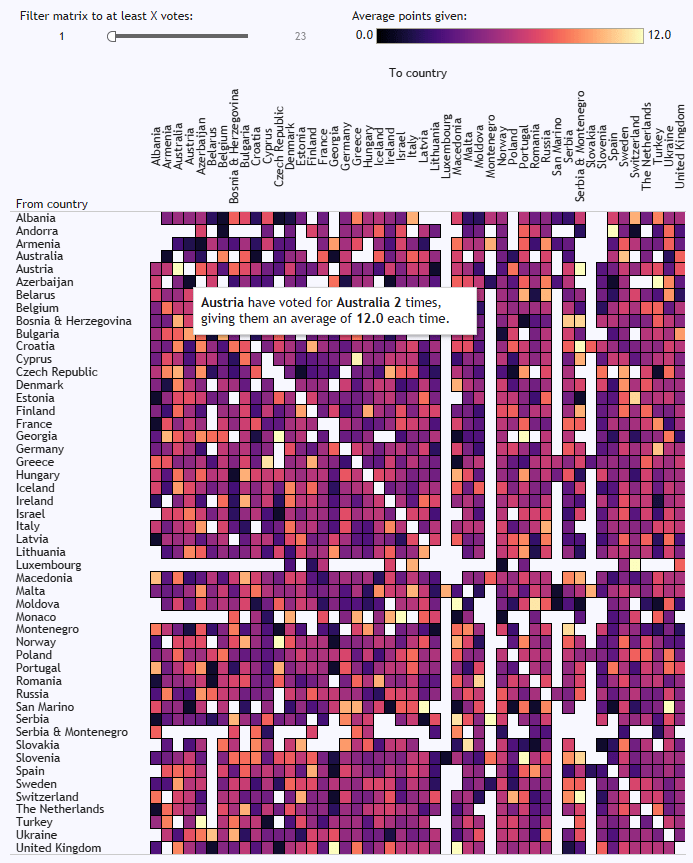
The full results are in an interactive dashboard here.
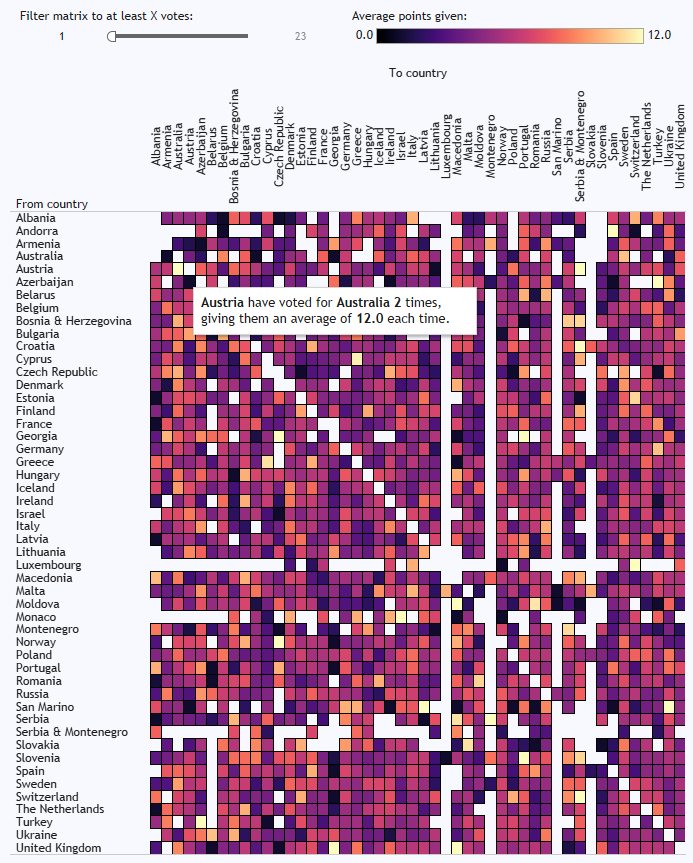
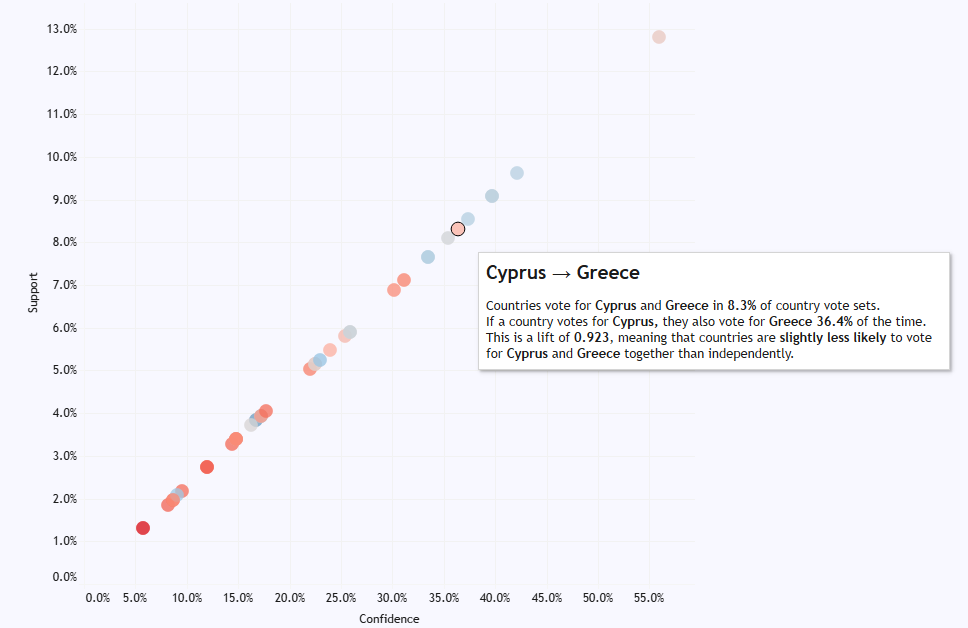
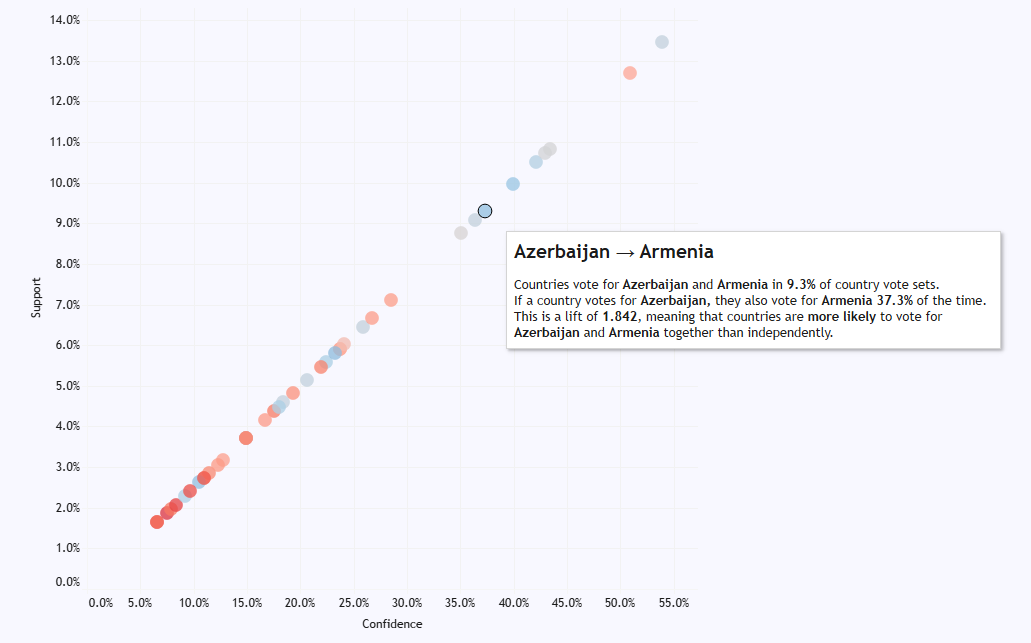
In the matrix at the bottom, you can see who consistently votes for who, and it’s pretty predictable. Cyprus and Greece, for example, almost always give each other the most possible points. There’s a big love in between Moldova and Romania, and between Turkey and Azerbaijan. The Nordics are a bit too cool to give each other full marks every time, but it’s still a bit of a Scandi circle jerk. Andorra love Spain, although it doesn’t seem like that’s reciprocated. Azerbaijan have never voted for Armenia, funnily enough. And Austria have given Australia full marks twice, which I like to believe is because they were hoping to exploit a poor fuzzy matching process in the background scoring:
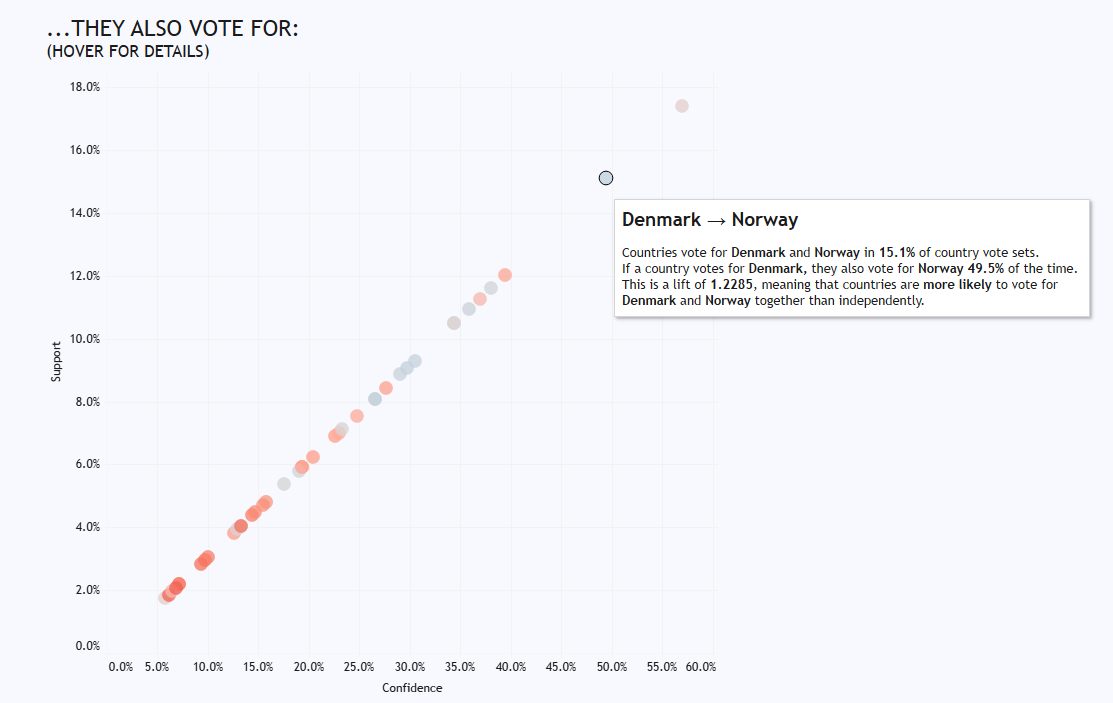
But market basket analysis shows how countries behave as a group, where we can see how some associations are Europe-wide, and some are just confined to the two countries. For example, some of the Scandi trends are reflected in votes across Europe; if a country, any country, votes for Denmark, they’re also likely to vote for Norway:
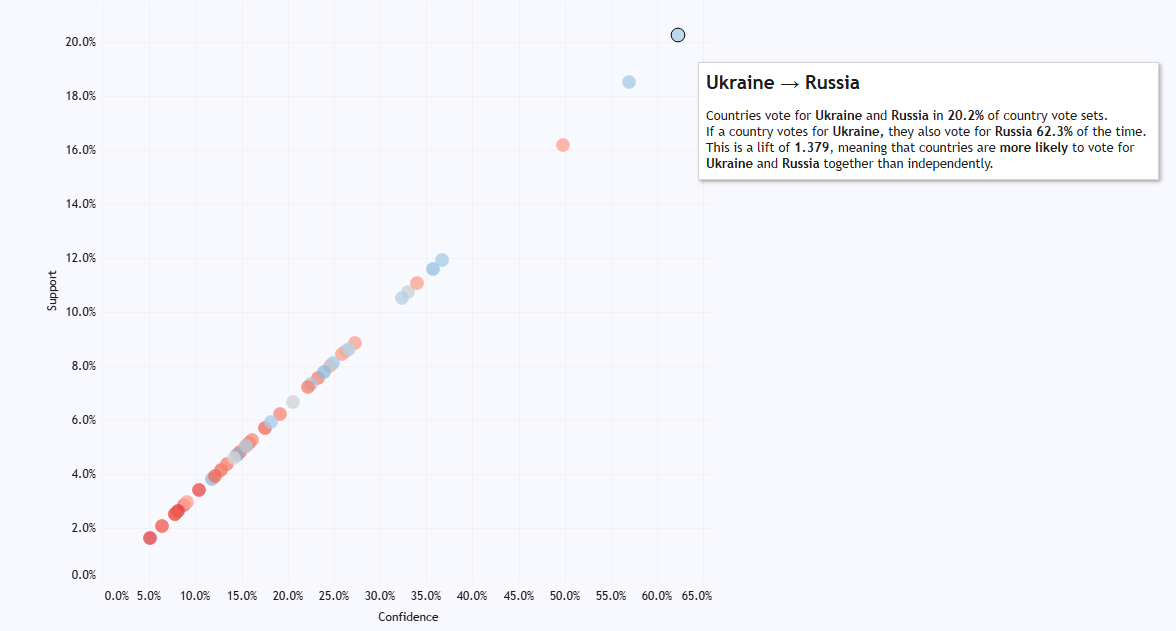
And surprise, surprise, countries that vote for Ukraine will also vote for Russia:
But the Greece/Cyprus love in is special just for them; in fact, if anything, there’s a slightly negative association between them, meaning that if a country votes for Cyprus, they’re slightly less likely to vote for Greece as well:
Likewise with Turkey and Azerbaijan. Just because they give each other full points all the time, other European countries don’t link the two together in their voting behaviour at all:
Meanwhile, even though Azerbaijan will never give points to Armenia, and Armenia have only ever given one point to Azerbaijan, other European countries are far more optimistic. Maybe they hope that voting for both Armenia and Azerbaijan at Eurovision can resolve the Nagorno-Karabakh dispute. Or maybe they just don’t know anything about the Caucasus region and think they’re the same place, I don’t know.
This is quite nice to illustrate, because the market basket analysis allows you to make the distinction; while there are some obvious associations between countries, like how Greece and Cyprus always vote for each other, it shows that those associations aren’t necessarily transferred to other countries’ voting behaviour.
Click through to the interactive version here to explore in more detail. I’m going to be using this in my teaching examples more often.
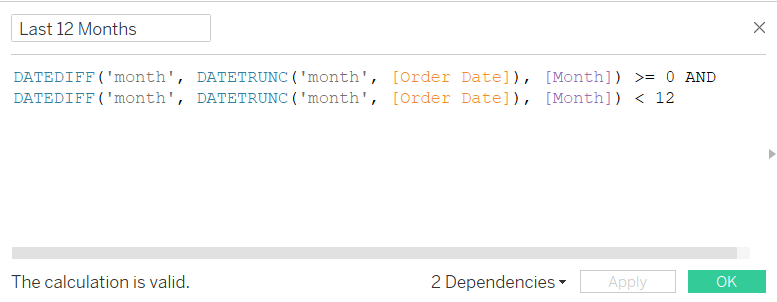
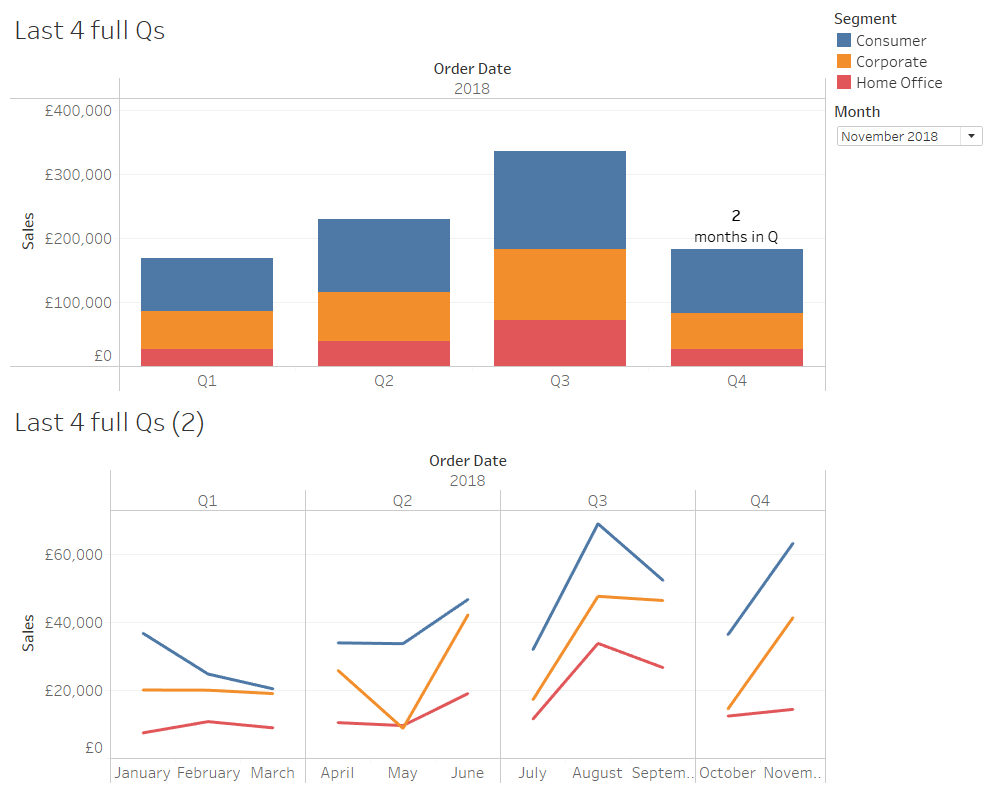
I don’t use the modulo function (which is just % in Tableau) very often, but every so often, I find a really handy solution to something which uses it. In this case, it was a neat way to only show full quarters of historical data.
Here’s a view of all sales by segment per quarter in the Superstore data:
Nice and simple, no filters or restrictions – these are the sales by segment per quarter across the whole data set.
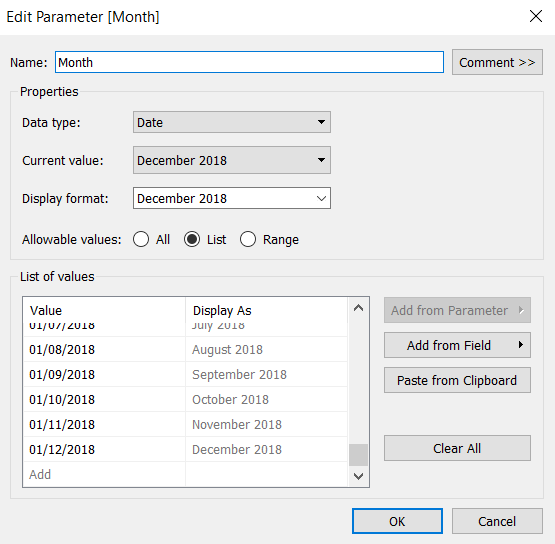
But something I often do for clients is create a date parameter so that they can use a dashboard to generate historical reports, or show what the business looked like at a particular point in time. So, here’s a month selection parameter, which allows you to select any particular month in the data:
…and that can be combined with a Last Twelve Months filter, which will filter the data to the twelve months up to and including the month selected in the parameter. So, if you select November 2018, it’ll show you all the data between 1st December 2017 and 30th November 2018.
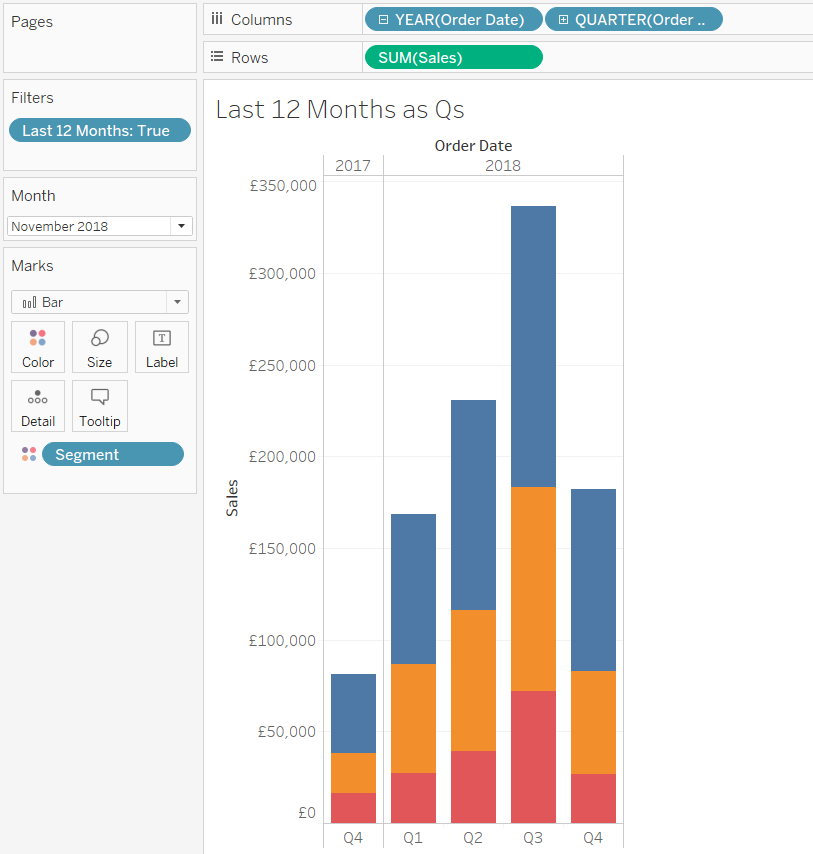
So, let’s have a look at what happens when we apply our Last Twelve Months filter to our sales by segment per quarter view:
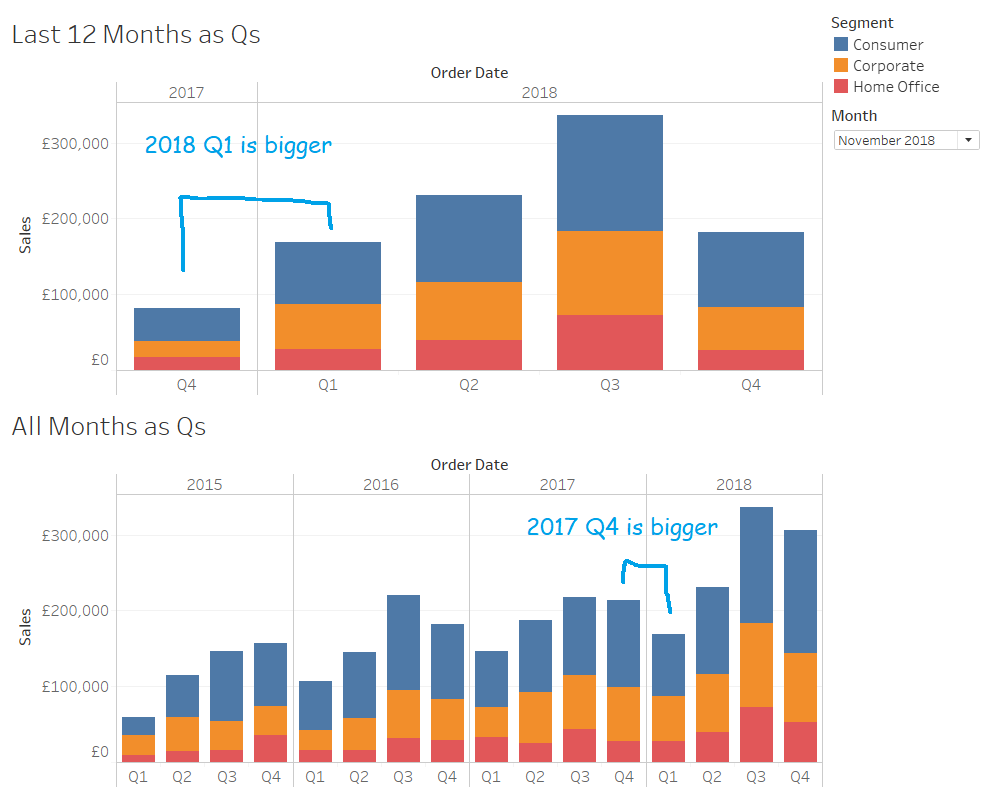
Hold up a second, that doesn’t look right… let’s compare it with the unfiltered data:
What’s happened is that the Last Twelve Months filter has worked exactly as it’s supposed to; it’s filtered the data from 1st December 2017 to 30th November 2018. But the problem with that is that 2017 Q4 only has one month of data in it, and unless you stop to think about it, you could be misled into thinking that there really were more sales in 2018 Q1 than 2017 Q4.
Instead of filtering to exactly the last twelve months, we could filter to however many months it takes to show the current quarter and the previous three full quarters. So, if that’s November 2018, that would be October and November 2018 in the current quarter, and the three full quarters before that, from January 2018 to September 2018. If you select October 2018, it’d just be October 2018 in the current quarter, and then also from January 2018 to September 2018 for the three quarters before that.
This is where the modulo function comes in. You can create an if statement to change the number of months to filter to depending on how far through the quarter the selected month is. The modulo function returns the remainder left over when you divide by a particular number, so for our purpose, we can use the modulo function with the month number to work out how far through a quarter that month is. There are three months in a quarter, so we can use the month number % 3 to work out what the remainder is when we divide the month number by three. This will return the same number for each month at the same stage of a quarter.
For example, the months at the end of a quarter are March (3), June (6), September (9), and December (12). These all divide neatly by three, which means that Month Number % 3 is always going to be zero for the month sat the end of a quarter. The months in the middle of a quarter – February (2), May (5), August (8), and November (11) – don’t divide neatly by three, but they do all return a remainder of two when you calculate Month Number % 3. This calculation is a neat way of isolating how far through a quarter a month is, and you can see how it works in this table:
We can use these remainders – 1, 2, and 0 for the first, second, and third months of a quarter – to create a filter with an if statement:
That might be a little small to read properly, so here it is in text for you to copy/paste:
IF
DATEPART(‘month’, [Month]) % 3 = 0 THEN
DATEDIFF(‘month’, DATETRUNC(‘month’, [Order Date]), [Month]) >= 0 AND
DATEDIFF(‘month’, DATETRUNC(‘month’, [Order Date]), [Month]) < 12
ELSEIF
DATEPART(‘month’, [Month]) % 3 = 2 THEN
DATEDIFF(‘month’, DATETRUNC(‘month’, [Order Date]), [Month]) >= 0 AND
DATEDIFF(‘month’, DATETRUNC(‘month’, [Order Date]), [Month]) < 11
ELSE
DATEDIFF(‘month’, DATETRUNC(‘month’, [Order Date]), [Month]) >= 0 AND
DATEDIFF(‘month’, DATETRUNC(‘month’, [Order Date]), [Month]) < 10
END
Put that filter on all relevant worksheets and set it to TRUE, and sure enough, we get the current incomplete quarter (or the current complete quarter if you select March, June, September, or December), and the previous three full quarters:
This means you can see full quarters within a custom time range without seeing misleading quarterly data, and without using table calculations or LODs.
Are you tired of histograms? Do you look at the count distribution of your actual data points and find yourself thinking, yeah, that’s cool and all, but I wish there was a more abstract way of showing this? Then you’ll probably like violin plots. That’s these things here:
Despite their somewhat sexual connotations, violin plots can be really useful for comparing distributions of data. To be honest, if it mattered that much to me, I’d probably go for a boxplot with overlaid, mostly transparent data points… but hey, people still use these, Tableau doesn’t support them natively, and I haven’t found a full tutorial anywhere (apologies if I’ve missed one – let me know!), so here’s how to make them.
To follow along, you can download the Tableau workbook I used from my Tableau Public page here.
It’s all based around Kernel density estimation. This is maths for “take my data, smooth it out a bit, and make it so I can generalise it to data I haven’t got yet”. You can read more about that here, and I’m going to use the same set of six values used in the Wikipedia example.
Here’s what you’ll need, and here’s one I made earlier:
Your data. One column with one row per observation, one column with one row per observation ID. Something a little like this:
A handy data scaffold. I’ve used a hundred points, going from zero to 99; if your data has a lot of variance, you might want to whack that up to a thousand, although that’ll make things proper slow. Either way, keep it simple; it should look like this:
Okay, nice. Stick these into Tableau, and join them with a custom join calculation so that every row in the data joins to every row in the scaffold (i.e. six rows balloons out to 600 rows here; this is why using a 1000 row scaffold isn’t pretty, performance-wise). I normally just type in “join” on both sides:
Also, remember that with a scaffolded dataset, simply summing your values will just multiply the value you actually want by a hundred. Watch out for that.
Okay, we’ve got our data; let’s plot the sample values we want to create a violin plot of.
What we need to do is draw a kernel around each data point, like this (but better):
…and add up the y-axis values of those kernels to create the overall kernel density, like this (but a lot better):
This is why we need the data scaffold; you can’t draw a kernel with one point, so we need a hundred points for each point.
The first thing to do is to create an adjusted x-axis. We want the hundred points for each data point to range from the lowest to the highest value. You can do that like this (ignore the bandwidth part for now):
Alternatively, you can see that there’s no point making the scaffolded points for the values go all the way across the range, so you could fix it on the Sample ID instead. But I found that this had a knock-on effect down the line that I didn’t like, so let’s leave this for now. If you can make it work, I’d love to hear from you.
We’ve now got a set of Adjusted X data points across the range of the data for each data point:
The next step is to stick something on the y-axis so that each point goes up the required amount to draw a kernel around each data point. It’ll end up looking like this:
This is done as a normal kernel using the standard normal density function, because that’ll probably do the job well enough for most situations. I’m not going to go into the different types of kernel functions, but you can read about them here, and if a different kernel function tickles your fancy, you can rewrite the (1/(SQRT(2*PI()))) * EXP(-0.5 * ( part of the equation with something else.
I’m also not going to go into bandwidths, because it’s complicated. There are various proper methods for choosing your bandwidth, but if you play about with it, you’ll see that setting the bandwidth too low doesn’t smooth out the curve enough, and setting the bandwidth too high smooths out the curve too much.
Anyway. To create the kernel density estimation for the data points, we need to sum up the individual kernels. This is the easy part in Tableau; CTRL+drag the same kernel calculation field to rows again, take Sample ID off colour/detail, sum it up, and put it on a synchronised dual axis. Voilà.
This grey curve is half a violin plot on its side. But before we go into how to rotate and fill it, let’s go back to the scaling factor. I’ve kept it at 0 the whole way through, so that the x-axis runs from the smallest data point to the highest data point. That’s fine if you’re showing your actual data, but the whole point of kernel density estimates is to show a probability function… or in other words, “okay this is the data I’ve got, but what if there’s going to be more data like this, where’s it going to go?”. There may well be other values higher than your highest point or lower than your lowest point. So, I created a parameter to mess about with how far the x-axis goes, simply by adding a constant to the highest value and subtracting that same constant from the lowest value. You can adjust it as you see fit; I think setting it to 4 captures this data nicely:
Right. That’s the maths behind a violin plot. Now to actually make one.
All we need to do is fill it and rotate it. The filling is easy; just convert it from line to area:
…but the rotation messes this right up.
So, we need to redraw it as a polygon. And to do that, we need to redo some of the calculations. Sorry about that.
Firstly, make this change to the Adjusted X calculation:
And now make this change to your kernel calculation:
IF [X] = 0 THEN 0
ELSEIF [X] = 99 THEN 0
ELSE
1/({COUNTD([Sample ID])}*[bandwidth (wiki example)])
*
(1/(SQRT(2*PI()))) * EXP(-0.5 * (
([Adjusted X (polygon)] - [Sample Value])^2)/[bandwidth (wiki example)])
END
That should do the trick. If you’re using a bigger scaffold, remember to update the 99 to 999 and the 97 to 997! Now you can plot your polygon like this:
And if you repeat the kernel calculation, whack a minus on the front of it, and dual axis it, you can make a nice violin:
These violins take a lot of formatting to make, and it’s an absolute faff to compare two separate distributions. And the LODs for finding the max and min values in the data will require you to add in a FIXED for any dimension you want in the view. They’ll also screw up filters, unless you put them in context. It is possible, though; here’s an unformatted set of violins for Sales in each Category in California using Tableau’s Superstore dataset. With some a fair bit of tidying, this could look pretty good:
Again, it’s not an ideal way of showing the distributions, and hopefully Tableau introduce violin plots in the same way as boxplots in a later version. But for now, this is how you’d do it if you really wanted one.