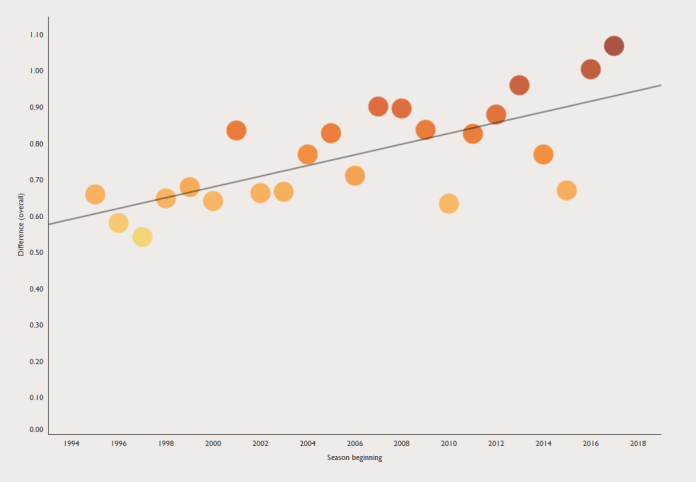
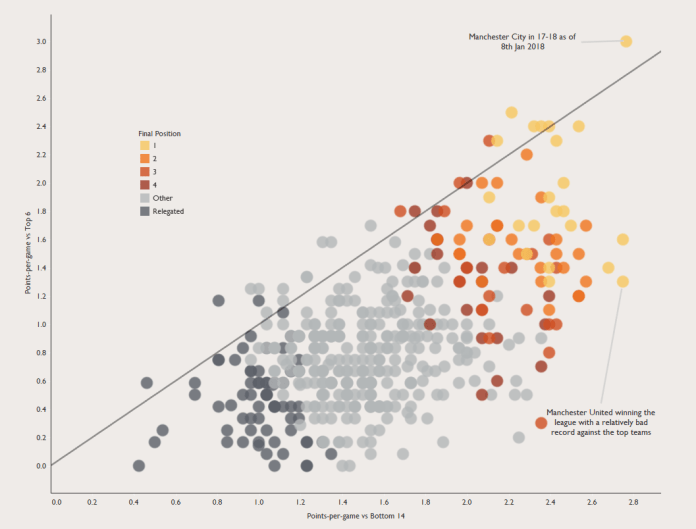
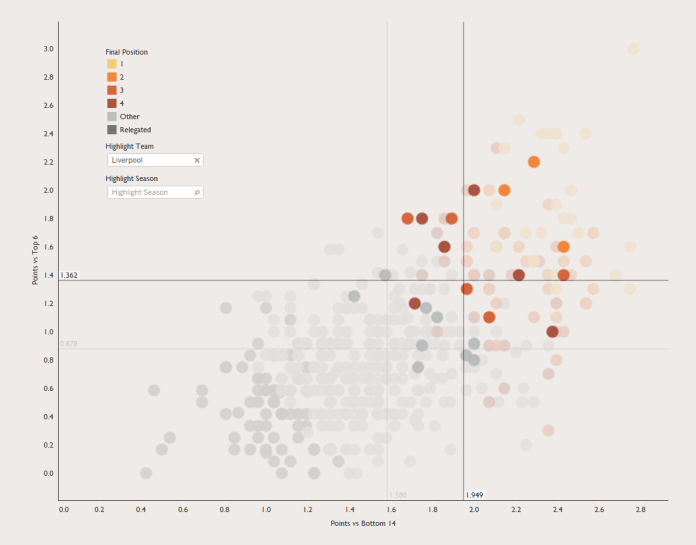
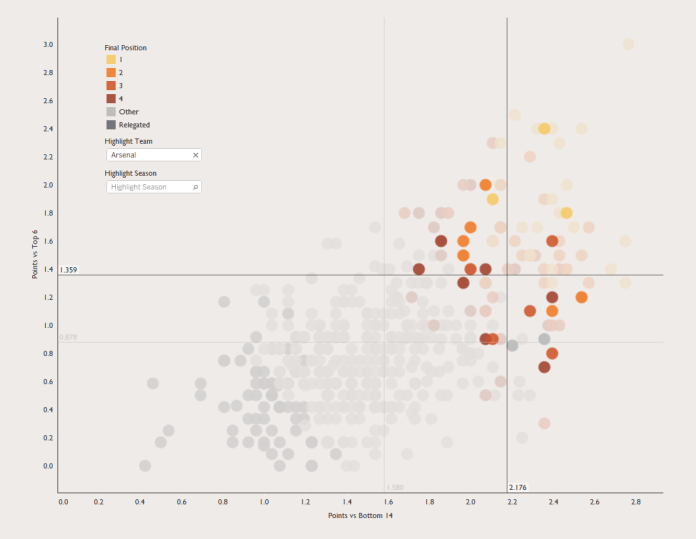
Every time a new Premier League season starts, somebody, probably a manager for a newly-promoted side, says they’ll only relax once they’ve hit the magical 40-point mark. Claudio Ranieri famously kept banging on about aiming for 40 points and Premier League safety throughout the season when Leicester won it.
The problem with the magical 40-point truism is that it’s not really true. There are a fair few examples out there of how you’re probably safe in the Premier League with 36 or 37 points, as well as the reminder that you can still get relegated with 42 points (West Ham in 2003, which will never not be funny to this Charlton fan).
But the problem with the debunking articles is that they’re also not that accurate. They show maybe 20 seasons of data, showing the number of points the teams in 17th (safe) and 18th (relegated) got. And the frustrating and beautiful thing about football is that it’s full of variance.
Here’s an example league table I’ve generated:
(click any graph to follow through to the interactive version)

The thing is, all of these teams are the exact same strength. In this incredibly basic simulation of a twenty-team football league, for each of the 380 games there was an equal chance of it being a win, loss, or draw. So, Inter Random finished bottom with 33 points, and Random Albion won it with 63 points, but those two teams were perfectly equal throughout the season. It just so happened that it wasn’t Inter Random’s season.
Here’s another table:

This is also from the same set of simulations. Inter Random did pretty well this time, finishing 6th with 55 points, while last year’s champions Random Albion finished 19th with 37 points and got relegated. Why are they so bad this season? What happened to them? Nothing happened. Just a different roll of the die.
Let’s do this 10,000 times and look at the breakdown of points won by teams finishing in each position.

That’s a lot of variance! All of these teams are equal, and every single game had a 33.3% chance of the home team winning it, 33.3% chance of a draw, and 33.3% of the away team winning it. You’d think that this would balance out over the course of a season, but it doesn’t. A team can win the league with as many as 85 points (Random Athletic in simulation number 4349), a team can win the league with only 55 points (also Random Athletic, in simulation number 9384), a team can finish bottom with as many as 45 points (Real Random x2, Sporting Random, Random Argyle), and a team can finish bottom with only 18 points (Dynamo Random, Random United).
And if this is the amount of variance you can get between seasons when everything is equal, what happens when it’s not? Did West Ham get a particularly unlucky roll of the die when they finished 18th with 42 points, and that 36 points is going to see you to safety most of the time? Or is it that the last twenty or so seasons have been at the low end of the variance, and that in any given season, 36 points is still probably going to get you relegated? And is there even a points total where you’re definitely absolutely guaranteed not to get relegated?
On that last point, it’s technically possible to get relegated with 63 points. If two teams are completely useless and lose every single game, and the other 18 teams win every home game and lose every away game apart from the two games away to the bottom two, that means that 18 teams finish on 63 points (57 points from winning all home games, 6 points from winning two away games). One team could finish 18th on goal difference. So, really, 64 points is the real magic safety number.
But this would never realistically happen. So, I’ve also run 10,000 simulations of leagues based on real data. I took every single game from the last four years (2014/15 to 2018/19) of the big five leagues (England, Spain, France, Italy, Germany). Assuming that a team’s actual points total is a relatively good measure of a team’s actual strength – which it isn’t, as shown above, but it’s about as close as I can get – I drew random samples of 20 values for each simulation. Since Italy and Germany only have 18 teams in their top flights, I used each team’s average points per game (PPG) as their underlying team strength. This generated 10,000 realistic leagues of 20 teams of different strengths. I then grouped them into strength tiles of 0.3 points per game – the teams in the weakest tile were between 0.3 and 0.6 PPG, the teams in the strongest tile were between 2.4 and 2.7 PPG. I then compared the frequency of teams in each strength tile scoring a certain number of goals against teams in each strength tile, and sampled from those distributions for each of the 3,800,000 games in the simulations. I experimented with making the tiles smaller, but that meant that there were too few examples of games between teams of particular tiles. I also added a home vs. away boost factor.
This ended up coming out pretty realistic. For example, here’s the average number of goals that teams in each strength tile score and concede:

So, what are the points distributions per position in a more realistic simulation?
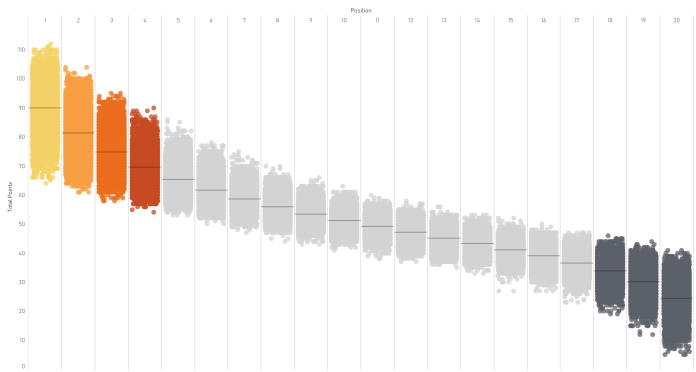
This looks pleasingly similar to the distributions in my graph of Premier League points by position. Most simulation results cluster around the middle of each band (the black line denotes the average). But at the extreme end, you can win the league with 112 points if you’re already a strong team and you outperform / get lucky, like Sporting Random did here:

…and you can also win the league with as little as 64 points if you outperform / get lucky and if the rest of the league underperform / get unlucky, like Real Random did here:

At the bottom of the table, you can get relegated in 18th with 46 points, which is what happened to Random United, a solid midtable team who had a pretty average season… except that everybody else at the bottom of the table completely outperformed expectations / got incredibly lucky:

This chart shows the overlap between the relegation positions and safety. There are some interesting data points at the extreme ends, but the main point is that there are a lot of simulations where a team got 33 points or fewer but finished 17th, and there are several simulations where a team got 38 points or more but still finished 18th:
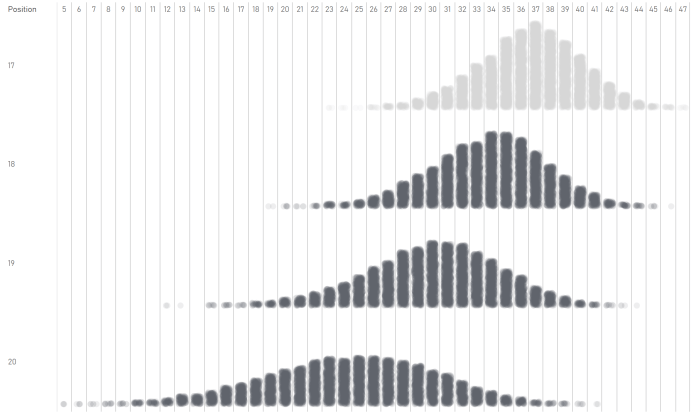
To put it another way, 93% of teams getting 40 points didn’t get relegated:

You can explore the full interaction between points and position in this graph, where you can set a threshold. Here, this shows how often a team finishes in a particular position when getting at least 40 points – so in 5.85% of simulations, you can get 40+ points, but still finish 18th:

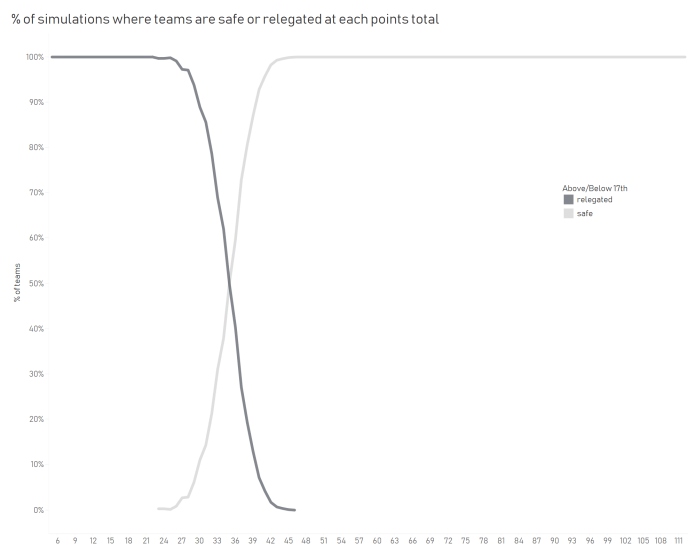
And to work out what your safety threshold is, this graph shows how many teams end up safe or relegated based on their points total. 35 is the turning point; 50.27% of teams getting 35 points end up safe:
As a final view, here’s a breakdown of the variance in positions by each team strength tile. It shows how you can be an incredibly strong team and expect to get 2.4 to 2.7 points per game, and you’ll win the league 63% of the time, but also miss out on the top four entirely a little under 1% of the time:

Forty points isn’t a magic number – you’re safe around 93% of the time if you get 40 points, but it’s not guaranteed.