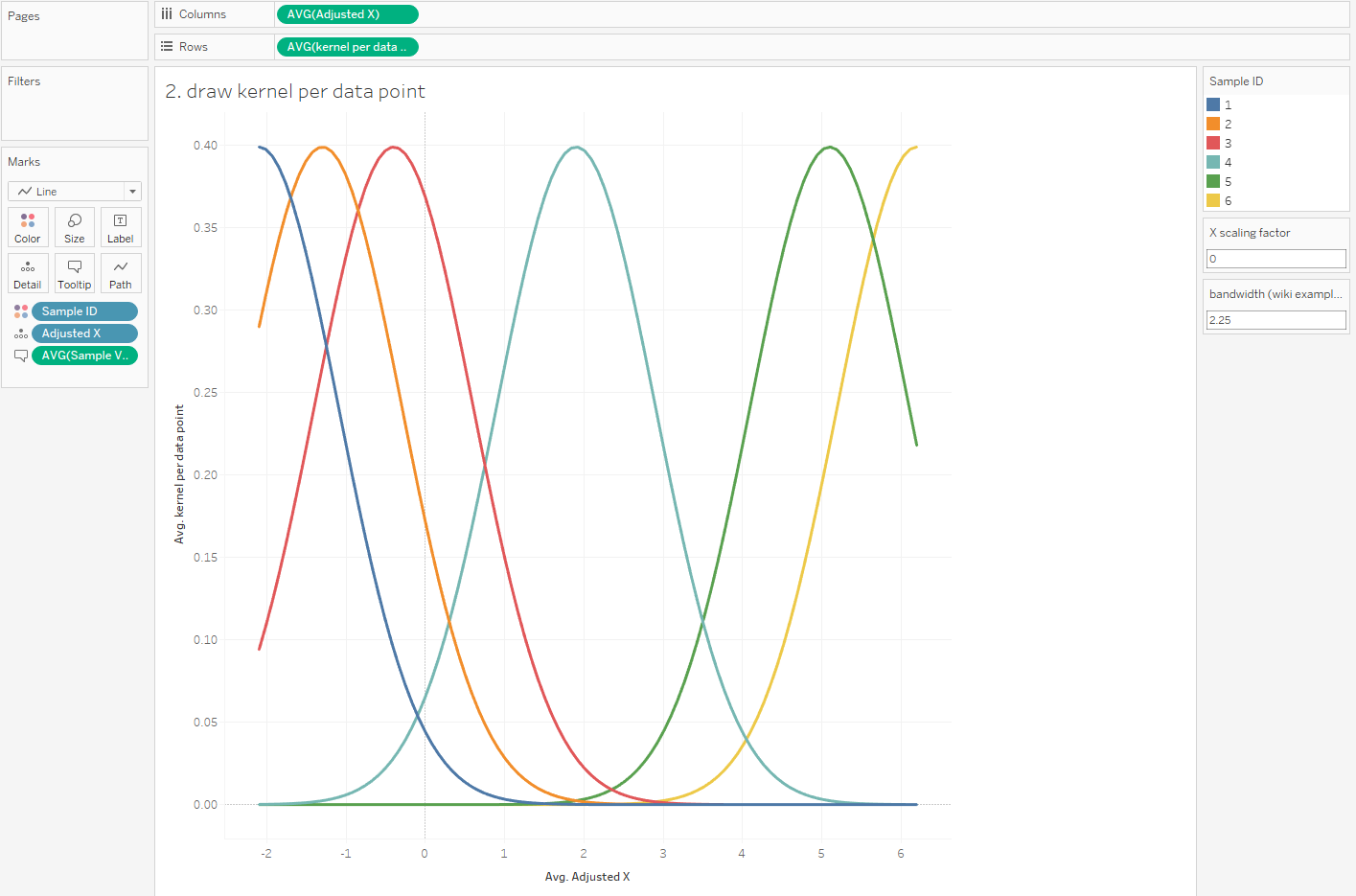
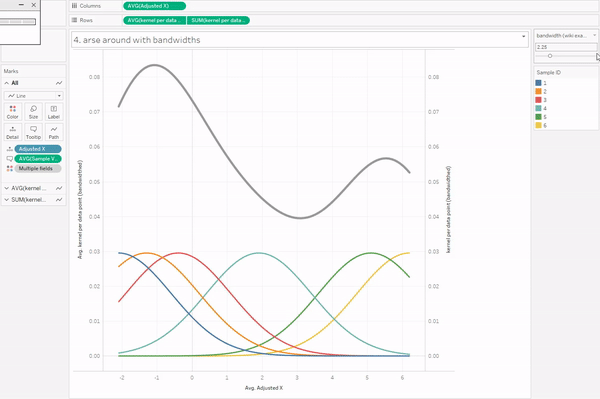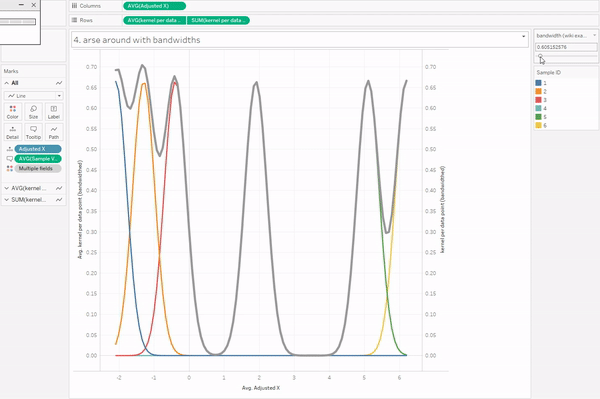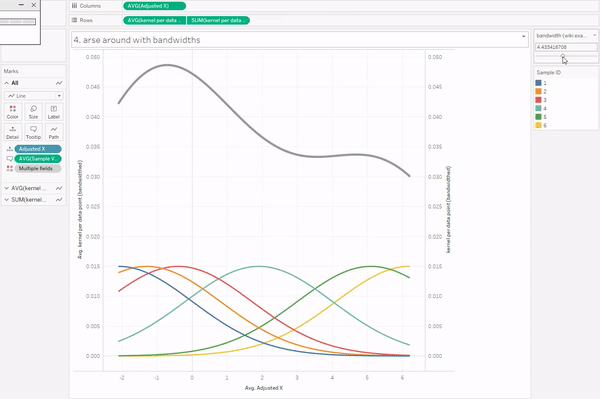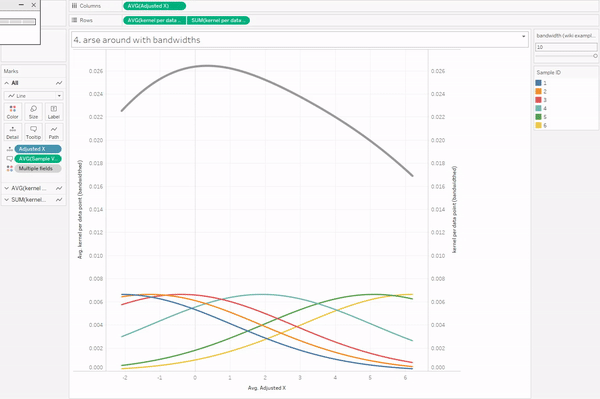
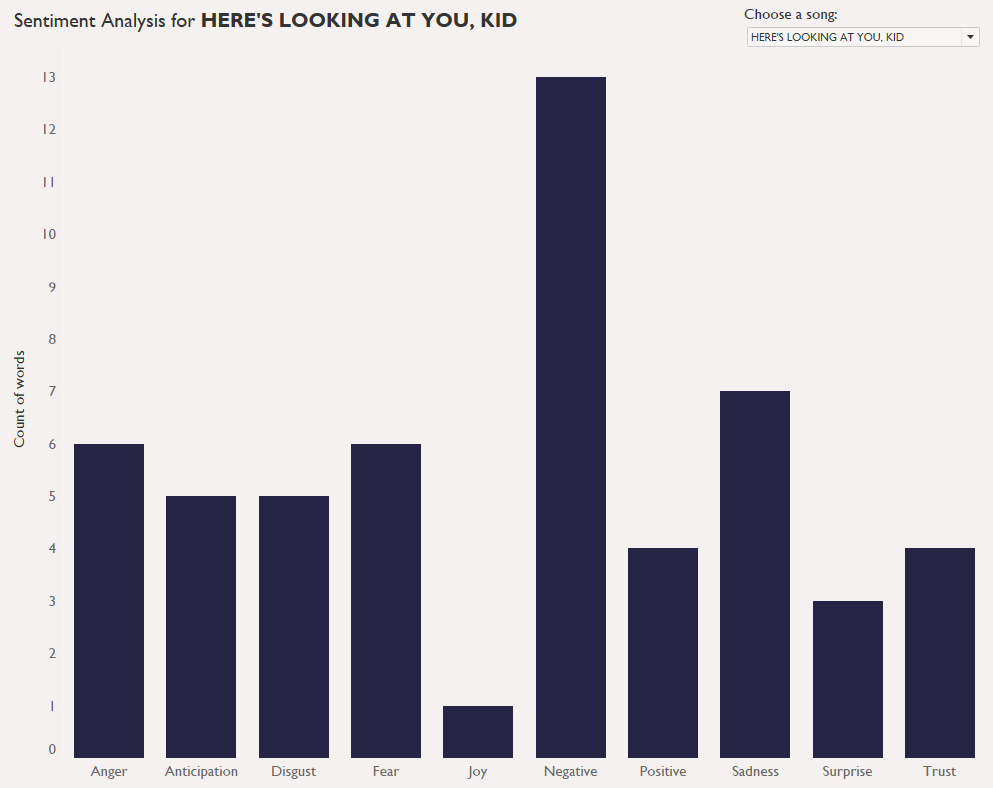
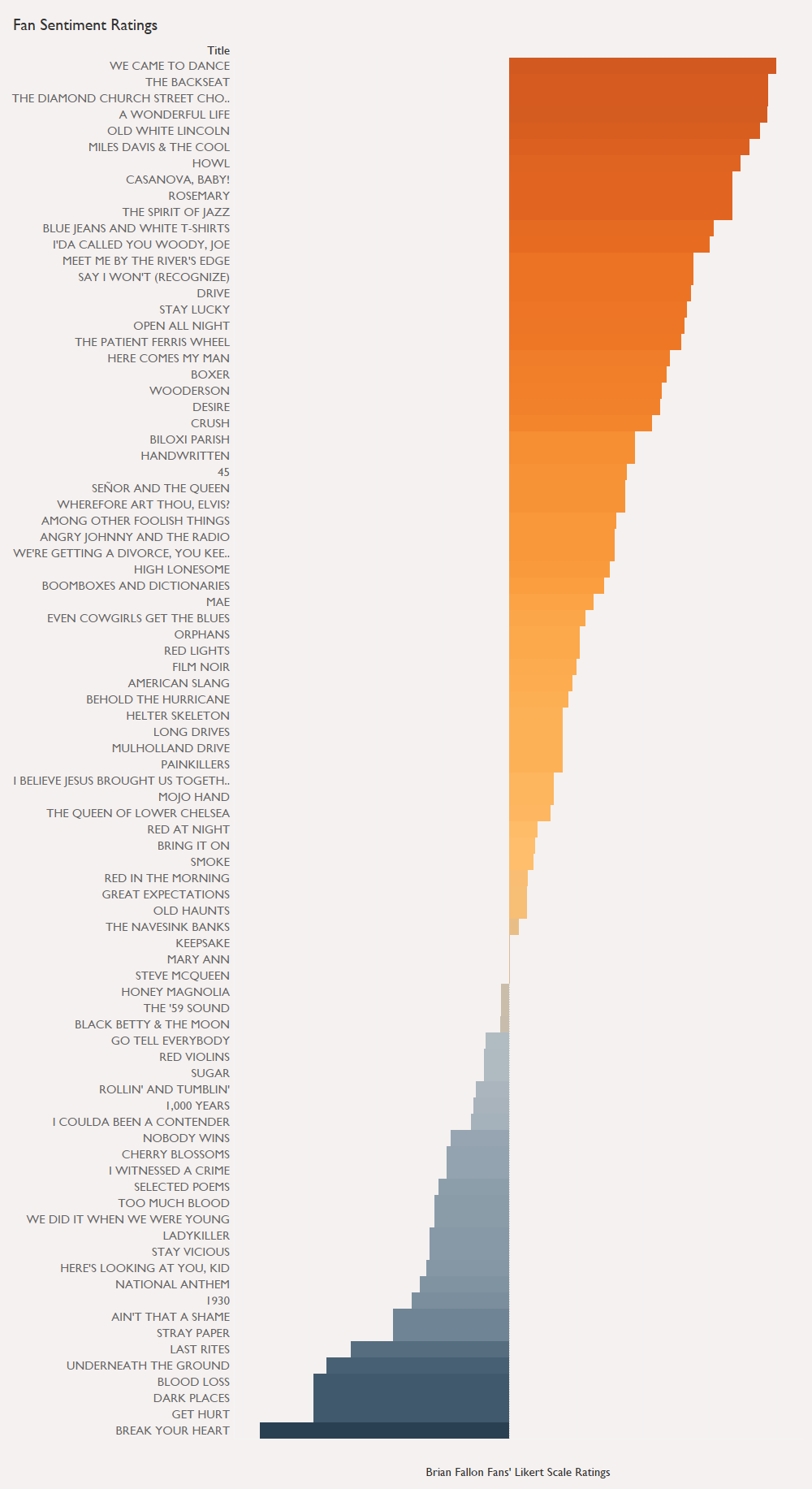
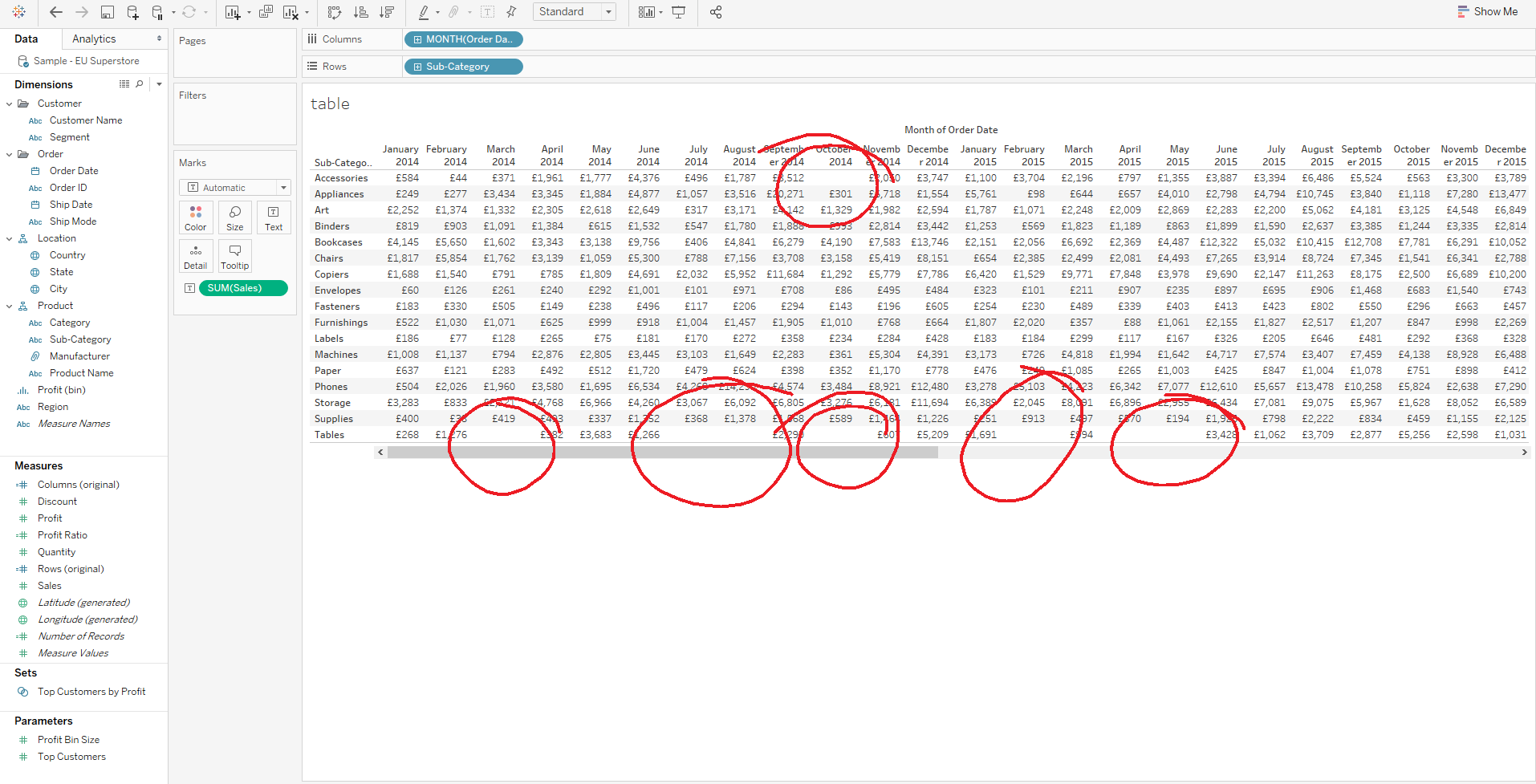
Introduction
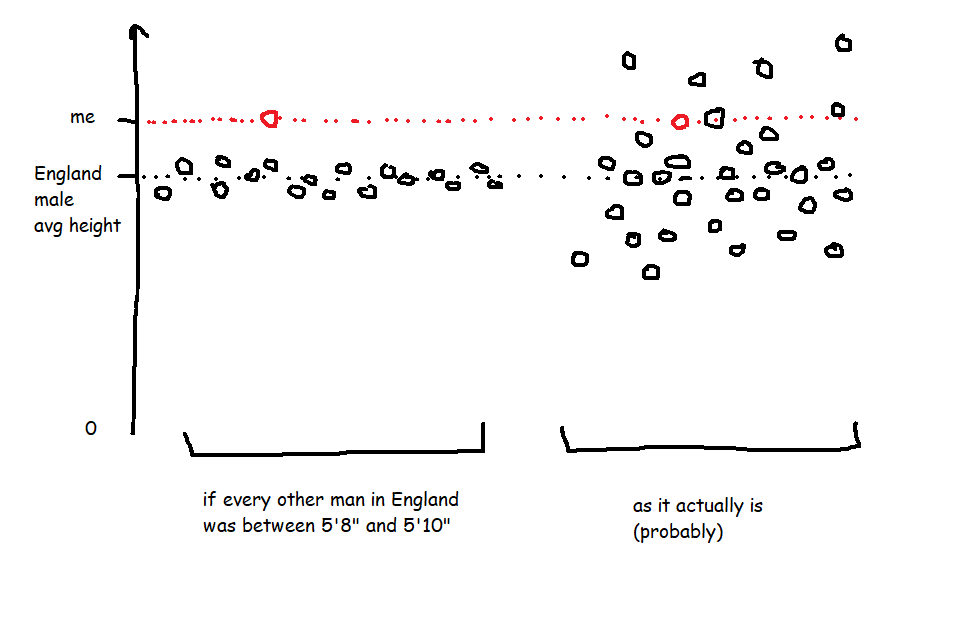
A little over a year ago, I sat in a park with some friends on a hot day and scientifically proved that Fosters isn’t actually that bad.
After that, we figured we should probably do the same thing with genuinely good beers. But this throws up all sorts of complications, like, what’s a genuinely good beer, and what about accounting for different tastes and styles, and what if I found out that I only like a beer because the can design is pretty? The stakes were much, much higher this time.
So, we went for the corner shop tinnie equivalent of the indie beer world – the standard IPA. Every brewery has an IPA, and you can tell a lot about a brewery by how well they do the standard style that defines modern craft beer … well, about as standard as the loose collection of totally different things that all get called IPAs can be. We also decided to keep it local, focusing strictly on South London IPAs.
Sadly for me, this meant we didn’t get to objectively rate Beavertown Gamma Ray, the North London American pale ale. I am fascinated by this beer. Gamma Ray circa 2014-16 was like the Barcelona 2009-11 team of London beers. Nothing compared. You’d go to a pub with 20 different taps of interesting beers, have a pint of Gamma Ray, and think, nah, I’m set for the evening, this is all I want. I am also absolutely convinced that since their takeover by partnership with Heineken, Gamma Ray has got worse. I mean, it’s still fine, but it used to be something special, you know? The first thing I’d do if I invented a time machine would be to go to the industrial estate in Tottenham in summer 2015 and order a pint of peak Gamma Ray, and then compare it to the 2020 pint I’d brought back in time with me.
South London IPAs
Anyway, back to South London. On a muggy August evening in a back garden in Dulwich, with the rain clouds hovering around like a wasp at a picnic, we set about drinking and ranking the IPAs of South London, which are, in alphabetical order:
Anspach & Hobday The IPA
BBNo 05 Mosaic & Amarillo
Brick Peckham IPA
Brixton Electric IPA
Canopy Brockwell IPA
Fourpure Shapeshifter
Gipsy Hill Baller
The Kernel IPA Nelson Sauvin & Vic Secret

(side note: it’s interesting how most of these beers have orange/red in their labels. I’d have said a well-balanced IPA – clear and crisp at first sip, slightly sweet and full bodied, but then turning bitter and dankly aromatic, so, wait, was that bitter, or sweet, I can’t tell, I’d better have some more – would taste a kind of forest green.)
Methods
A quick methods note in case you feel the need to replicate our research. All beers were bought in the week or so leading up to the experiment—mostly sourced from Hop Burns and Black, otherwise bought straight from the brewery—and were kept in our fridge for 48 hours before drinking while the weekly shop sat on the kitchen table. Immediately before the experiment started, JM and I decanted all beers into two-pint bottles we had left over from takeaways from The Beer Shop in Nunhead, various Clapton Crafts, and Stormbird, and stuck them in a coolbox full of ice. JM and I numbered the bottles 1-8, then CL and SCB recoded them using a random number generator to ensure that nobody knew what they were drinking until we checked the codes after rating everything. Finally, I also pseudorandomised the drinking order so that all beers were spread out evenly over the course of the evening to minimise any possible order effects:

All beers were poured into identical small glasses in ~200ml measures, and rated on a 1-7 Likert scale, where 4 means neutral, 3-2-1 is increasingly negative, and 5-6-7 is increasingly positive.
(I haven’t written a scientific paper in four years, and I still find it really hard not to put everything in the methods section into the passive voice. Sorry about that.)
Results
We then tasted all the beers. It was hard work, but we managed to soldier on through it. With some trepidation, we totted up the scores, drew up a table of beers, and then matched up the codes for the big reveal. From bottom to top, the results are as follows.
8. Brixton Electric IPA


We went to Brixton’s taproom a couple of years ago, and it was … nothing earth-shattering, but pretty nice? We made a mental note to drink more of their beer, but then they got bought out by partnered up with Heineken and we gave them a bit of a miss after that. I was kind of hoping this would come out bottom, so it was satisfying, in a petty, pretentious, I-should-be-better-than-this kind of way, to get objective evidence that Heineken makes independent breweries worse. Can’t argue with this, though.
7. Anspach & Hobday The IPA
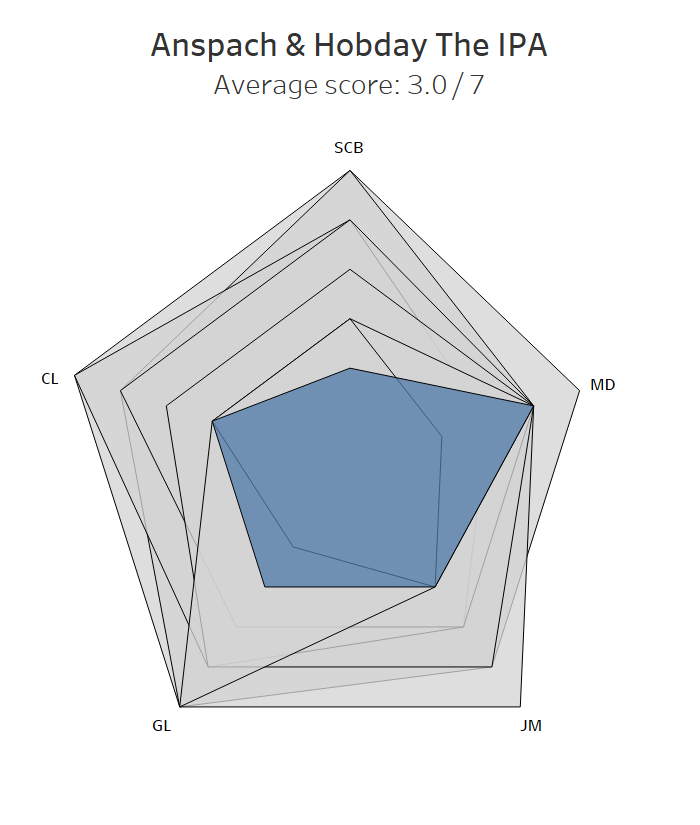

This one was a surprise. I’ve had quite a few excellent pints of the Anspach & Hobday IPA at The Pigeon, and even JM’s dad / my father-in-law, who normally writes off anything over 4% as too strong, really enjoyed it (he ordered it by mistake and we just decided not to tell him it was 6%). Maybe it’s just one of those beers that’s noticeably better on tap than in a can. Still, something’s got to score lower, and I’ll still be popping into The Pigeon for a couple of pints in a milk carton to take to the park. A disappointing result for the up-and-coming South Londoners.
6. Canopy Brockwell IPA


There’s an interesting split between me and everybody else here. Canopy are, I reckon, South London’s most underrated brewery. Their Basso DIPA is the best I’ve had all year, and there aren’t many simple cycling pleasures better than going for a long ride on a hot day and ending up at their taproom for a cold pint of Paceline. I like Canopy’s Brockwell IPA, and I liked it here too; the others thought it was “a bit lager-y”. They’re wrong, and Canopy should be sitting further up the table, but the rules are the rules. If I don’t have my scientific integrity, I’m just drinking in a back garden.
4=. Fourpure Shapeshifter


Another sell-out, but Fourpure have always seemed to know exactly what they’re doing, and apparently they still do. Shapeshifter is a solid all-round IPA, and it’s the first beer on this list to receive at least a 4 from all of us. It’s like the plain digestive biscuit of the beer world – nothing to get excited about, but you’d never refuse one, would you?
4=. The Kernel India Pale Ale Nelson Sauvin & Vic Secret
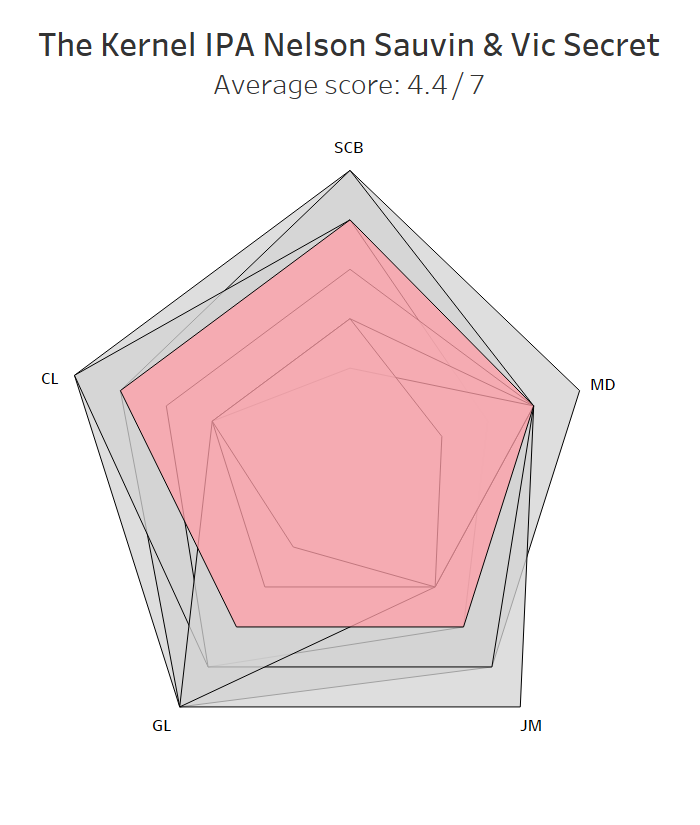

The Kernel are a bit of an enigma. Back in the ancient days of yore, by which I mean 2013, anything on tap by The Kernel stood out (as did the price, but it felt worth it). And yet I never really felt like I knew The Kernel. Maybe because they closed their taproom on the Bermondsey Beer Mile for years, maybe because they tended more towards one-off brews and variations rather than a core range (their one core beer I can name, the Table Beer, splits opinion – the correct half of us love it, the other half really don’t). I’d recommend them, but I’d be hard pressed to say why, or which specific beers, other than “ah, it’s just really good”.
I don’t think they’ve got worse, it’s just that everybody else has got better, and I think that they’re better overall at porters and stouts. Anyway, we all thought this one was a decent effort and wouldn’t complain about it cluttering up the fridge.
3. Gipsy Hill Baller


This was the weakest beer of the lot by ABV (is 5.4% really even an IPA?), and, as such, it was summarily dismissed by MD as not having enough body, but it punches above its weight for the rest of us. Baller is JM’s go-to beer for her work’s Friday afternoon (virtual) beer o’clock, so I thought she’d recognise it instantly. Surprisingly, she didn’t, and she only gave it a 4. Maybe anything tastes good if it’s your first can on a Friday afternoon.
2. Brick Brewery Peckham IPA


In second place is the Brick Brewery Peckham IPA, which was a pleasant surprise. When I’m at Brick, I have a well-worn routine. I’ll start with a pint of the Peckham Pale, which is just a great general purpose, all-weather beer on both cask and keg. I’ll then move onto one of their outstanding one-offs or irregulars, like the Inashi yuzu and plum sour, or their recent Cellared Pils that rivals the Lost & Grounded Keller Pils, or their East or West Coast DIPA, or the Velvet Sea stout, or … point is, I normally ignore this one.
Well, I shouldn’t. The Peckham IPA was the favourite or joint favourite for three of us, and scored pretty highly for the other two too. It was well-balanced, it was quaffable, and it’s at the top of my list for next time I’m at the Brick taproom.
1. Brew By Numbers 05 Mosaic & Amarillo


Just pipping Brick Brewery’s Peckham IPA to the top spot was Brew By Numbers’ 05 Mosaic & Amarillo. It’s tropical, well-balanced, and easy to drink. It’s also delicious. It was the favourite or joint favourite for four of us, and SCB’s tasting notes—“yay!”—sum it up pretty well.
I’m glad BBNo ran out overall winners. It’s where JM and I had our civil partnership early this year (before heading to Brick for the after party), so it’s satisfying to see those two come out top objectively as well as sentimentally.
The ultimate accolade, though, comes from MD. The BBNo IPA was the only beer which pushed him beyond the neutral four-out-of-seven zone into net positive territory. Truly remarkable.
Summary

And there you have it. BBNo and Brick Brewery brew South London’s best standard IPAs, but more research is needed to see if this transfers from garden drinking to park drinking or pub/taproom drinking (when it feels reasonable to do so inside in groups again).