Ever thought of tracking whether something’s hitting the target by showing an actual target? I was looking through some old radial blogs recently, and realised you could use a scatterplot on x-y coördinates to show accuracy on a bullseye target.
(to cut straight to the viz on Tableau Public, go here; to find out how to create it, keep reading!)
For example, you could set up an image of a target a bit like this as a background image:

…and plot simple x-y points in Tableau over the top to show how close people/departments/countries are to meeting their target:
I used MS Publisher to design these concentric circles in the background image because when you select them all and save as an image, it doesn’t save the blank space as white, so you can use it with any colour worksheet or dashboard. Feel free to download this target image here (and if you use it, give me a shout! I’d love to see what kind of cool things you’re using it for).
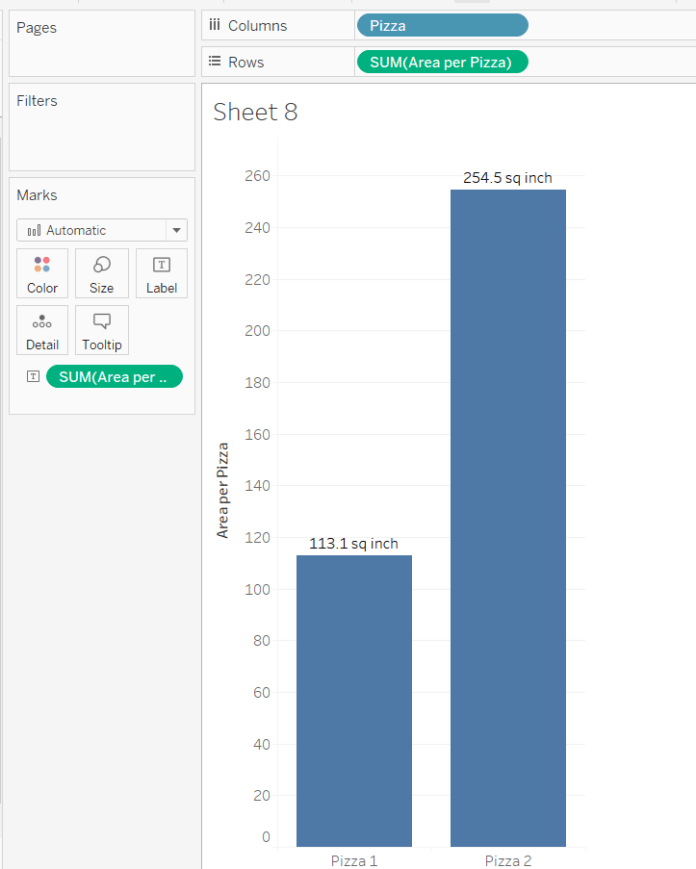
Sadly, Superstore doesn’t have target data on it, so I’ve mocked up a quick dataset of sales and target sales per country as follows:

The next thing to do is calculate the “accuracy” on the bullseye; the nearer the sales figure is to the target, the closer to the middle of the bullseye it should be. However, once you’ve met or exceeded your target, you don’t want the points to keep moving. Countries with sales at 101% of the target and at 300% of the target should both still be in the middle.
The exact middle of the target is going to be at coördinates (0,0), which means that we actually want to create a field which takes some kind of inverse of the accuracy, where the greater the accuracy, the smaller the number in that field.

So, let’s create the following calculated fields. I’ve adapted them a bit from this blog on radial bar charts so that you can put the X field on columns and the Y field on rows, which is more intuitive.
Accuracy:
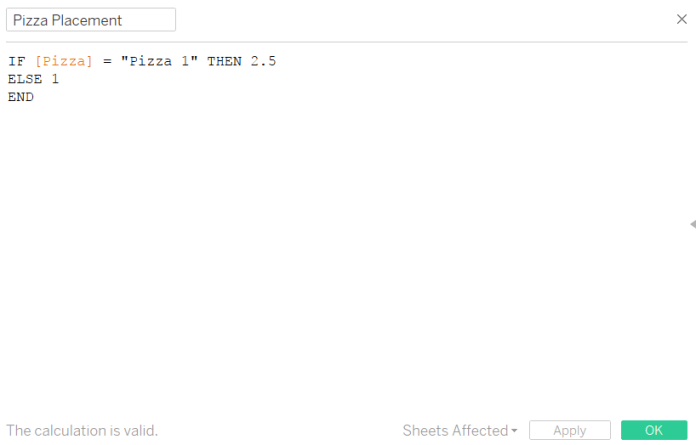
IF [Sales] > [Target] THEN 1.05
ELSE [Sales] / [Target]
END
Radial Field:
1.1 - [Accuracy]
Why have I set the Accuracy equaliser bit to 1.05 instead of 1? And why have I set the Radial Field calculation to 1.1 instead of 1?
Well, it’s a bit fiddly, but it’s about plotting. I want everything where Sales is 100% of Target or more to be in the gold bullseye, so I want that to fill a certain amount of space. If I set the Accuracy equaliser bit to 1 and the Radial Field calculation part to 1, then it plots everything that’s at 100% or more at (0,0) and includes everything that’s 90% or more in the gold bullseye. I want to space out the 100% or more points so that they’re not on top of each other, and I want only the 100% or more points to be included in the gold bullseye. Setting the Radial Field calculation part to 1.1 makes it so that the edge of the gold bullseye denotes 100%. That means that the 100% or more points will be plotted on the edge of the bullseye. So, the 1.05 part in the Accuracy calculation moves those points further inside the bullseye, but not into the exact middle where they’ll be on top of each other.
While I’m at it, there’s a limitation to the Accuracy calculation. Have you spotted how it’s [Sales] > [Target] rather than SUM([Sales]) > SUM([Target])? This is because the angle calculation needs to aggregate the Radial Field further, and will break if the Accuracy or Radial Field calculations are already aggregated. This means that you’ll probably need to do some data processing to make sure that it’s just one row per thing in the dataset.
The next fields to calculate are:
Radial Angle:
(INDEX() -1 ) *
(1/WINDOW_COUNT(COUNT([Radial Field])))
* 2 * PI()
X:
MAX([Radial Field]) * SIN([Radial Angle])
Y:
MAX([Radial Field]) * COS([Radial Angle])
Now you can drag X onto columns, Y onto rows, and put Country on detail:
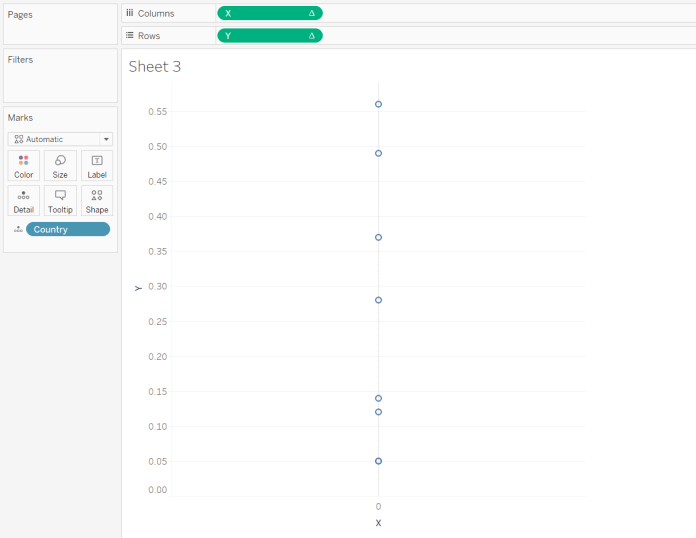
This looks pretty rubbish, but that’s because the INDEX() function in the Radial Angle calculation is a table calc, and Tableau needs to know how to compute it. Edit the X and Y fields to compute using Country instead:
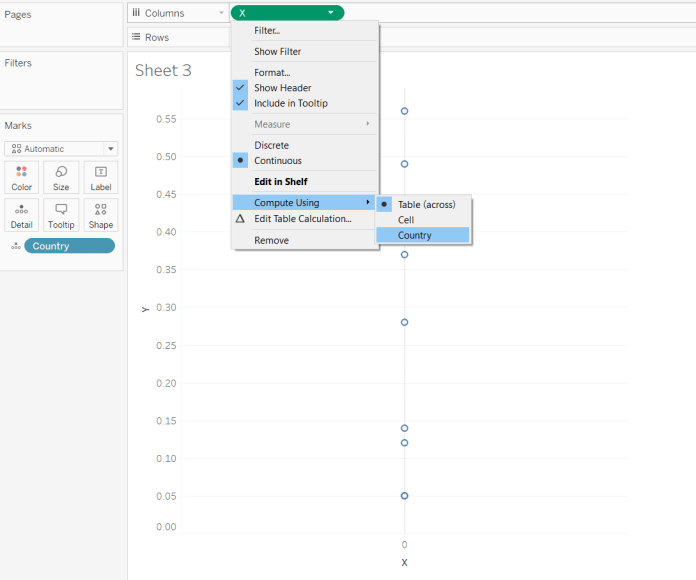
…and now you’ll get some points spaced out properly:

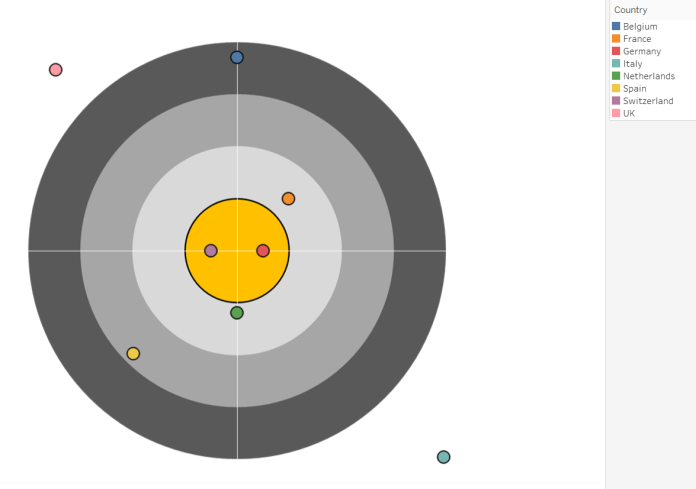
The calculations mean you can plot the points in a radial way; it’ll go through whatever field you’ve put on detail, and plot the points the right distance away from the centre, starting at 12 o’clock and looping round clockwise. With Country, it’s done alphabetically, so Belgium is on the X axis zero line. If you want to order the points differently, you can add a numeric field to the detail shelf, and change the table calculation to compute using that numeric field (but make sure to keep Country there!).
The next thing to do is to put the target in as a background image. Confusingly, this is under the Map options. Once you’ve found it, you have to specify exactly where the background image is going to sit on the x-y grid of coördinates. With this target, there are four concentric circles, denoting 70%, 80%, 90%, and 100%+. Because I set the Radial Field to be 1.1 – [Accuracy], there’s a distance of 0.1 in a circle around point (0,0) and the edge of the bullseye denoting 100%. That means that the bullseye section is going to run from -0.1 to 0.1 on both axes. Counting backwards, there are three other circles which are the same thickness; the light grey one denoting 90% will run from -0.2 to 0.2 on both axes, the mid grey one denoting 80% will run from -0.3 to 0.3 on both axes, and the dark grey one denoting 70% will run from -0.4 to 0.4 on both axes. As the edge of the dark grey circle is the edge of the background image, this is where you need to tell Tableau to position the background image:

Click OK, and there we are! A nice target, with the different points on it:

You can change the formatting to remove the zero lines if you like:

…but I actually kinda like them on this graph. I’ve also put Country on the colour shelf, and made the borders around the circles black.
I haven’t seen this approach before, so I’m not really sure what to call it. I’ve plumped for a bullseye graph, but maybe it already exists under another name. Let me know if somebody else has covered this, and definitely let me know if you find this useful! You can download the Tableau workbook I used to make this example here (it’s 10.2, by the way, but the same approach should work for older versions).























{kind=link}